mirror of
https://github.com/openfaas/faas.git
synced 2025-06-08 08:25:03 +00:00
Delete the classic watchdog
This component now lives at: https://github.com/openfaas/classic-watchdog/ Signed-off-by: Alex Ellis (OpenFaaS Ltd) <alexellis2@gmail.com>
This commit is contained in:
parent
7b6cc60bd9
commit
579b9124e4
2
.gitignore
vendored
2
.gitignore
vendored
@ -1,5 +1,3 @@
|
||||
fwatchdog
|
||||
fwatchdog-armhf
|
||||
**/node_modules/
|
||||
**/*.DS_Store
|
||||
.vscode
|
||||
|
||||
31
.travis.yml
31
.travis.yml
@ -30,41 +30,10 @@ after_success:
|
||||
./ci/registryLogin.sh $REGISTRY;
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/gateway";
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/basic-auth-plugin";
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/classic-watchdog" armhf;
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/classic-watchdog" arm64;
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/classic-watchdog" windows;
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/classic-watchdog" x86_64;
|
||||
|
||||
./watchdog/make_manifest.sh
|
||||
docker push $DOCKER_NS/classic-watchdog:$TRAVIS_TAG
|
||||
|
||||
export REGISTRY=quay.io;
|
||||
./ci/registryLogin.sh $REGISTRY;
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/gateway";
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/basic-auth-plugin";
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/classic-watchdog" armhf;
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/classic-watchdog" arm64;
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/classic-watchdog" windows;
|
||||
./ci/tagAndPush.sh "$REGISTRY" "$DOCKER_NS/classic-watchdog" x86_64;
|
||||
|
||||
fi
|
||||
|
||||
before_deploy:
|
||||
- ./ci/hashgen.sh
|
||||
|
||||
deploy:
|
||||
provider: releases
|
||||
api_key:
|
||||
secure: "SVwbfJO008Z4TCcGPyjIPsOUcN+W9k8Pi4CFRFznskCd+qXbZd/so72ZdBSDUhR/s1U1+NrrVq43fW18aOI6YdPJgSOU1dJyR+EX5833U+B5yIosjEd0PiU9zcby8BB2k/RIEXgu/qWg7DzeZB50Jd8YOJqW5j8qX9qdl5GI09+8siGCUgoiXRquv/VC2Ucdh+V/+Twlm0ytC9IcvIuww5dhJQUsKGLfNRcykioG/RWnqNoJZ5afZ0s/FgOEO4fVmklMRQq5+07Jnub1HW308lvXiO7Utre4c8n8mOTjHxaNbroHggsdq/8KyPIHLukqc1t0iY7GdutangbY14YVcykZ3XcoCfT660Rtz/RfxEiVsrJ8rdjCLIKypw2wAKM1ZH+i6vdYVm+RAoMO83Qsxbfd+NFaS2UMSU+woPHWJ28oeeoPx0Vt3h2K+J6fWMVg5CBb7cN0TMcSFTZpJSgudnGj1k8P4hTms6Ey+gOolBqcJhwcrAvAVfpNcdiPPDkH2N7ME57Dolr80eAr09fpoaIffHFj71syItEAjBC60X30HzUsf+lyGh8gG9R2yAjMSLksrzSyvta6vWlVBNenxpIJdXi6E/JYCamQule4eNajjNU3Yeyzhy4OD4KTAXvadmvsmRaFS7HOS8kBMWEwLHUw61TyG2+1crveYqhJHOs="
|
||||
file:
|
||||
- ./watchdog/fwatchdog
|
||||
- ./watchdog/fwatchdog-armhf
|
||||
- ./watchdog/fwatchdog-arm64
|
||||
- ./watchdog/fwatchdog.exe
|
||||
- ./watchdog/fwatchdog.sha256
|
||||
- ./watchdog/fwatchdog-armhf.sha256
|
||||
- ./watchdog/fwatchdog-arm64.sha256
|
||||
- ./watchdog/fwatchdog.exe.sha256
|
||||
skip_cleanup: true
|
||||
on:
|
||||
tags: true
|
||||
|
||||
@ -168,7 +168,6 @@ OpenFaaS users can subscribe to a weekly Community Newsletter called Insiders Up
|
||||
|
||||
### Quickstart
|
||||
|
||||
|
||||

|
||||
|
||||
> Here is a screenshot of the API gateway portal - designed for ease of use with the inception function.
|
||||
|
||||
12
appveyor.yml
12
appveyor.yml
@ -1,12 +0,0 @@
|
||||
version: 1.0.{build}
|
||||
image: Visual Studio 2017
|
||||
|
||||
install:
|
||||
- docker version
|
||||
|
||||
build_script:
|
||||
- ps: .\watchdog\build.ps1
|
||||
|
||||
artifacts:
|
||||
- path: watchdog\watchdog.exe
|
||||
name: watchdog
|
||||
1
build.sh
1
build.sh
@ -6,5 +6,4 @@ if [ ! -s "$TRAVIS_TAG" ] ; then
|
||||
fi
|
||||
|
||||
(cd gateway && ./build.sh)
|
||||
(cd watchdog && ./build.sh)
|
||||
(cd auth/basic-auth && ./build.sh)
|
||||
@ -1,4 +0,0 @@
|
||||
#!/bin/sh
|
||||
cd ./watchdog
|
||||
for f in fwatchdog*; do shasum -a 256 $f > $f.sha256; done
|
||||
cd ..
|
||||
6
watchdog/.gitignore
vendored
6
watchdog/.gitignore
vendored
@ -1,6 +0,0 @@
|
||||
fwatchdog
|
||||
watchdog
|
||||
fwatchdog-armhf
|
||||
fwatchdog.exe
|
||||
watchdog.exe
|
||||
fwatchdog-arm64
|
||||
@ -1,42 +0,0 @@
|
||||
FROM golang:1.13 as build
|
||||
|
||||
ENV GO111MODULE=off
|
||||
ENV CGO_ENABLED=0
|
||||
|
||||
ARG VERSION
|
||||
ARG GIT_COMMIT
|
||||
|
||||
RUN mkdir -p /go/src/github.com/openfaas/faas/watchdog
|
||||
WORKDIR /go/src/github.com/openfaas/faas/watchdog
|
||||
|
||||
COPY vendor vendor
|
||||
COPY metrics metrics
|
||||
COPY types types
|
||||
COPY main.go .
|
||||
COPY handler.go .
|
||||
COPY readconfig.go .
|
||||
COPY readconfig_test.go .
|
||||
COPY requesthandler_test.go .
|
||||
COPY version.go .
|
||||
|
||||
# Run a gofmt and exclude all vendored code.
|
||||
RUN test -z "$(gofmt -l $(find . -type f -name '*.go' -not -path "./vendor/*"))"
|
||||
|
||||
RUN go test -v ./...
|
||||
# Stripping via -ldflags "-s -w"
|
||||
RUN CGO_ENABLED=0 GOOS=linux go build -a -ldflags "-s -w \
|
||||
-X main.GitCommit=$GIT_COMMIT \
|
||||
-X main.Version=$VERSION" \
|
||||
-installsuffix cgo -o watchdog . \
|
||||
&& GOARM=7 GOARCH=arm CGO_ENABLED=0 GOOS=linux go build -a -ldflags "-s -w \
|
||||
-X main.GitCommit=$GIT_COMMIT \
|
||||
-X main.Version=$VERSION" \
|
||||
-installsuffix cgo -o watchdog-armhf . \
|
||||
&& GOARCH=arm64 CGO_ENABLED=0 GOOS=linux go build -a -ldflags "-s -w \
|
||||
-X main.GitCommit=$GIT_COMMIT \
|
||||
-X main.Version=$VERSION" \
|
||||
-installsuffix cgo -o watchdog-arm64 . \
|
||||
&& GOOS=windows CGO_ENABLED=0 go build -a -ldflags "-s -w \
|
||||
-X main.GitCommit=$GIT_COMMIT \
|
||||
-X main.Version=$VERSION" \
|
||||
-installsuffix cgo -o watchdog.exe .
|
||||
@ -1,6 +0,0 @@
|
||||
FROM openfaas/watchdog:build as build
|
||||
FROM scratch
|
||||
|
||||
ARG PLATFORM
|
||||
|
||||
COPY --from=build /go/src/github.com/openfaas/faas/watchdog/watchdog$PLATFORM ./fwatchdog
|
||||
87
watchdog/Gopkg.lock
generated
87
watchdog/Gopkg.lock
generated
@ -1,87 +0,0 @@
|
||||
# This file is autogenerated, do not edit; changes may be undone by the next 'dep ensure'.
|
||||
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:d6afaeed1502aa28e80a4ed0981d570ad91b2579193404256ce672ed0a609e0d"
|
||||
name = "github.com/beorn7/perks"
|
||||
packages = ["quantile"]
|
||||
pruneopts = "UT"
|
||||
revision = "3a771d992973f24aa725d07868b467d1ddfceafb"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:318f1c959a8a740366fce4b1e1eb2fd914036b4af58fbd0a003349b305f118ad"
|
||||
name = "github.com/golang/protobuf"
|
||||
packages = ["proto"]
|
||||
pruneopts = "UT"
|
||||
revision = "b5d812f8a3706043e23a9cd5babf2e5423744d30"
|
||||
version = "v1.3.1"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:ff5ebae34cfbf047d505ee150de27e60570e8c394b3b8fdbb720ff6ac71985fc"
|
||||
name = "github.com/matttproud/golang_protobuf_extensions"
|
||||
packages = ["pbutil"]
|
||||
pruneopts = "UT"
|
||||
revision = "c12348ce28de40eed0136aa2b644d0ee0650e56c"
|
||||
version = "v1.0.1"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:cc8e0046e1076991a51c3aa9ab4827b8bf1bf4d7715cd45a95888663c2d851e3"
|
||||
name = "github.com/openfaas/faas-middleware"
|
||||
packages = ["concurrency-limiter"]
|
||||
pruneopts = "UT"
|
||||
revision = "6a78c3a94beb2a99d6aa443bca21331653840a23"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:ef03fb1dae4d010196652653f00a8002e94c19bcabdc8ca5100a804ffef63a47"
|
||||
name = "github.com/prometheus/client_golang"
|
||||
packages = [
|
||||
"prometheus",
|
||||
"prometheus/internal",
|
||||
"prometheus/promauto",
|
||||
"prometheus/promhttp",
|
||||
]
|
||||
pruneopts = "UT"
|
||||
revision = "505eaef017263e299324067d40ca2c48f6a2cf50"
|
||||
version = "v0.9.2"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:2d5cd61daa5565187e1d96bae64dbbc6080dacf741448e9629c64fd93203b0d4"
|
||||
name = "github.com/prometheus/client_model"
|
||||
packages = ["go"]
|
||||
pruneopts = "UT"
|
||||
revision = "fd36f4220a901265f90734c3183c5f0c91daa0b8"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:35cf6bdf68db765988baa9c4f10cc5d7dda1126a54bd62e252dbcd0b1fc8da90"
|
||||
name = "github.com/prometheus/common"
|
||||
packages = [
|
||||
"expfmt",
|
||||
"internal/bitbucket.org/ww/goautoneg",
|
||||
"model",
|
||||
]
|
||||
pruneopts = "UT"
|
||||
revision = "cfeb6f9992ffa54aaa4f2170ade4067ee478b250"
|
||||
version = "v0.2.0"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:f806b417865e83457c3659232926203f5b0d39aa741b71d9e3e4c0c774e71a5c"
|
||||
name = "github.com/prometheus/procfs"
|
||||
packages = ["."]
|
||||
pruneopts = "UT"
|
||||
revision = "ea9eea63887261e4d8ed8315f4078e88d540c725"
|
||||
|
||||
[solve-meta]
|
||||
analyzer-name = "dep"
|
||||
analyzer-version = 1
|
||||
input-imports = [
|
||||
"github.com/openfaas/faas-middleware/concurrency-limiter",
|
||||
"github.com/prometheus/client_golang/prometheus",
|
||||
"github.com/prometheus/client_golang/prometheus/promauto",
|
||||
"github.com/prometheus/client_golang/prometheus/promhttp",
|
||||
]
|
||||
solver-name = "gps-cdcl"
|
||||
solver-version = 1
|
||||
@ -1,34 +0,0 @@
|
||||
# Gopkg.toml example
|
||||
#
|
||||
# Refer to https://golang.github.io/dep/docs/Gopkg.toml.html
|
||||
# for detailed Gopkg.toml documentation.
|
||||
#
|
||||
# required = ["github.com/user/thing/cmd/thing"]
|
||||
# ignored = ["github.com/user/project/pkgX", "bitbucket.org/user/project/pkgA/pkgY"]
|
||||
#
|
||||
# [[constraint]]
|
||||
# name = "github.com/user/project"
|
||||
# version = "1.0.0"
|
||||
#
|
||||
# [[constraint]]
|
||||
# name = "github.com/user/project2"
|
||||
# branch = "dev"
|
||||
# source = "github.com/myfork/project2"
|
||||
#
|
||||
# [[override]]
|
||||
# name = "github.com/x/y"
|
||||
# version = "2.4.0"
|
||||
#
|
||||
# [prune]
|
||||
# non-go = false
|
||||
# go-tests = true
|
||||
# unused-packages = true
|
||||
|
||||
|
||||
[[constraint]]
|
||||
name = "github.com/prometheus/client_golang"
|
||||
version = "0.9.2"
|
||||
|
||||
[prune]
|
||||
go-tests = true
|
||||
unused-packages = true
|
||||
@ -1,2 +0,0 @@
|
||||
linux:
|
||||
CGO_ENABLED=0 GOOS=linux go build -a -ldflags "-s -w" -installsuffix cgo -o fwatchdog
|
||||
@ -1,232 +0,0 @@
|
||||
Watchdog
|
||||
==========
|
||||
|
||||
The watchdog provides an unmanaged and generic interface between the outside world and your function. Its job is to marshal a HTTP request accepted on the API Gateway and to invoke your chosen application. The watchdog is a tiny Golang webserver - see the diagram below for how this process works.
|
||||
|
||||
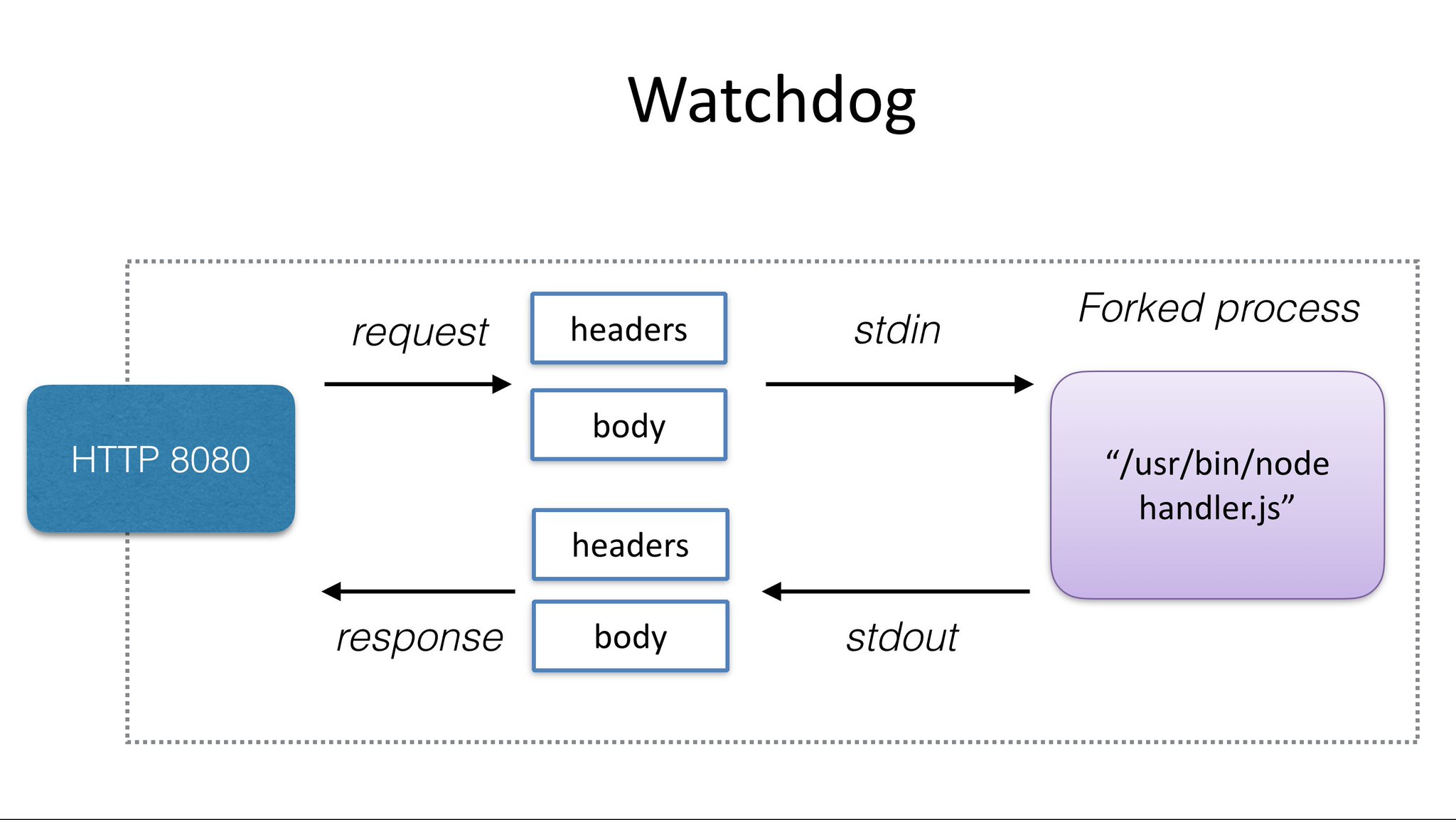
|
||||
|
||||
> Above: a tiny web-server or shim that forks your desired process for every incoming HTTP request
|
||||
|
||||
Every function needs to embed this binary and use it as its `ENTRYPOINT` or `CMD`, in effect it is the init process for your container. Once your process is forked the watchdog passses in the HTTP request via `stdin` and reads a HTTP response via `stdout`. This means your process does not need to know anything about the web or HTTP.
|
||||
|
||||
### Next-gen: of-watchdog
|
||||
|
||||
Are you looking for more control over your HTTP responses, "hot functions", persistent connection pools or to cache a machine-learning model in memory? Then check out the *http mode* of the new [of-watchdog](https://github.com/openfaas-incubator/of-watchdog).
|
||||
|
||||
## Create a new function the easy way
|
||||
|
||||
**Create a function via the CLI**
|
||||
|
||||
The easiest way to create a function is to use a template and the FaaS CLI. The CLI allows you to abstract all Docker knowledge away, you just have to write a handler file in one of the supported programming languages.
|
||||
|
||||
* [Your first serverless Python function with OpenFaaS](https://blog.alexellis.io/first-faas-python-function/)
|
||||
|
||||
* [Read a tutorial on the FaaS CLI](https://github.com/openfaas/faas-cli)
|
||||
|
||||
## Delve deeper
|
||||
|
||||
**Package your function**
|
||||
|
||||
Here's how to package your function if you don't want to use the CLI or have existing binaries or images:
|
||||
|
||||
- [x] Use an existing or a new Docker image as base image `FROM`
|
||||
- [x] Add the fwatchdog binary from the [Releases page](https://github.com/openfaas/faas/releases) via `curl` or `ADD https://`
|
||||
- [x] Set an `fprocess` (function process) environmental variable with the function you want to run for each request
|
||||
- [x] Expose port 8080
|
||||
- [x] Set the `CMD` to `fwatchdog`
|
||||
|
||||
Example Dockerfile for an `echo` function:
|
||||
|
||||
```
|
||||
FROM alpine:3.11
|
||||
|
||||
ADD https://github.com/openfaas/faas/releases/download/0.18.10/fwatchdog /usr/bin
|
||||
RUN chmod +x /usr/bin/fwatchdog
|
||||
|
||||
# Define your binary here
|
||||
ENV fprocess="/bin/cat"
|
||||
|
||||
CMD ["fwatchdog"]
|
||||
```
|
||||
|
||||
**Tip:**
|
||||
You can optimize Docker to cache getting the watchdog by using curl, instead of ADD.
|
||||
To do so, replace the related lines with:
|
||||
```
|
||||
RUN apk --no-cache add curl \
|
||||
&& curl -sL https://github.com/openfaas/faas/releases/download/0.9.14/fwatchdog > /usr/bin/fwatchdog \
|
||||
&& chmod +x /usr/bin/fwatchdog
|
||||
```
|
||||
|
||||
**Implementing a health-check**
|
||||
|
||||
At any point in time, if you detect that your function has become unhealthy and needs to restart, then you can delete the `/tmp/.lock` file which invalidates the check and causes Swarm to re-schedule the function.
|
||||
|
||||
* Kubernetes
|
||||
|
||||
For Kubernetes the health check is added through automation without you needing to alter the `Dockerfile`.
|
||||
|
||||
* Swarm
|
||||
|
||||
A Docker Swarm Healthcheck is required and is best practice. It will make sure that the watchdog is ready to accept a request before forwarding requests via the API Gateway. If the function or watchdog runs into an unrecoverable issue Swarm will also be able to restart the container.
|
||||
|
||||
Here is an example of the `echo` function implementing a *health check* with a 5-second checking interval.
|
||||
|
||||
```
|
||||
FROM functions/alpine
|
||||
|
||||
ENV fprocess="cat /etc/hostname"
|
||||
|
||||
HEALTHCHECK --interval=5s CMD [ -e /tmp/.lock ] || exit 1
|
||||
```
|
||||
|
||||
The watchdog process creates a .lock file in `/tmp/` on starting its internal Golang HTTP server. `[ -e file_name ]` is shell to check if a file exists. With Windows Containers this is an invalid path so you may want to set the `suppress_lock` environmental variable.
|
||||
|
||||
Read my Docker Swarm tutorial on Healthchecks:
|
||||
|
||||
* [Test-drive Docker Healthcheck in 10 minutes](http://blog.alexellis.io/test-drive-healthcheck/)
|
||||
|
||||
**Environmental overrides:**
|
||||
|
||||
The watchdog can be configured through environmental variables. You must always specifiy an `fprocess` variable.
|
||||
|
||||
| Option | Usage |
|
||||
|------------------------|--------------|
|
||||
| `fprocess` | The process to invoke for each function call (function process). This must be a UNIX binary and accept input via STDIN and output via STDOUT |
|
||||
| `cgi_headers` | HTTP headers from request are made available through environmental variables - `Http_X_Served_By` etc. See section: *Handling headers* for more detail. Enabled by default |
|
||||
| `marshal_request` | Instead of re-directing the raw HTTP body into your fprocess, it will first be marshalled into JSON. Use this if you need to work with HTTP headers and do not want to use environmental variables via the `cgi_headers` flag. |
|
||||
| `content_type` | Force a specific Content-Type response for all responses |
|
||||
| `write_timeout` | HTTP timeout for writing a response body from your function (in seconds) |
|
||||
| `read_timeout` | HTTP timeout for reading the payload from the client caller (in seconds) |
|
||||
| `suppress_lock` | The watchdog will attempt to write a lockfile to /tmp/ for swarm healthchecks - set this to true to disable behaviour. |
|
||||
| `exec_timeout` | Hard timeout for process exec'd for each incoming request (in seconds). Disabled if set to 0 |
|
||||
| `write_debug` | Write all output, error messages, and additional information to the logs. Default is false |
|
||||
| `combine_output` | True by default - combines stdout/stderr in function response, when set to false `stderr` is written to the container logs and stdout is used for function response |
|
||||
| `max_inflight` | Limit the maximum number of requests in flight |
|
||||
|
||||
## Advanced / tuning
|
||||
|
||||
### (New) of-watchdog and HTTP mode
|
||||
|
||||
* of-watchdog
|
||||
|
||||
Forking a new process per request has advantages such as process isolation, portability and simplicity. Any process can be made into a function without any additional code. The of-watchdog and its "HTTP" mode is an optimization which maintains one single process between all requests.
|
||||
|
||||
A new version of the watchdog is being tested over at [openfaas-incubator/of-watchdog](https://github.com/openfaas-incubator/of-watchdog).
|
||||
|
||||
This re-write is mainly structural for on-going maintenance. It will be a drop-in replacement for the existing watchdog and also has binary releases available.
|
||||
|
||||
### Graceful shutdowns
|
||||
|
||||
The watchdog is capable of working with health-checks to provide a graceful shutdown.
|
||||
|
||||
When a `SIGTERM` signal is detected within the watchdog process a Go routine will remove the `/tmp/.lock` file and mark the HTTP health-check as unhealthy and return HTTP 503. The code will then wait for the duration specified in `write_timeout`. During this window the container-orchestrator's health-check must run and complete.
|
||||
|
||||
Now the orchestrator will mark this replica as unhealthy and remove it from the pool of valid HTTP endpoints.
|
||||
|
||||
Now we will stop accepting new connections and wait for the value defined in `write_timeout` before finally allowing the process to exit.
|
||||
|
||||
### Working with HTTP headers
|
||||
|
||||
Headers and other request information are injected into environmental variables in the following format:
|
||||
|
||||
The `X-Forwarded-By` header becomes available as `Http_X_Forwarded_By`
|
||||
|
||||
* `Http_Method` - GET/POST etc
|
||||
* `Http_Query` - QueryString value
|
||||
* `Http_ContentLength` and `Http_Content_Length` - gives the total content-length of the incoming HTTP request received by the watchdog, see note below
|
||||
* `Http_Transfer_Encoding` - only set when provided, if set to `chunked` the Content-Length will be `-1` to show that it does not apply
|
||||
|
||||
> This behaviour is enabled by the `cgi_headers` environmental variable which is enabled (`true`) by default.
|
||||
|
||||
Here's an example of a POST request with an additional header and a query-string.
|
||||
|
||||
```
|
||||
$ cgi_headers=true fprocess=env ./watchdog &
|
||||
2017/06/23 17:02:58 Writing lock-file to: /tmp/.lock
|
||||
|
||||
$ curl "localhost:8080?q=serverless&page=1" -X POST -H X-Forwarded-By:http://my.vpn.com
|
||||
```
|
||||
|
||||
This is what you'd see if you had set your `fprocess` to `env` on a Linux system:
|
||||
|
||||
```
|
||||
Http_User_Agent=curl/7.43.0
|
||||
Http_Accept=*/*
|
||||
Http_X_Forwarded_By=http://my.vpn.com
|
||||
Http_Method=POST
|
||||
Http_Query=q=serverless&page=1
|
||||
```
|
||||
|
||||
You can also use the `GET` verb:
|
||||
|
||||
```
|
||||
$ curl "localhost:8080?action=quote&qty=1&productId=105"
|
||||
```
|
||||
|
||||
The output from the watchdog would be:
|
||||
|
||||
```
|
||||
Http_User_Agent=curl/7.43.0
|
||||
Http_Accept=*/*
|
||||
Http_Method=GET
|
||||
Http_Query=action=quote&qty=1&productId=105
|
||||
```
|
||||
|
||||
You can now use HTTP state from within your application to make decisions.
|
||||
|
||||
### HTTP methods
|
||||
|
||||
The HTTP methods supported for the watchdog are:
|
||||
|
||||
With a body:
|
||||
* POST, PUT, DELETE, UPDATE
|
||||
|
||||
Without a body:
|
||||
* GET
|
||||
|
||||
> The API Gateway currently supports the POST route for functions.
|
||||
|
||||
### Content-Type of request/response
|
||||
|
||||
By default the watchdog will match the response of your function to the "Content-Type" of the client.
|
||||
|
||||
* If your client sends a JSON post with a Content-Type of `application/json` this will be matched automatically in the response.
|
||||
* If your client sends a JSON post with a Content-Type of `text/plain` this will be matched automatically in the response too
|
||||
|
||||
To override the Content-Type of all your responses set the `content_type` environmental variable.
|
||||
|
||||
### I don't want to use the watchdog
|
||||
|
||||
This is an unsupported use-case for the OpenFaaS project however if your container conforms to the requirements below then the OpenFaaS API gateway and other tooling will manage and scale your service.
|
||||
|
||||
You will need to provide a lock-file at `/tmp/.lock` so that the orchestration system can run *health checks* against your container. If you are using Docker Swarm make sure you provide a `HEALTHCHECK` instruction in your Dockerfile - samples are given in the `faas` repository.
|
||||
|
||||
* Expose TCP port 8080 over HTTP
|
||||
* Create `/tmp/.lock` or in whatever location responds to the OS tempdir syscall
|
||||
|
||||
### Tuning auto-scaling
|
||||
|
||||
Auto-scaling starts at 1 replica and steps up in blocks of 5:
|
||||
|
||||
* 1->5
|
||||
* 5->10
|
||||
* 10->15
|
||||
* 15->20
|
||||
|
||||
You can override the minimum and maximum scale of a function through labels.
|
||||
|
||||
Add these labels to the deployment if you want to scale between 2 and 15 replicas.
|
||||
|
||||
```
|
||||
com.openfaas.scale.min: "2"
|
||||
com.openfaas.scale.max: "15"
|
||||
```
|
||||
|
||||
The labels are optional.
|
||||
|
||||
**Disabling auto-scaling**
|
||||
|
||||
If you want to disable auto-scaling for a function then set the minimum and maximum scale to the same value i.e. "1".
|
||||
|
||||
As an alternative you can also remove AlertManager or scale it to 0 replicas.
|
||||
@ -1,10 +0,0 @@
|
||||
cd watchdog
|
||||
|
||||
del watchdog.exe
|
||||
|
||||
docker build -t alexellis2/watchdog:windows . -f .\Dockerfile.win
|
||||
|
||||
docker create --name watchdog alexellis2/watchdog:windows cmd
|
||||
|
||||
& docker cp watchdog:/go/src/github.com/openfaas/faas/watchdog/watchdog.exe .
|
||||
docker rm -f watchdog
|
||||
@ -1,38 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -e
|
||||
|
||||
export arch=$(uname -m)
|
||||
|
||||
if [ "$arch" = "armv7l" ] ; then
|
||||
echo "Build not supported on $arch, use cross-build."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
cd ..
|
||||
GIT_COMMIT=$(git rev-list -1 HEAD)
|
||||
VERSION=$(git describe --all --exact-match `git rev-parse HEAD` | grep tags | sed 's/tags\///')
|
||||
cd watchdog
|
||||
|
||||
if [ ! $http_proxy == "" ]
|
||||
then
|
||||
docker build --no-cache --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy \
|
||||
--build-arg GIT_COMMIT=$GIT_COMMIT --build-arg VERSION=$VERSION -t openfaas/watchdog:build .
|
||||
else
|
||||
docker build --no-cache --build-arg VERSION=$VERSION --build-arg GIT_COMMIT=$GIT_COMMIT -t openfaas/watchdog:build .
|
||||
fi
|
||||
|
||||
docker build --no-cache --build-arg PLATFORM="-armhf" -t openfaas/classic-watchdog:latest-dev-armhf . -f Dockerfile.packager
|
||||
docker build --no-cache --build-arg PLATFORM="-arm64" -t openfaas/classic-watchdog:latest-dev-arm64 . -f Dockerfile.packager
|
||||
docker build --no-cache --build-arg PLATFORM=".exe" -t openfaas/classic-watchdog:latest-dev-windows . -f Dockerfile.packager
|
||||
docker build --no-cache --build-arg PLATFORM="" -t openfaas/classic-watchdog:latest-dev-x86_64 . -f Dockerfile.packager
|
||||
|
||||
docker create --name buildoutput openfaas/watchdog:build echo
|
||||
|
||||
docker cp buildoutput:/go/src/github.com/openfaas/faas/watchdog/watchdog ./fwatchdog
|
||||
docker cp buildoutput:/go/src/github.com/openfaas/faas/watchdog/watchdog-armhf ./fwatchdog-armhf
|
||||
docker cp buildoutput:/go/src/github.com/openfaas/faas/watchdog/watchdog-arm64 ./fwatchdog-arm64
|
||||
docker cp buildoutput:/go/src/github.com/openfaas/faas/watchdog/watchdog.exe ./fwatchdog.exe
|
||||
|
||||
docker rm buildoutput
|
||||
|
||||
@ -1,323 +0,0 @@
|
||||
// Copyright (c) Alex Ellis 2017. All rights reserved.
|
||||
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
|
||||
|
||||
package main
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"fmt"
|
||||
"io/ioutil"
|
||||
"log"
|
||||
"net/http"
|
||||
"os"
|
||||
"os/exec"
|
||||
"path/filepath"
|
||||
"strings"
|
||||
"sync"
|
||||
"sync/atomic"
|
||||
"time"
|
||||
|
||||
limiter "github.com/openfaas/faas-middleware/concurrency-limiter"
|
||||
|
||||
"github.com/openfaas/faas/watchdog/types"
|
||||
)
|
||||
|
||||
type requestInfo struct {
|
||||
headerWritten bool
|
||||
}
|
||||
|
||||
// buildFunctionInput for a GET method this is an empty byte array.
|
||||
func buildFunctionInput(config *WatchdogConfig, r *http.Request) ([]byte, error) {
|
||||
var res []byte
|
||||
var requestBytes []byte
|
||||
var err error
|
||||
|
||||
if r.Body == nil {
|
||||
return res, nil
|
||||
}
|
||||
defer r.Body.Close()
|
||||
|
||||
if err != nil {
|
||||
log.Println(err)
|
||||
return res, err
|
||||
}
|
||||
|
||||
requestBytes, err = ioutil.ReadAll(r.Body)
|
||||
if config.marshalRequest {
|
||||
marshalRes, marshalErr := types.MarshalRequest(requestBytes, &r.Header)
|
||||
err = marshalErr
|
||||
res = marshalRes
|
||||
} else {
|
||||
res = requestBytes
|
||||
}
|
||||
|
||||
return res, err
|
||||
}
|
||||
|
||||
// debugHeaders prints HTTP headers as key/value pairs
|
||||
func debugHeaders(source *http.Header, direction string) {
|
||||
for k, vv := range *source {
|
||||
fmt.Printf("[%s] %s=%s\n", direction, k, vv)
|
||||
}
|
||||
}
|
||||
|
||||
func pipeRequest(config *WatchdogConfig, w http.ResponseWriter, r *http.Request, method string) {
|
||||
startTime := time.Now()
|
||||
|
||||
parts := strings.Split(config.faasProcess, " ")
|
||||
|
||||
ri := &requestInfo{}
|
||||
|
||||
if config.debugHeaders {
|
||||
debugHeaders(&r.Header, "in")
|
||||
}
|
||||
|
||||
log.Println("Forking fprocess.")
|
||||
|
||||
targetCmd := exec.Command(parts[0], parts[1:]...)
|
||||
|
||||
envs := getAdditionalEnvs(config, r, method)
|
||||
if len(envs) > 0 {
|
||||
targetCmd.Env = envs
|
||||
}
|
||||
|
||||
writer, _ := targetCmd.StdinPipe()
|
||||
|
||||
var out []byte
|
||||
var err error
|
||||
var requestBody []byte
|
||||
|
||||
var wg sync.WaitGroup
|
||||
|
||||
wgCount := 2
|
||||
|
||||
var buildInputErr error
|
||||
requestBody, buildInputErr = buildFunctionInput(config, r)
|
||||
if buildInputErr != nil {
|
||||
if config.writeDebug == true {
|
||||
log.Printf("Error=%s, ReadLen=%d\n", buildInputErr.Error(), len(requestBody))
|
||||
}
|
||||
ri.headerWritten = true
|
||||
w.WriteHeader(http.StatusBadRequest)
|
||||
// I.e. "exit code 1"
|
||||
w.Write([]byte(buildInputErr.Error()))
|
||||
|
||||
// Verbose message - i.e. stack trace
|
||||
w.Write([]byte("\n"))
|
||||
w.Write(out)
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
wg.Add(wgCount)
|
||||
|
||||
var timer *time.Timer
|
||||
|
||||
if config.execTimeout > 0*time.Second {
|
||||
timer = time.AfterFunc(config.execTimeout, func() {
|
||||
log.Printf("Killing process: %s\n", config.faasProcess)
|
||||
if targetCmd != nil && targetCmd.Process != nil {
|
||||
ri.headerWritten = true
|
||||
w.WriteHeader(http.StatusRequestTimeout)
|
||||
|
||||
w.Write([]byte("Killed process.\n"))
|
||||
|
||||
val := targetCmd.Process.Kill()
|
||||
if val != nil {
|
||||
log.Printf("Killed process: %s - error %s\n", config.faasProcess, val.Error())
|
||||
}
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
// Write to pipe in separate go-routine to prevent blocking
|
||||
go func() {
|
||||
defer wg.Done()
|
||||
writer.Write(requestBody)
|
||||
writer.Close()
|
||||
}()
|
||||
|
||||
if config.combineOutput {
|
||||
// Read the output from stdout/stderr and combine into one variable for output.
|
||||
go func() {
|
||||
defer wg.Done()
|
||||
|
||||
out, err = targetCmd.CombinedOutput()
|
||||
}()
|
||||
} else {
|
||||
go func() {
|
||||
var b bytes.Buffer
|
||||
targetCmd.Stderr = &b
|
||||
|
||||
defer wg.Done()
|
||||
|
||||
out, err = targetCmd.Output()
|
||||
if b.Len() > 0 {
|
||||
log.Printf("stderr: %s", b.Bytes())
|
||||
}
|
||||
b.Reset()
|
||||
}()
|
||||
}
|
||||
|
||||
wg.Wait()
|
||||
if timer != nil {
|
||||
timer.Stop()
|
||||
}
|
||||
|
||||
if err != nil {
|
||||
if config.writeDebug == true {
|
||||
log.Printf("Success=%t, Error=%s\n", targetCmd.ProcessState.Success(), err.Error())
|
||||
log.Printf("Out=%s\n", out)
|
||||
}
|
||||
|
||||
if ri.headerWritten == false {
|
||||
w.WriteHeader(http.StatusInternalServerError)
|
||||
response := bytes.NewBufferString(err.Error())
|
||||
w.Write(response.Bytes())
|
||||
w.Write([]byte("\n"))
|
||||
if len(out) > 0 {
|
||||
w.Write(out)
|
||||
}
|
||||
ri.headerWritten = true
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
var bytesWritten string
|
||||
if config.writeDebug == true {
|
||||
os.Stdout.Write(out)
|
||||
} else {
|
||||
bytesWritten = fmt.Sprintf("Wrote %d Bytes", len(out))
|
||||
}
|
||||
|
||||
if len(config.contentType) > 0 {
|
||||
w.Header().Set("Content-Type", config.contentType)
|
||||
} else {
|
||||
|
||||
// Match content-type of caller if no override specified.
|
||||
clientContentType := r.Header.Get("Content-Type")
|
||||
if len(clientContentType) > 0 {
|
||||
w.Header().Set("Content-Type", clientContentType)
|
||||
}
|
||||
}
|
||||
|
||||
execDuration := time.Since(startTime).Seconds()
|
||||
if ri.headerWritten == false {
|
||||
w.Header().Set("X-Duration-Seconds", fmt.Sprintf("%f", execDuration))
|
||||
ri.headerWritten = true
|
||||
w.WriteHeader(200)
|
||||
w.Write(out)
|
||||
}
|
||||
|
||||
if config.debugHeaders {
|
||||
header := w.Header()
|
||||
debugHeaders(&header, "out")
|
||||
}
|
||||
|
||||
if len(bytesWritten) > 0 {
|
||||
log.Printf("%s - Duration: %fs", bytesWritten, execDuration)
|
||||
} else {
|
||||
log.Printf("Duration: %fs", execDuration)
|
||||
}
|
||||
}
|
||||
|
||||
func getAdditionalEnvs(config *WatchdogConfig, r *http.Request, method string) []string {
|
||||
var envs []string
|
||||
|
||||
if config.cgiHeaders {
|
||||
envs = os.Environ()
|
||||
|
||||
for k, v := range r.Header {
|
||||
kv := fmt.Sprintf("Http_%s=%s", strings.Replace(k, "-", "_", -1), v[0])
|
||||
envs = append(envs, kv)
|
||||
}
|
||||
|
||||
envs = append(envs, fmt.Sprintf("Http_Method=%s", method))
|
||||
// Deprecation notice: Http_ContentLength will be deprecated
|
||||
envs = append(envs, fmt.Sprintf("Http_ContentLength=%d", r.ContentLength))
|
||||
envs = append(envs, fmt.Sprintf("Http_Content_Length=%d", r.ContentLength))
|
||||
|
||||
if len(r.TransferEncoding) > 0 {
|
||||
envs = append(envs, fmt.Sprintf("Http_Transfer_Encoding=%s", r.TransferEncoding[0]))
|
||||
}
|
||||
|
||||
if config.writeDebug {
|
||||
log.Println("Query ", r.URL.RawQuery)
|
||||
}
|
||||
|
||||
if len(r.URL.RawQuery) > 0 {
|
||||
envs = append(envs, fmt.Sprintf("Http_Query=%s", r.URL.RawQuery))
|
||||
}
|
||||
|
||||
if config.writeDebug {
|
||||
log.Println("Path ", r.URL.Path)
|
||||
}
|
||||
|
||||
if len(r.URL.Path) > 0 {
|
||||
envs = append(envs, fmt.Sprintf("Http_Path=%s", r.URL.Path))
|
||||
}
|
||||
|
||||
if len(r.Host) > 0 {
|
||||
envs = append(envs, fmt.Sprintf("Http_Host=%s", r.Host))
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
return envs
|
||||
}
|
||||
|
||||
func lockFilePresent() bool {
|
||||
path := filepath.Join(os.TempDir(), ".lock")
|
||||
if _, err := os.Stat(path); os.IsNotExist(err) {
|
||||
return false
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
func createLockFile() (string, error) {
|
||||
path := filepath.Join(os.TempDir(), ".lock")
|
||||
log.Printf("Writing lock-file to: %s\n", path)
|
||||
writeErr := ioutil.WriteFile(path, []byte{}, 0660)
|
||||
|
||||
atomic.StoreInt32(&acceptingConnections, 1)
|
||||
|
||||
return path, writeErr
|
||||
}
|
||||
|
||||
func makeHealthHandler() func(http.ResponseWriter, *http.Request) {
|
||||
return func(w http.ResponseWriter, r *http.Request) {
|
||||
switch r.Method {
|
||||
case http.MethodGet:
|
||||
if atomic.LoadInt32(&acceptingConnections) == 0 || lockFilePresent() == false {
|
||||
w.WriteHeader(http.StatusServiceUnavailable)
|
||||
return
|
||||
}
|
||||
|
||||
w.WriteHeader(http.StatusOK)
|
||||
w.Write([]byte("OK"))
|
||||
|
||||
break
|
||||
default:
|
||||
w.WriteHeader(http.StatusMethodNotAllowed)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func makeRequestHandler(config *WatchdogConfig) http.HandlerFunc {
|
||||
handler := http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
switch r.Method {
|
||||
case
|
||||
http.MethodPost,
|
||||
http.MethodPut,
|
||||
http.MethodPatch,
|
||||
http.MethodDelete,
|
||||
http.MethodGet:
|
||||
pipeRequest(config, w, r, r.Method)
|
||||
break
|
||||
default:
|
||||
w.WriteHeader(http.StatusMethodNotAllowed)
|
||||
|
||||
}
|
||||
})
|
||||
return limiter.NewConcurrencyLimiter(handler, config.maxInflight).ServeHTTP
|
||||
}
|
||||
174
watchdog/main.go
174
watchdog/main.go
@ -1,174 +0,0 @@
|
||||
// Copyright (c) Alex Ellis 2017. All rights reserved.
|
||||
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
|
||||
|
||||
// Package main provides the OpenFaaS Classic Watchdog. The Classic Watchdog is a HTTP
|
||||
// shim for serverless functions providing health-checking, graceful shutdowns,
|
||||
// timeouts and a consistent logging experience.
|
||||
package main
|
||||
|
||||
import (
|
||||
"context"
|
||||
"flag"
|
||||
"fmt"
|
||||
"log"
|
||||
"net/http"
|
||||
"os"
|
||||
"os/signal"
|
||||
"path/filepath"
|
||||
"sync/atomic"
|
||||
"syscall"
|
||||
"time"
|
||||
|
||||
"github.com/openfaas/faas/watchdog/metrics"
|
||||
"github.com/openfaas/faas/watchdog/types"
|
||||
)
|
||||
|
||||
var (
|
||||
acceptingConnections int32
|
||||
)
|
||||
|
||||
func main() {
|
||||
var runHealthcheck bool
|
||||
var versionFlag bool
|
||||
|
||||
flag.BoolVar(&versionFlag, "version", false, "Print the version and exit")
|
||||
flag.BoolVar(&runHealthcheck,
|
||||
"run-healthcheck",
|
||||
false,
|
||||
"Check for the a lock-file, when using an exec healthcheck. Exit 0 for present, non-zero when not found.")
|
||||
|
||||
flag.Parse()
|
||||
|
||||
if runHealthcheck {
|
||||
if lockFilePresent() {
|
||||
os.Exit(0)
|
||||
}
|
||||
|
||||
fmt.Fprintf(os.Stderr, "unable to find lock file.\n")
|
||||
os.Exit(1)
|
||||
}
|
||||
|
||||
printVersion()
|
||||
|
||||
if versionFlag {
|
||||
return
|
||||
}
|
||||
|
||||
atomic.StoreInt32(&acceptingConnections, 0)
|
||||
|
||||
osEnv := types.OsEnv{}
|
||||
readConfig := ReadConfig{}
|
||||
config := readConfig.Read(osEnv)
|
||||
|
||||
if len(config.faasProcess) == 0 {
|
||||
log.Panicln("Provide a valid process via fprocess environmental variable.")
|
||||
return
|
||||
}
|
||||
|
||||
readTimeout := config.readTimeout
|
||||
writeTimeout := config.writeTimeout
|
||||
|
||||
s := &http.Server{
|
||||
Addr: fmt.Sprintf(":%d", config.port),
|
||||
ReadTimeout: readTimeout,
|
||||
WriteTimeout: writeTimeout,
|
||||
MaxHeaderBytes: 1 << 20, // Max header of 1MB
|
||||
}
|
||||
|
||||
httpMetrics := metrics.NewHttp()
|
||||
|
||||
log.Printf("Timeouts: read: %s, write: %s hard: %s.\n",
|
||||
readTimeout,
|
||||
writeTimeout,
|
||||
config.execTimeout)
|
||||
log.Printf("Listening on port: %d\n", config.port)
|
||||
|
||||
http.HandleFunc("/_/health", makeHealthHandler())
|
||||
http.HandleFunc("/", metrics.InstrumentHandler(makeRequestHandler(&config), httpMetrics))
|
||||
|
||||
metricsServer := metrics.MetricsServer{}
|
||||
metricsServer.Register(config.metricsPort)
|
||||
|
||||
cancel := make(chan bool)
|
||||
|
||||
go metricsServer.Serve(cancel)
|
||||
|
||||
shutdownTimeout := config.writeTimeout
|
||||
listenUntilShutdown(shutdownTimeout, s, config.suppressLock)
|
||||
}
|
||||
|
||||
func markUnhealthy() error {
|
||||
atomic.StoreInt32(&acceptingConnections, 0)
|
||||
|
||||
path := filepath.Join(os.TempDir(), ".lock")
|
||||
log.Printf("Removing lock-file : %s\n", path)
|
||||
removeErr := os.Remove(path)
|
||||
return removeErr
|
||||
}
|
||||
|
||||
// listenUntilShutdown will listen for HTTP requests until SIGTERM
|
||||
// is sent at which point the code will wait `shutdownTimeout` before
|
||||
// closing off connections and a futher `shutdownTimeout` before
|
||||
// exiting
|
||||
func listenUntilShutdown(shutdownTimeout time.Duration, s *http.Server, suppressLock bool) {
|
||||
|
||||
idleConnsClosed := make(chan struct{})
|
||||
go func() {
|
||||
sig := make(chan os.Signal, 1)
|
||||
signal.Notify(sig, syscall.SIGTERM)
|
||||
|
||||
<-sig
|
||||
|
||||
log.Printf("SIGTERM received.. shutting down server in %s\n", shutdownTimeout.String())
|
||||
|
||||
healthErr := markUnhealthy()
|
||||
|
||||
if healthErr != nil {
|
||||
log.Printf("Unable to mark unhealthy during shutdown: %s\n", healthErr.Error())
|
||||
}
|
||||
|
||||
<-time.Tick(shutdownTimeout)
|
||||
|
||||
if err := s.Shutdown(context.Background()); err != nil {
|
||||
// Error from closing listeners, or context timeout:
|
||||
log.Printf("Error in Shutdown: %v", err)
|
||||
}
|
||||
|
||||
log.Printf("No new connections allowed. Exiting in: %s\n", shutdownTimeout.String())
|
||||
|
||||
<-time.Tick(shutdownTimeout)
|
||||
|
||||
close(idleConnsClosed)
|
||||
}()
|
||||
|
||||
// Run the HTTP server in a separate go-routine.
|
||||
go func() {
|
||||
if err := s.ListenAndServe(); err != http.ErrServerClosed {
|
||||
log.Printf("Error ListenAndServe: %v", err)
|
||||
close(idleConnsClosed)
|
||||
}
|
||||
}()
|
||||
|
||||
if suppressLock == false {
|
||||
path, writeErr := createLockFile()
|
||||
|
||||
if writeErr != nil {
|
||||
log.Panicf("Cannot write %s. To disable lock-file set env suppress_lock=true.\n Error: %s.\n", path, writeErr.Error())
|
||||
}
|
||||
} else {
|
||||
log.Println("Warning: \"suppress_lock\" is enabled. No automated health-checks will be in place for your function.")
|
||||
|
||||
atomic.StoreInt32(&acceptingConnections, 1)
|
||||
}
|
||||
|
||||
<-idleConnsClosed
|
||||
}
|
||||
|
||||
func printVersion() {
|
||||
sha := "unknown"
|
||||
if len(GitCommit) > 0 {
|
||||
sha = GitCommit
|
||||
}
|
||||
|
||||
log.Printf("Version: %v\tSHA: %v\n", BuildVersion(), sha)
|
||||
}
|
||||
@ -1,17 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
export USR=$DOCKER_NS
|
||||
export TAG=$TRAVIS_TAG
|
||||
|
||||
docker manifest create $USR/classic-watchdog:$TAG \
|
||||
openfaas/classic-watchdog:$TAG-x86_64 \
|
||||
openfaas/classic-watchdog:$TAG-armhf \
|
||||
openfaas/classic-watchdog:$TAG-arm64 \
|
||||
openfaas/classic-watchdog:$TAG-windows
|
||||
|
||||
docker manifest annotate $USR/classic-watchdog:$TAG --arch arm openfaas/classic-watchdog:$TAG-armhf
|
||||
docker manifest annotate $USR/classic-watchdog:$TAG --arch arm64 openfaas/classic-watchdog:$TAG-arm64
|
||||
docker manifest annotate $USR/classic-watchdog:$TAG --os windows openfaas/classic-watchdog:$TAG-windows
|
||||
|
||||
docker manifest push $USR/classic-watchdog:$TAG
|
||||
|
||||
@ -1,27 +0,0 @@
|
||||
package metrics
|
||||
|
||||
import (
|
||||
"github.com/prometheus/client_golang/prometheus"
|
||||
"github.com/prometheus/client_golang/prometheus/promauto"
|
||||
)
|
||||
|
||||
type Http struct {
|
||||
RequestsTotal *prometheus.CounterVec
|
||||
RequestDurationHistogram *prometheus.HistogramVec
|
||||
}
|
||||
|
||||
func NewHttp() Http {
|
||||
return Http{
|
||||
RequestsTotal: promauto.NewCounterVec(prometheus.CounterOpts{
|
||||
Subsystem: "http",
|
||||
Name: "requests_total",
|
||||
Help: "total HTTP requests processed",
|
||||
}, []string{"code", "method"}),
|
||||
RequestDurationHistogram: promauto.NewHistogramVec(prometheus.HistogramOpts{
|
||||
Subsystem: "http",
|
||||
Name: "request_duration_seconds",
|
||||
Help: "Seconds spent serving HTTP requests.",
|
||||
Buckets: prometheus.DefBuckets,
|
||||
}, []string{"code", "method"}),
|
||||
}
|
||||
}
|
||||
@ -1,65 +0,0 @@
|
||||
package metrics
|
||||
|
||||
import (
|
||||
"context"
|
||||
"fmt"
|
||||
"log"
|
||||
"net/http"
|
||||
"time"
|
||||
|
||||
"github.com/prometheus/client_golang/prometheus/promhttp"
|
||||
)
|
||||
|
||||
// MetricsServer provides instrumentation for HTTP calls
|
||||
type MetricsServer struct {
|
||||
s *http.Server
|
||||
port int
|
||||
}
|
||||
|
||||
// Register binds a HTTP server to expose Prometheus metrics
|
||||
func (m *MetricsServer) Register(metricsPort int) {
|
||||
|
||||
m.port = metricsPort
|
||||
|
||||
readTimeout := time.Millisecond * 500
|
||||
writeTimeout := time.Millisecond * 500
|
||||
|
||||
metricsMux := http.NewServeMux()
|
||||
metricsMux.Handle("/metrics", promhttp.Handler())
|
||||
|
||||
m.s = &http.Server{
|
||||
Addr: fmt.Sprintf(":%d", metricsPort),
|
||||
ReadTimeout: readTimeout,
|
||||
WriteTimeout: writeTimeout,
|
||||
MaxHeaderBytes: 1 << 20, // Max header of 1MB
|
||||
Handler: metricsMux,
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
// Serve http traffic in go routine, non-blocking
|
||||
func (m *MetricsServer) Serve(cancel chan bool) {
|
||||
log.Printf("Metrics listening on port: %d\n", m.port)
|
||||
|
||||
go func() {
|
||||
if err := m.s.ListenAndServe(); err != http.ErrServerClosed {
|
||||
panic(fmt.Sprintf("metrics error ListenAndServe: %v\n", err))
|
||||
}
|
||||
}()
|
||||
|
||||
go func() {
|
||||
select {
|
||||
case <-cancel:
|
||||
log.Printf("metrics server shutdown\n")
|
||||
|
||||
m.s.Shutdown(context.Background())
|
||||
}
|
||||
}()
|
||||
}
|
||||
|
||||
// InstrumentHandler returns a handler which records HTTP requests
|
||||
// as they are made
|
||||
func InstrumentHandler(next http.Handler, _http Http) http.HandlerFunc {
|
||||
return promhttp.InstrumentHandlerCounter(_http.RequestsTotal,
|
||||
promhttp.InstrumentHandlerDuration(_http.RequestDurationHistogram, next))
|
||||
}
|
||||
@ -1,57 +0,0 @@
|
||||
package metrics
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"net/http"
|
||||
"testing"
|
||||
"time"
|
||||
)
|
||||
|
||||
func Test_Register_ProvidesBytes(t *testing.T) {
|
||||
|
||||
metricsPort := 31111
|
||||
|
||||
metricsServer := MetricsServer{}
|
||||
metricsServer.Register(metricsPort)
|
||||
|
||||
cancel := make(chan bool)
|
||||
go metricsServer.Serve(cancel)
|
||||
|
||||
defer func() {
|
||||
cancel <- true
|
||||
}()
|
||||
|
||||
retries := 10
|
||||
|
||||
for i := 0; i < retries; i++ {
|
||||
req, _ := http.NewRequest(http.MethodGet, fmt.Sprintf("http://127.0.0.1:%d/metrics", metricsPort), nil)
|
||||
|
||||
res, err := http.DefaultClient.Do(req)
|
||||
|
||||
if err != nil {
|
||||
t.Logf("cannot get metrics, or not ready: %s", err.Error())
|
||||
|
||||
time.Sleep(time.Millisecond * 100)
|
||||
continue
|
||||
}
|
||||
|
||||
wantStatus := http.StatusOK
|
||||
if res.StatusCode != wantStatus {
|
||||
t.Errorf("metrics gave wrong status, want: %d, got: %d", wantStatus, res.StatusCode)
|
||||
t.Fail()
|
||||
return
|
||||
}
|
||||
|
||||
if res.Body == nil {
|
||||
t.Errorf("metrics response should have a body")
|
||||
t.Fail()
|
||||
return
|
||||
}
|
||||
defer res.Body.Close()
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
t.Errorf("unable to get expected response from metrics server")
|
||||
t.Fail()
|
||||
}
|
||||
@ -1,147 +0,0 @@
|
||||
// Copyright (c) Alex Ellis 2017. All rights reserved.
|
||||
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
|
||||
|
||||
package main
|
||||
|
||||
import (
|
||||
"strconv"
|
||||
"time"
|
||||
)
|
||||
|
||||
// HasEnv provides interface for os.Getenv
|
||||
type HasEnv interface {
|
||||
Getenv(key string) string
|
||||
}
|
||||
|
||||
// ReadConfig constitutes config from env variables
|
||||
type ReadConfig struct {
|
||||
}
|
||||
|
||||
func isBoolValueSet(val string) bool {
|
||||
return len(val) > 0
|
||||
}
|
||||
|
||||
func parseBoolValue(val string) bool {
|
||||
if val == "true" {
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func parseIntOrDurationValue(val string, fallback time.Duration) time.Duration {
|
||||
if len(val) > 0 {
|
||||
parsedVal, parseErr := strconv.Atoi(val)
|
||||
if parseErr == nil && parsedVal >= 0 {
|
||||
return time.Duration(parsedVal) * time.Second
|
||||
}
|
||||
}
|
||||
|
||||
duration, durationErr := time.ParseDuration(val)
|
||||
if durationErr != nil {
|
||||
return fallback
|
||||
}
|
||||
return duration
|
||||
}
|
||||
|
||||
func parseIntValue(val string, fallback int) int {
|
||||
if len(val) > 0 {
|
||||
parsedVal, parseErr := strconv.Atoi(val)
|
||||
if parseErr == nil && parsedVal >= 0 {
|
||||
return parsedVal
|
||||
}
|
||||
}
|
||||
|
||||
return fallback
|
||||
}
|
||||
|
||||
// Read fetches config from environmental variables.
|
||||
func (ReadConfig) Read(hasEnv HasEnv) WatchdogConfig {
|
||||
cfg := WatchdogConfig{
|
||||
writeDebug: false,
|
||||
cgiHeaders: true,
|
||||
combineOutput: true,
|
||||
}
|
||||
|
||||
cfg.faasProcess = hasEnv.Getenv("fprocess")
|
||||
|
||||
cfg.readTimeout = parseIntOrDurationValue(hasEnv.Getenv("read_timeout"), time.Second*5)
|
||||
cfg.writeTimeout = parseIntOrDurationValue(hasEnv.Getenv("write_timeout"), time.Second*5)
|
||||
|
||||
cfg.execTimeout = parseIntOrDurationValue(hasEnv.Getenv("exec_timeout"), time.Second*0)
|
||||
cfg.port = parseIntValue(hasEnv.Getenv("port"), 8080)
|
||||
|
||||
writeDebugEnv := hasEnv.Getenv("write_debug")
|
||||
if isBoolValueSet(writeDebugEnv) {
|
||||
cfg.writeDebug = parseBoolValue(writeDebugEnv)
|
||||
}
|
||||
|
||||
cgiHeadersEnv := hasEnv.Getenv("cgi_headers")
|
||||
if isBoolValueSet(cgiHeadersEnv) {
|
||||
cfg.cgiHeaders = parseBoolValue(cgiHeadersEnv)
|
||||
}
|
||||
|
||||
cfg.marshalRequest = parseBoolValue(hasEnv.Getenv("marshal_request"))
|
||||
cfg.debugHeaders = parseBoolValue(hasEnv.Getenv("debug_headers"))
|
||||
|
||||
cfg.suppressLock = parseBoolValue(hasEnv.Getenv("suppress_lock"))
|
||||
|
||||
cfg.contentType = hasEnv.Getenv("content_type")
|
||||
|
||||
if isBoolValueSet(hasEnv.Getenv("combine_output")) {
|
||||
cfg.combineOutput = parseBoolValue(hasEnv.Getenv("combine_output"))
|
||||
}
|
||||
|
||||
cfg.metricsPort = 8081
|
||||
cfg.maxInflight = parseIntValue(hasEnv.Getenv("max_inflight"), 0)
|
||||
|
||||
return cfg
|
||||
}
|
||||
|
||||
// WatchdogConfig for the process.
|
||||
type WatchdogConfig struct {
|
||||
|
||||
// HTTP read timeout
|
||||
readTimeout time.Duration
|
||||
|
||||
// HTTP write timeout
|
||||
writeTimeout time.Duration
|
||||
|
||||
// faasProcess is the process to exec
|
||||
faasProcess string
|
||||
|
||||
// duration until the faasProcess will be killed
|
||||
execTimeout time.Duration
|
||||
|
||||
// writeDebug write console stdout statements to the container
|
||||
writeDebug bool
|
||||
|
||||
// marshal header and body via JSON
|
||||
marshalRequest bool
|
||||
|
||||
// cgiHeaders will make environmental variables available with all the HTTP headers.
|
||||
cgiHeaders bool
|
||||
|
||||
// prints out all incoming and out-going HTTP headers
|
||||
debugHeaders bool
|
||||
|
||||
// Don't write a lock file to /tmp/
|
||||
suppressLock bool
|
||||
|
||||
// contentType forces a specific pre-defined value for all responses
|
||||
contentType string
|
||||
|
||||
// port for HTTP server
|
||||
port int
|
||||
|
||||
// combineOutput combines stderr and stdout in response
|
||||
combineOutput bool
|
||||
|
||||
// metricsPort is the HTTP port to serve metrics on
|
||||
metricsPort int
|
||||
|
||||
// maxInflight limits the number of simultaneous
|
||||
// requests that the watchdog allows concurrently.
|
||||
// Any request which exceeds this limit will
|
||||
// have an immediate response of 429.
|
||||
maxInflight int
|
||||
}
|
||||
@ -1,258 +0,0 @@
|
||||
// Copyright (c) Alex Ellis 2017. All rights reserved.
|
||||
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
|
||||
|
||||
package main
|
||||
|
||||
import (
|
||||
"testing"
|
||||
"time"
|
||||
)
|
||||
|
||||
type EnvBucket struct {
|
||||
Items map[string]string
|
||||
}
|
||||
|
||||
func NewEnvBucket() EnvBucket {
|
||||
return EnvBucket{
|
||||
Items: make(map[string]string),
|
||||
}
|
||||
}
|
||||
|
||||
func (e EnvBucket) Getenv(key string) string {
|
||||
return e.Items[key]
|
||||
}
|
||||
|
||||
func (e EnvBucket) Setenv(key string, value string) {
|
||||
e.Items[key] = value
|
||||
}
|
||||
|
||||
func TestRead_CombineOutput_DefaultTrue(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
want := true
|
||||
if config.combineOutput != want {
|
||||
t.Logf("combineOutput error, want: %v, got: %v", want, config.combineOutput)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_CombineOutput_OverrideFalse(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
defaults.Setenv("combine_output", "false")
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
want := false
|
||||
if config.combineOutput != want {
|
||||
t.Logf("combineOutput error, want: %v, got: %v", want, config.combineOutput)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_CgiHeaders_OverrideFalse(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
defaults.Setenv("cgi_headers", "false")
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if config.cgiHeaders != false {
|
||||
t.Logf("cgiHeaders should have been false (via env)")
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_CgiHeaders_DefaultIsTrueConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if config.cgiHeaders != true {
|
||||
t.Logf("cgiHeaders should have been true (unspecified)")
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_WriteDebug_DefaultIsFalseConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if config.writeDebug != false {
|
||||
t.Logf("writeDebug should have been false (unspecified)")
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_WriteDebug_TrueOverrideConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
defaults.Setenv("write_debug", "true")
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if config.writeDebug != true {
|
||||
t.Logf("writeDebug should have been true (specified)")
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_WriteDebug_FlaseConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
defaults.Setenv("write_debug", "false")
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if config.writeDebug != false {
|
||||
t.Logf("writeDebug should have been false (specified)")
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_SuppressLockConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
defaults.Setenv("suppress_lock", "true")
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if config.suppressLock != true {
|
||||
t.Logf("suppress_lock envVariable incorrect, got: %s.\n", config.faasProcess)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_ContentTypeConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
defaults.Setenv("content_type", "application/json")
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if config.contentType != "application/json" {
|
||||
t.Logf("content_type envVariable incorrect, got: %s.\n", config.contentType)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_FprocessConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
defaults.Setenv("fprocess", "cat")
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if config.faasProcess != "cat" {
|
||||
t.Logf("fprocess envVariable incorrect, got: %s.\n", config.faasProcess)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_EmptyTimeoutConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
readConfig := ReadConfig{}
|
||||
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if (config.readTimeout) != time.Duration(5)*time.Second {
|
||||
t.Log("readTimeout incorrect")
|
||||
t.Fail()
|
||||
}
|
||||
if (config.writeTimeout) != time.Duration(5)*time.Second {
|
||||
t.Log("writeTimeout incorrect")
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_DefaultPortConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
|
||||
readConfig := ReadConfig{}
|
||||
config := readConfig.Read(defaults)
|
||||
want := 8080
|
||||
if config.port != want {
|
||||
t.Logf("port got: %d, want: %d\n", config.port, want)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_PortConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
defaults.Setenv("port", "8081")
|
||||
|
||||
readConfig := ReadConfig{}
|
||||
config := readConfig.Read(defaults)
|
||||
want := 8081
|
||||
if config.port != want {
|
||||
t.Logf("port got: %d, want: %d\n", config.port, want)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_ReadAndWriteTimeoutConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
defaults.Setenv("read_timeout", "10")
|
||||
defaults.Setenv("write_timeout", "60")
|
||||
|
||||
readConfig := ReadConfig{}
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if (config.readTimeout) != time.Duration(10)*time.Second {
|
||||
t.Logf("readTimeout incorrect, got: %d\n", config.readTimeout)
|
||||
t.Fail()
|
||||
}
|
||||
if (config.writeTimeout) != time.Duration(60)*time.Second {
|
||||
t.Logf("writeTimeout incorrect, got: %d\n", config.writeTimeout)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_ReadAndWriteTimeoutDurationConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
defaults.Setenv("read_timeout", "20s")
|
||||
defaults.Setenv("write_timeout", "1m30s")
|
||||
|
||||
readConfig := ReadConfig{}
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
if (config.readTimeout) != time.Duration(20)*time.Second {
|
||||
t.Logf("readTimeout incorrect, got: %d\n", config.readTimeout)
|
||||
t.Fail()
|
||||
}
|
||||
if (config.writeTimeout) != time.Duration(90)*time.Second {
|
||||
t.Logf("writeTimeout incorrect, got: %d\n", config.writeTimeout)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_ExecTimeoutConfig(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
defaults.Setenv("exec_timeout", "3s")
|
||||
|
||||
readConfig := ReadConfig{}
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
want := time.Duration(3) * time.Second
|
||||
if (config.execTimeout) != want {
|
||||
t.Logf("execTimeout incorrect, got: %d - want: %s\n", config.execTimeout, want)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestRead_MetricsPort(t *testing.T) {
|
||||
defaults := NewEnvBucket()
|
||||
|
||||
readConfig := ReadConfig{}
|
||||
config := readConfig.Read(defaults)
|
||||
|
||||
want := 8081
|
||||
if config.metricsPort != want {
|
||||
t.Logf("metricsPort incorrect, got: %d - want: %d\n", config.metricsPort, want)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
@ -1,580 +0,0 @@
|
||||
// Copyright (c) Alex Ellis 2017. All rights reserved.
|
||||
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
|
||||
|
||||
package main
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"fmt"
|
||||
"io/ioutil"
|
||||
"log"
|
||||
"net/http"
|
||||
"net/http/httptest"
|
||||
"os"
|
||||
"path/filepath"
|
||||
"strings"
|
||||
"testing"
|
||||
"time"
|
||||
)
|
||||
|
||||
func TestHandler_make(t *testing.T) {
|
||||
config := WatchdogConfig{}
|
||||
handler := makeRequestHandler(&config)
|
||||
|
||||
if handler == nil {
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_TransferEncodingPassedToFunction(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
body := "Message"
|
||||
req, err := http.NewRequest(http.MethodPost, "/", bytes.NewBufferString(body))
|
||||
req.TransferEncoding = []string{
|
||||
"chunked",
|
||||
}
|
||||
req.ContentLength = -1
|
||||
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "env",
|
||||
cgiHeaders: true,
|
||||
}
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
|
||||
read, _ := ioutil.ReadAll(rr.Body)
|
||||
val := string(read)
|
||||
if !strings.Contains(val, `Http_ContentLength=-1`) {
|
||||
t.Errorf(config.faasProcess+" should print: Http_ContentLength=-1, got: %s\n", val)
|
||||
}
|
||||
|
||||
if !strings.Contains(val, "Http_Transfer_Encoding") {
|
||||
t.Errorf(config.faasProcess+" should print: Http_Transfer_Encoding=chunked, got: %s\n", val)
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
func TestHandler_HasCustomHeaderInFunction_WithCgi_Mode(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
body := ""
|
||||
req, err := http.NewRequest(http.MethodPost, "/", bytes.NewBufferString(body))
|
||||
req.Header.Add("custom-header", "value")
|
||||
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "env",
|
||||
cgiHeaders: true,
|
||||
}
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
|
||||
read, _ := ioutil.ReadAll(rr.Body)
|
||||
val := string(read)
|
||||
if !strings.Contains(val, "Http_ContentLength=0") {
|
||||
t.Errorf(config.faasProcess+" should print: Http_ContentLength=0, got: %s\n", val)
|
||||
}
|
||||
if !strings.Contains(val, "Http_Content_Length=0") {
|
||||
t.Errorf(config.faasProcess+" should print: Http_Content_Length=0, got: %s\n", val)
|
||||
}
|
||||
if !strings.Contains(val, "Http_Custom_Header") {
|
||||
t.Errorf(config.faasProcess+" should print: Http_Custom_Header, got: %s\n", val)
|
||||
}
|
||||
|
||||
seconds := rr.Header().Get("X-Duration-Seconds")
|
||||
if len(seconds) == 0 {
|
||||
t.Errorf(config.faasProcess + " should have given a duration as an X-Duration-Seconds header\n")
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_HasCustomHeaderInFunction_WithCgiMode_AndBody(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
body := "test"
|
||||
req, err := http.NewRequest(http.MethodPost, "/", bytes.NewBufferString(body))
|
||||
req.Header.Add("custom-header", "value")
|
||||
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "env",
|
||||
cgiHeaders: true,
|
||||
}
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
|
||||
read, _ := ioutil.ReadAll(rr.Body)
|
||||
val := string(read)
|
||||
if !strings.Contains(val, fmt.Sprintf("Http_ContentLength=%d", len(body))) {
|
||||
t.Errorf("'env' should printed: Http_ContentLength=0, got: %s\n", val)
|
||||
}
|
||||
if !strings.Contains(val, fmt.Sprintf("Http_Content_Length=%d", len(body))) {
|
||||
t.Errorf("'env' should printed: Http_Content_Length=0, got: %s\n", val)
|
||||
}
|
||||
if !strings.Contains(val, "Http_Custom_Header") {
|
||||
t.Errorf("'env' should printed: Http_Custom_Header, got: %s\n", val)
|
||||
}
|
||||
|
||||
seconds := rr.Header().Get("X-Duration-Seconds")
|
||||
if len(seconds) == 0 {
|
||||
t.Errorf("Exec of cat should have given a duration as an X-Duration-Seconds header\n")
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_HasHostHeaderWhenSet(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
body := "test"
|
||||
req, err := http.NewRequest(http.MethodPost, "http://gateway/function", bytes.NewBufferString(body))
|
||||
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "env",
|
||||
cgiHeaders: true,
|
||||
}
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
|
||||
read, _ := ioutil.ReadAll(rr.Body)
|
||||
val := string(read)
|
||||
if !strings.Contains(val, fmt.Sprintf("Http_Host=%s", req.URL.Host)) {
|
||||
t.Errorf("'env' should have printed: Http_Host=0, got: %s\n", val)
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_HostHeader_Empty_WhenNotSet(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
body := "test"
|
||||
req, err := http.NewRequest(http.MethodPost, "/function", bytes.NewBufferString(body))
|
||||
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "env",
|
||||
cgiHeaders: true,
|
||||
}
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
|
||||
read, _ := ioutil.ReadAll(rr.Body)
|
||||
val := string(read)
|
||||
if strings.Contains(val, fmt.Sprintf("Http_Host=%s", req.URL.Host)) {
|
||||
t.Errorf("Http_Host should not have been given, but was: %s\n", val)
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_StderrWritesToStderr_CombinedOutput_False(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
b := bytes.NewBuffer([]byte{})
|
||||
log.SetOutput(b)
|
||||
|
||||
body := ""
|
||||
req, err := http.NewRequest(http.MethodPost, "/", bytes.NewBufferString(body))
|
||||
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "stat x",
|
||||
cgiHeaders: true,
|
||||
combineOutput: false,
|
||||
}
|
||||
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusInternalServerError
|
||||
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
|
||||
log.SetOutput(os.Stderr)
|
||||
|
||||
stderrBytes, _ := ioutil.ReadAll(b)
|
||||
stderrVal := string(stderrBytes)
|
||||
|
||||
want := "No such file or directory"
|
||||
if strings.Contains(stderrVal, want) == false {
|
||||
t.Logf("Stderr should have contained error from function \"%s\", but was: %s", want, stderrVal)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_StderrWritesToResponse_CombinedOutput_True(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
b := bytes.NewBuffer([]byte{})
|
||||
log.SetOutput(b)
|
||||
|
||||
body := ""
|
||||
req, err := http.NewRequest(http.MethodPost, "/", bytes.NewBufferString(body))
|
||||
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "stat x",
|
||||
cgiHeaders: true,
|
||||
combineOutput: true,
|
||||
}
|
||||
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusInternalServerError
|
||||
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
|
||||
log.SetOutput(os.Stderr)
|
||||
|
||||
stderrBytes, _ := ioutil.ReadAll(b)
|
||||
stderrVal := string(stderrBytes)
|
||||
stdErrWant := "No such file or directory"
|
||||
if strings.Contains(stderrVal, stdErrWant) {
|
||||
t.Logf("stderr should have not included any function errors, but did")
|
||||
t.Fail()
|
||||
}
|
||||
|
||||
bodyBytes, _ := ioutil.ReadAll(rr.Body)
|
||||
bodyStr := string(bodyBytes)
|
||||
stdOuputWant := `exit status 1`
|
||||
if strings.Contains(bodyStr, stdOuputWant) == false {
|
||||
t.Logf("response want: %s, got: %s", stdOuputWant, bodyStr)
|
||||
t.Fail()
|
||||
}
|
||||
if strings.Contains(bodyStr, stdErrWant) == false {
|
||||
t.Logf("response want: %s, got: %s", stdErrWant, bodyStr)
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_DoesntHaveCustomHeaderInFunction_WithoutCgi_Mode(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
body := ""
|
||||
req, err := http.NewRequest(http.MethodPost, "/", bytes.NewBufferString(body))
|
||||
req.Header.Add("custom-header", "value")
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "env",
|
||||
cgiHeaders: false,
|
||||
}
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
|
||||
read, _ := ioutil.ReadAll(rr.Body)
|
||||
val := string(read)
|
||||
if strings.Contains(val, "Http_Custom_Header") {
|
||||
t.Errorf("'env' should not have printed: Http_Custom_Header, got: %s\n", val)
|
||||
|
||||
}
|
||||
|
||||
seconds := rr.Header().Get("X-Duration-Seconds")
|
||||
if len(seconds) == 0 {
|
||||
t.Errorf("Exec of cat should have given a duration as an X-Duration-Seconds header\n")
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_HasXDurationSecondsHeader(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
body := "hello"
|
||||
req, err := http.NewRequest(http.MethodPost, "/", bytes.NewBufferString(body))
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "cat",
|
||||
}
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
|
||||
seconds := rr.Header().Get("X-Duration-Seconds")
|
||||
if len(seconds) == 0 {
|
||||
t.Errorf("Exec of " + config.faasProcess + " should have given a duration as an X-Duration-Seconds header")
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_RequestTimeoutFailsForExceededDuration(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
verbs := []string{http.MethodPost}
|
||||
for _, verb := range verbs {
|
||||
|
||||
body := "hello"
|
||||
req, err := http.NewRequest(verb, "/", bytes.NewBufferString(body))
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "sleep 2",
|
||||
execTimeout: time.Duration(100) * time.Millisecond,
|
||||
}
|
||||
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusRequestTimeout
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code for verb [%s] - got: %v, want: %v",
|
||||
verb, status, required)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_StatusOKAllowed_ForWriteableVerbs(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
verbs := []string{http.MethodPost, http.MethodPut, http.MethodDelete}
|
||||
for _, verb := range verbs {
|
||||
|
||||
body := "hello"
|
||||
req, err := http.NewRequest(verb, "/", bytes.NewBufferString(body))
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "cat",
|
||||
}
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code for verb [%s] - got: %v, want: %v",
|
||||
verb, status, required)
|
||||
}
|
||||
|
||||
buf, _ := ioutil.ReadAll(rr.Body)
|
||||
val := string(buf)
|
||||
if val != body {
|
||||
t.Errorf("Exec of cat did not return input value, %s", val)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_StatusMethodNotAllowed_ForUnknown(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
req, err := http.NewRequest("UNKNOWN", "/", nil)
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{}
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusMethodNotAllowed
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code: got %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_StatusOKForGETAndNoBody(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
req, err := http.NewRequest(http.MethodGet, "/", nil)
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
// writeDebug: true,
|
||||
faasProcess: "date",
|
||||
}
|
||||
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code: got %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
}
|
||||
|
||||
func TestHealthHandler_StatusOK_LockFilePresent(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
present := lockFilePresent()
|
||||
|
||||
if present == false {
|
||||
if _, err := createLockFile(); err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
}
|
||||
|
||||
req, err := http.NewRequest(http.MethodGet, "/_/health", nil)
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
handler := makeHealthHandler()
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code: got %v, but wanted %v", status, required)
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
func TestHealthHandler_StatusInternalServerError_LockFileNotPresent(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
if lockFilePresent() == true {
|
||||
if err := removeLockFile(); err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
}
|
||||
|
||||
req, err := http.NewRequest(http.MethodGet, "/_/health", nil)
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
handler := makeHealthHandler()
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusServiceUnavailable
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v", status, required)
|
||||
}
|
||||
}
|
||||
|
||||
func TestHealthHandler_SatusMethoNotAllowed_ForWriteableVerbs(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
verbs := []string{http.MethodPost, http.MethodPut, http.MethodDelete}
|
||||
|
||||
for _, verb := range verbs {
|
||||
req, err := http.NewRequest(verb, "/_/health", nil)
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
handler := makeHealthHandler()
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusMethodNotAllowed
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code: got %v, but wanted %v", status, required)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestHandler_HasFullPathAndQueryInFunction_WithCgi_Mode(t *testing.T) {
|
||||
rr := httptest.NewRecorder()
|
||||
|
||||
body := ""
|
||||
wantPath := "/my/full/path"
|
||||
wantQuery := "q=x"
|
||||
requestURI := wantPath + "?" + wantQuery
|
||||
req, err := http.NewRequest(http.MethodPost, requestURI, bytes.NewBufferString(body))
|
||||
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
config := WatchdogConfig{
|
||||
faasProcess: "env",
|
||||
cgiHeaders: true,
|
||||
}
|
||||
handler := makeRequestHandler(&config)
|
||||
handler(rr, req)
|
||||
|
||||
required := http.StatusOK
|
||||
if status := rr.Code; status != required {
|
||||
t.Errorf("handler returned wrong status code - got: %v, want: %v",
|
||||
status, required)
|
||||
}
|
||||
|
||||
read, _ := ioutil.ReadAll(rr.Body)
|
||||
val := string(read)
|
||||
if !strings.Contains(val, "Http_Path="+wantPath) {
|
||||
t.Errorf(config.faasProcess+" should print: Http_Path="+wantPath+", got: %s\n", val)
|
||||
}
|
||||
|
||||
if !strings.Contains(val, "Http_Query="+wantQuery) {
|
||||
t.Errorf(config.faasProcess+" should print: Http_Query="+wantQuery+", got: %s\n", val)
|
||||
}
|
||||
}
|
||||
|
||||
func removeLockFile() error {
|
||||
path := filepath.Join(os.TempDir(), ".lock")
|
||||
log.Printf("Removing lock-file : %s\n", path)
|
||||
removeErr := os.Remove(path)
|
||||
return removeErr
|
||||
}
|
||||
@ -1,46 +0,0 @@
|
||||
// Copyright (c) Alex Ellis 2017. All rights reserved.
|
||||
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
|
||||
|
||||
package types
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"net/http"
|
||||
"os"
|
||||
)
|
||||
|
||||
// OsEnv implements interface to wrap os.Getenv
|
||||
type OsEnv struct {
|
||||
}
|
||||
|
||||
// Getenv wraps os.Getenv
|
||||
func (OsEnv) Getenv(key string) string {
|
||||
return os.Getenv(key)
|
||||
}
|
||||
|
||||
type MarshalBody struct {
|
||||
Raw []byte `json:"raw"`
|
||||
}
|
||||
|
||||
type MarshalReq struct {
|
||||
Header http.Header `json:"header"`
|
||||
Body MarshalBody `json:"body"`
|
||||
}
|
||||
|
||||
func UnmarshalRequest(data []byte) (*MarshalReq, error) {
|
||||
request := MarshalReq{}
|
||||
err := json.Unmarshal(data, &request)
|
||||
return &request, err
|
||||
}
|
||||
|
||||
func MarshalRequest(data []byte, header *http.Header) ([]byte, error) {
|
||||
req := MarshalReq{
|
||||
Body: MarshalBody{
|
||||
Raw: data,
|
||||
},
|
||||
Header: *header,
|
||||
}
|
||||
|
||||
res, marshalErr := json.Marshal(&req)
|
||||
return res, marshalErr
|
||||
}
|
||||
20
watchdog/vendor/github.com/beorn7/perks/LICENSE
generated
vendored
20
watchdog/vendor/github.com/beorn7/perks/LICENSE
generated
vendored
@ -1,20 +0,0 @@
|
||||
Copyright (C) 2013 Blake Mizerany
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining
|
||||
a copy of this software and associated documentation files (the
|
||||
"Software"), to deal in the Software without restriction, including
|
||||
without limitation the rights to use, copy, modify, merge, publish,
|
||||
distribute, sublicense, and/or sell copies of the Software, and to
|
||||
permit persons to whom the Software is furnished to do so, subject to
|
||||
the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be
|
||||
included in all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
||||
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
|
||||
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
|
||||
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
|
||||
LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
|
||||
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
|
||||
WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
||||
2388
watchdog/vendor/github.com/beorn7/perks/quantile/exampledata.txt
generated
vendored
2388
watchdog/vendor/github.com/beorn7/perks/quantile/exampledata.txt
generated
vendored
File diff suppressed because it is too large
Load Diff
316
watchdog/vendor/github.com/beorn7/perks/quantile/stream.go
generated
vendored
316
watchdog/vendor/github.com/beorn7/perks/quantile/stream.go
generated
vendored
@ -1,316 +0,0 @@
|
||||
// Package quantile computes approximate quantiles over an unbounded data
|
||||
// stream within low memory and CPU bounds.
|
||||
//
|
||||
// A small amount of accuracy is traded to achieve the above properties.
|
||||
//
|
||||
// Multiple streams can be merged before calling Query to generate a single set
|
||||
// of results. This is meaningful when the streams represent the same type of
|
||||
// data. See Merge and Samples.
|
||||
//
|
||||
// For more detailed information about the algorithm used, see:
|
||||
//
|
||||
// Effective Computation of Biased Quantiles over Data Streams
|
||||
//
|
||||
// http://www.cs.rutgers.edu/~muthu/bquant.pdf
|
||||
package quantile
|
||||
|
||||
import (
|
||||
"math"
|
||||
"sort"
|
||||
)
|
||||
|
||||
// Sample holds an observed value and meta information for compression. JSON
|
||||
// tags have been added for convenience.
|
||||
type Sample struct {
|
||||
Value float64 `json:",string"`
|
||||
Width float64 `json:",string"`
|
||||
Delta float64 `json:",string"`
|
||||
}
|
||||
|
||||
// Samples represents a slice of samples. It implements sort.Interface.
|
||||
type Samples []Sample
|
||||
|
||||
func (a Samples) Len() int { return len(a) }
|
||||
func (a Samples) Less(i, j int) bool { return a[i].Value < a[j].Value }
|
||||
func (a Samples) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
|
||||
|
||||
type invariant func(s *stream, r float64) float64
|
||||
|
||||
// NewLowBiased returns an initialized Stream for low-biased quantiles
|
||||
// (e.g. 0.01, 0.1, 0.5) where the needed quantiles are not known a priori, but
|
||||
// error guarantees can still be given even for the lower ranks of the data
|
||||
// distribution.
|
||||
//
|
||||
// The provided epsilon is a relative error, i.e. the true quantile of a value
|
||||
// returned by a query is guaranteed to be within (1±Epsilon)*Quantile.
|
||||
//
|
||||
// See http://www.cs.rutgers.edu/~muthu/bquant.pdf for time, space, and error
|
||||
// properties.
|
||||
func NewLowBiased(epsilon float64) *Stream {
|
||||
ƒ := func(s *stream, r float64) float64 {
|
||||
return 2 * epsilon * r
|
||||
}
|
||||
return newStream(ƒ)
|
||||
}
|
||||
|
||||
// NewHighBiased returns an initialized Stream for high-biased quantiles
|
||||
// (e.g. 0.01, 0.1, 0.5) where the needed quantiles are not known a priori, but
|
||||
// error guarantees can still be given even for the higher ranks of the data
|
||||
// distribution.
|
||||
//
|
||||
// The provided epsilon is a relative error, i.e. the true quantile of a value
|
||||
// returned by a query is guaranteed to be within 1-(1±Epsilon)*(1-Quantile).
|
||||
//
|
||||
// See http://www.cs.rutgers.edu/~muthu/bquant.pdf for time, space, and error
|
||||
// properties.
|
||||
func NewHighBiased(epsilon float64) *Stream {
|
||||
ƒ := func(s *stream, r float64) float64 {
|
||||
return 2 * epsilon * (s.n - r)
|
||||
}
|
||||
return newStream(ƒ)
|
||||
}
|
||||
|
||||
// NewTargeted returns an initialized Stream concerned with a particular set of
|
||||
// quantile values that are supplied a priori. Knowing these a priori reduces
|
||||
// space and computation time. The targets map maps the desired quantiles to
|
||||
// their absolute errors, i.e. the true quantile of a value returned by a query
|
||||
// is guaranteed to be within (Quantile±Epsilon).
|
||||
//
|
||||
// See http://www.cs.rutgers.edu/~muthu/bquant.pdf for time, space, and error properties.
|
||||
func NewTargeted(targetMap map[float64]float64) *Stream {
|
||||
// Convert map to slice to avoid slow iterations on a map.
|
||||
// ƒ is called on the hot path, so converting the map to a slice
|
||||
// beforehand results in significant CPU savings.
|
||||
targets := targetMapToSlice(targetMap)
|
||||
|
||||
ƒ := func(s *stream, r float64) float64 {
|
||||
var m = math.MaxFloat64
|
||||
var f float64
|
||||
for _, t := range targets {
|
||||
if t.quantile*s.n <= r {
|
||||
f = (2 * t.epsilon * r) / t.quantile
|
||||
} else {
|
||||
f = (2 * t.epsilon * (s.n - r)) / (1 - t.quantile)
|
||||
}
|
||||
if f < m {
|
||||
m = f
|
||||
}
|
||||
}
|
||||
return m
|
||||
}
|
||||
return newStream(ƒ)
|
||||
}
|
||||
|
||||
type target struct {
|
||||
quantile float64
|
||||
epsilon float64
|
||||
}
|
||||
|
||||
func targetMapToSlice(targetMap map[float64]float64) []target {
|
||||
targets := make([]target, 0, len(targetMap))
|
||||
|
||||
for quantile, epsilon := range targetMap {
|
||||
t := target{
|
||||
quantile: quantile,
|
||||
epsilon: epsilon,
|
||||
}
|
||||
targets = append(targets, t)
|
||||
}
|
||||
|
||||
return targets
|
||||
}
|
||||
|
||||
// Stream computes quantiles for a stream of float64s. It is not thread-safe by
|
||||
// design. Take care when using across multiple goroutines.
|
||||
type Stream struct {
|
||||
*stream
|
||||
b Samples
|
||||
sorted bool
|
||||
}
|
||||
|
||||
func newStream(ƒ invariant) *Stream {
|
||||
x := &stream{ƒ: ƒ}
|
||||
return &Stream{x, make(Samples, 0, 500), true}
|
||||
}
|
||||
|
||||
// Insert inserts v into the stream.
|
||||
func (s *Stream) Insert(v float64) {
|
||||
s.insert(Sample{Value: v, Width: 1})
|
||||
}
|
||||
|
||||
func (s *Stream) insert(sample Sample) {
|
||||
s.b = append(s.b, sample)
|
||||
s.sorted = false
|
||||
if len(s.b) == cap(s.b) {
|
||||
s.flush()
|
||||
}
|
||||
}
|
||||
|
||||
// Query returns the computed qth percentiles value. If s was created with
|
||||
// NewTargeted, and q is not in the set of quantiles provided a priori, Query
|
||||
// will return an unspecified result.
|
||||
func (s *Stream) Query(q float64) float64 {
|
||||
if !s.flushed() {
|
||||
// Fast path when there hasn't been enough data for a flush;
|
||||
// this also yields better accuracy for small sets of data.
|
||||
l := len(s.b)
|
||||
if l == 0 {
|
||||
return 0
|
||||
}
|
||||
i := int(math.Ceil(float64(l) * q))
|
||||
if i > 0 {
|
||||
i -= 1
|
||||
}
|
||||
s.maybeSort()
|
||||
return s.b[i].Value
|
||||
}
|
||||
s.flush()
|
||||
return s.stream.query(q)
|
||||
}
|
||||
|
||||
// Merge merges samples into the underlying streams samples. This is handy when
|
||||
// merging multiple streams from separate threads, database shards, etc.
|
||||
//
|
||||
// ATTENTION: This method is broken and does not yield correct results. The
|
||||
// underlying algorithm is not capable of merging streams correctly.
|
||||
func (s *Stream) Merge(samples Samples) {
|
||||
sort.Sort(samples)
|
||||
s.stream.merge(samples)
|
||||
}
|
||||
|
||||
// Reset reinitializes and clears the list reusing the samples buffer memory.
|
||||
func (s *Stream) Reset() {
|
||||
s.stream.reset()
|
||||
s.b = s.b[:0]
|
||||
}
|
||||
|
||||
// Samples returns stream samples held by s.
|
||||
func (s *Stream) Samples() Samples {
|
||||
if !s.flushed() {
|
||||
return s.b
|
||||
}
|
||||
s.flush()
|
||||
return s.stream.samples()
|
||||
}
|
||||
|
||||
// Count returns the total number of samples observed in the stream
|
||||
// since initialization.
|
||||
func (s *Stream) Count() int {
|
||||
return len(s.b) + s.stream.count()
|
||||
}
|
||||
|
||||
func (s *Stream) flush() {
|
||||
s.maybeSort()
|
||||
s.stream.merge(s.b)
|
||||
s.b = s.b[:0]
|
||||
}
|
||||
|
||||
func (s *Stream) maybeSort() {
|
||||
if !s.sorted {
|
||||
s.sorted = true
|
||||
sort.Sort(s.b)
|
||||
}
|
||||
}
|
||||
|
||||
func (s *Stream) flushed() bool {
|
||||
return len(s.stream.l) > 0
|
||||
}
|
||||
|
||||
type stream struct {
|
||||
n float64
|
||||
l []Sample
|
||||
ƒ invariant
|
||||
}
|
||||
|
||||
func (s *stream) reset() {
|
||||
s.l = s.l[:0]
|
||||
s.n = 0
|
||||
}
|
||||
|
||||
func (s *stream) insert(v float64) {
|
||||
s.merge(Samples{{v, 1, 0}})
|
||||
}
|
||||
|
||||
func (s *stream) merge(samples Samples) {
|
||||
// TODO(beorn7): This tries to merge not only individual samples, but
|
||||
// whole summaries. The paper doesn't mention merging summaries at
|
||||
// all. Unittests show that the merging is inaccurate. Find out how to
|
||||
// do merges properly.
|
||||
var r float64
|
||||
i := 0
|
||||
for _, sample := range samples {
|
||||
for ; i < len(s.l); i++ {
|
||||
c := s.l[i]
|
||||
if c.Value > sample.Value {
|
||||
// Insert at position i.
|
||||
s.l = append(s.l, Sample{})
|
||||
copy(s.l[i+1:], s.l[i:])
|
||||
s.l[i] = Sample{
|
||||
sample.Value,
|
||||
sample.Width,
|
||||
math.Max(sample.Delta, math.Floor(s.ƒ(s, r))-1),
|
||||
// TODO(beorn7): How to calculate delta correctly?
|
||||
}
|
||||
i++
|
||||
goto inserted
|
||||
}
|
||||
r += c.Width
|
||||
}
|
||||
s.l = append(s.l, Sample{sample.Value, sample.Width, 0})
|
||||
i++
|
||||
inserted:
|
||||
s.n += sample.Width
|
||||
r += sample.Width
|
||||
}
|
||||
s.compress()
|
||||
}
|
||||
|
||||
func (s *stream) count() int {
|
||||
return int(s.n)
|
||||
}
|
||||
|
||||
func (s *stream) query(q float64) float64 {
|
||||
t := math.Ceil(q * s.n)
|
||||
t += math.Ceil(s.ƒ(s, t) / 2)
|
||||
p := s.l[0]
|
||||
var r float64
|
||||
for _, c := range s.l[1:] {
|
||||
r += p.Width
|
||||
if r+c.Width+c.Delta > t {
|
||||
return p.Value
|
||||
}
|
||||
p = c
|
||||
}
|
||||
return p.Value
|
||||
}
|
||||
|
||||
func (s *stream) compress() {
|
||||
if len(s.l) < 2 {
|
||||
return
|
||||
}
|
||||
x := s.l[len(s.l)-1]
|
||||
xi := len(s.l) - 1
|
||||
r := s.n - 1 - x.Width
|
||||
|
||||
for i := len(s.l) - 2; i >= 0; i-- {
|
||||
c := s.l[i]
|
||||
if c.Width+x.Width+x.Delta <= s.ƒ(s, r) {
|
||||
x.Width += c.Width
|
||||
s.l[xi] = x
|
||||
// Remove element at i.
|
||||
copy(s.l[i:], s.l[i+1:])
|
||||
s.l = s.l[:len(s.l)-1]
|
||||
xi -= 1
|
||||
} else {
|
||||
x = c
|
||||
xi = i
|
||||
}
|
||||
r -= c.Width
|
||||
}
|
||||
}
|
||||
|
||||
func (s *stream) samples() Samples {
|
||||
samples := make(Samples, len(s.l))
|
||||
copy(samples, s.l)
|
||||
return samples
|
||||
}
|
||||
3
watchdog/vendor/github.com/golang/protobuf/AUTHORS
generated
vendored
3
watchdog/vendor/github.com/golang/protobuf/AUTHORS
generated
vendored
@ -1,3 +0,0 @@
|
||||
# This source code refers to The Go Authors for copyright purposes.
|
||||
# The master list of authors is in the main Go distribution,
|
||||
# visible at http://tip.golang.org/AUTHORS.
|
||||
3
watchdog/vendor/github.com/golang/protobuf/CONTRIBUTORS
generated
vendored
3
watchdog/vendor/github.com/golang/protobuf/CONTRIBUTORS
generated
vendored
@ -1,3 +0,0 @@
|
||||
# This source code was written by the Go contributors.
|
||||
# The master list of contributors is in the main Go distribution,
|
||||
# visible at http://tip.golang.org/CONTRIBUTORS.
|
||||
28
watchdog/vendor/github.com/golang/protobuf/LICENSE
generated
vendored
28
watchdog/vendor/github.com/golang/protobuf/LICENSE
generated
vendored
@ -1,28 +0,0 @@
|
||||
Copyright 2010 The Go Authors. All rights reserved.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without
|
||||
modification, are permitted provided that the following conditions are
|
||||
met:
|
||||
|
||||
* Redistributions of source code must retain the above copyright
|
||||
notice, this list of conditions and the following disclaimer.
|
||||
* Redistributions in binary form must reproduce the above
|
||||
copyright notice, this list of conditions and the following disclaimer
|
||||
in the documentation and/or other materials provided with the
|
||||
distribution.
|
||||
* Neither the name of Google Inc. nor the names of its
|
||||
contributors may be used to endorse or promote products derived from
|
||||
this software without specific prior written permission.
|
||||
|
||||
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
253
watchdog/vendor/github.com/golang/protobuf/proto/clone.go
generated
vendored
253
watchdog/vendor/github.com/golang/protobuf/proto/clone.go
generated
vendored
@ -1,253 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2011 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
// Protocol buffer deep copy and merge.
|
||||
// TODO: RawMessage.
|
||||
|
||||
package proto
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"log"
|
||||
"reflect"
|
||||
"strings"
|
||||
)
|
||||
|
||||
// Clone returns a deep copy of a protocol buffer.
|
||||
func Clone(src Message) Message {
|
||||
in := reflect.ValueOf(src)
|
||||
if in.IsNil() {
|
||||
return src
|
||||
}
|
||||
out := reflect.New(in.Type().Elem())
|
||||
dst := out.Interface().(Message)
|
||||
Merge(dst, src)
|
||||
return dst
|
||||
}
|
||||
|
||||
// Merger is the interface representing objects that can merge messages of the same type.
|
||||
type Merger interface {
|
||||
// Merge merges src into this message.
|
||||
// Required and optional fields that are set in src will be set to that value in dst.
|
||||
// Elements of repeated fields will be appended.
|
||||
//
|
||||
// Merge may panic if called with a different argument type than the receiver.
|
||||
Merge(src Message)
|
||||
}
|
||||
|
||||
// generatedMerger is the custom merge method that generated protos will have.
|
||||
// We must add this method since a generate Merge method will conflict with
|
||||
// many existing protos that have a Merge data field already defined.
|
||||
type generatedMerger interface {
|
||||
XXX_Merge(src Message)
|
||||
}
|
||||
|
||||
// Merge merges src into dst.
|
||||
// Required and optional fields that are set in src will be set to that value in dst.
|
||||
// Elements of repeated fields will be appended.
|
||||
// Merge panics if src and dst are not the same type, or if dst is nil.
|
||||
func Merge(dst, src Message) {
|
||||
if m, ok := dst.(Merger); ok {
|
||||
m.Merge(src)
|
||||
return
|
||||
}
|
||||
|
||||
in := reflect.ValueOf(src)
|
||||
out := reflect.ValueOf(dst)
|
||||
if out.IsNil() {
|
||||
panic("proto: nil destination")
|
||||
}
|
||||
if in.Type() != out.Type() {
|
||||
panic(fmt.Sprintf("proto.Merge(%T, %T) type mismatch", dst, src))
|
||||
}
|
||||
if in.IsNil() {
|
||||
return // Merge from nil src is a noop
|
||||
}
|
||||
if m, ok := dst.(generatedMerger); ok {
|
||||
m.XXX_Merge(src)
|
||||
return
|
||||
}
|
||||
mergeStruct(out.Elem(), in.Elem())
|
||||
}
|
||||
|
||||
func mergeStruct(out, in reflect.Value) {
|
||||
sprop := GetProperties(in.Type())
|
||||
for i := 0; i < in.NumField(); i++ {
|
||||
f := in.Type().Field(i)
|
||||
if strings.HasPrefix(f.Name, "XXX_") {
|
||||
continue
|
||||
}
|
||||
mergeAny(out.Field(i), in.Field(i), false, sprop.Prop[i])
|
||||
}
|
||||
|
||||
if emIn, err := extendable(in.Addr().Interface()); err == nil {
|
||||
emOut, _ := extendable(out.Addr().Interface())
|
||||
mIn, muIn := emIn.extensionsRead()
|
||||
if mIn != nil {
|
||||
mOut := emOut.extensionsWrite()
|
||||
muIn.Lock()
|
||||
mergeExtension(mOut, mIn)
|
||||
muIn.Unlock()
|
||||
}
|
||||
}
|
||||
|
||||
uf := in.FieldByName("XXX_unrecognized")
|
||||
if !uf.IsValid() {
|
||||
return
|
||||
}
|
||||
uin := uf.Bytes()
|
||||
if len(uin) > 0 {
|
||||
out.FieldByName("XXX_unrecognized").SetBytes(append([]byte(nil), uin...))
|
||||
}
|
||||
}
|
||||
|
||||
// mergeAny performs a merge between two values of the same type.
|
||||
// viaPtr indicates whether the values were indirected through a pointer (implying proto2).
|
||||
// prop is set if this is a struct field (it may be nil).
|
||||
func mergeAny(out, in reflect.Value, viaPtr bool, prop *Properties) {
|
||||
if in.Type() == protoMessageType {
|
||||
if !in.IsNil() {
|
||||
if out.IsNil() {
|
||||
out.Set(reflect.ValueOf(Clone(in.Interface().(Message))))
|
||||
} else {
|
||||
Merge(out.Interface().(Message), in.Interface().(Message))
|
||||
}
|
||||
}
|
||||
return
|
||||
}
|
||||
switch in.Kind() {
|
||||
case reflect.Bool, reflect.Float32, reflect.Float64, reflect.Int32, reflect.Int64,
|
||||
reflect.String, reflect.Uint32, reflect.Uint64:
|
||||
if !viaPtr && isProto3Zero(in) {
|
||||
return
|
||||
}
|
||||
out.Set(in)
|
||||
case reflect.Interface:
|
||||
// Probably a oneof field; copy non-nil values.
|
||||
if in.IsNil() {
|
||||
return
|
||||
}
|
||||
// Allocate destination if it is not set, or set to a different type.
|
||||
// Otherwise we will merge as normal.
|
||||
if out.IsNil() || out.Elem().Type() != in.Elem().Type() {
|
||||
out.Set(reflect.New(in.Elem().Elem().Type())) // interface -> *T -> T -> new(T)
|
||||
}
|
||||
mergeAny(out.Elem(), in.Elem(), false, nil)
|
||||
case reflect.Map:
|
||||
if in.Len() == 0 {
|
||||
return
|
||||
}
|
||||
if out.IsNil() {
|
||||
out.Set(reflect.MakeMap(in.Type()))
|
||||
}
|
||||
// For maps with value types of *T or []byte we need to deep copy each value.
|
||||
elemKind := in.Type().Elem().Kind()
|
||||
for _, key := range in.MapKeys() {
|
||||
var val reflect.Value
|
||||
switch elemKind {
|
||||
case reflect.Ptr:
|
||||
val = reflect.New(in.Type().Elem().Elem())
|
||||
mergeAny(val, in.MapIndex(key), false, nil)
|
||||
case reflect.Slice:
|
||||
val = in.MapIndex(key)
|
||||
val = reflect.ValueOf(append([]byte{}, val.Bytes()...))
|
||||
default:
|
||||
val = in.MapIndex(key)
|
||||
}
|
||||
out.SetMapIndex(key, val)
|
||||
}
|
||||
case reflect.Ptr:
|
||||
if in.IsNil() {
|
||||
return
|
||||
}
|
||||
if out.IsNil() {
|
||||
out.Set(reflect.New(in.Elem().Type()))
|
||||
}
|
||||
mergeAny(out.Elem(), in.Elem(), true, nil)
|
||||
case reflect.Slice:
|
||||
if in.IsNil() {
|
||||
return
|
||||
}
|
||||
if in.Type().Elem().Kind() == reflect.Uint8 {
|
||||
// []byte is a scalar bytes field, not a repeated field.
|
||||
|
||||
// Edge case: if this is in a proto3 message, a zero length
|
||||
// bytes field is considered the zero value, and should not
|
||||
// be merged.
|
||||
if prop != nil && prop.proto3 && in.Len() == 0 {
|
||||
return
|
||||
}
|
||||
|
||||
// Make a deep copy.
|
||||
// Append to []byte{} instead of []byte(nil) so that we never end up
|
||||
// with a nil result.
|
||||
out.SetBytes(append([]byte{}, in.Bytes()...))
|
||||
return
|
||||
}
|
||||
n := in.Len()
|
||||
if out.IsNil() {
|
||||
out.Set(reflect.MakeSlice(in.Type(), 0, n))
|
||||
}
|
||||
switch in.Type().Elem().Kind() {
|
||||
case reflect.Bool, reflect.Float32, reflect.Float64, reflect.Int32, reflect.Int64,
|
||||
reflect.String, reflect.Uint32, reflect.Uint64:
|
||||
out.Set(reflect.AppendSlice(out, in))
|
||||
default:
|
||||
for i := 0; i < n; i++ {
|
||||
x := reflect.Indirect(reflect.New(in.Type().Elem()))
|
||||
mergeAny(x, in.Index(i), false, nil)
|
||||
out.Set(reflect.Append(out, x))
|
||||
}
|
||||
}
|
||||
case reflect.Struct:
|
||||
mergeStruct(out, in)
|
||||
default:
|
||||
// unknown type, so not a protocol buffer
|
||||
log.Printf("proto: don't know how to copy %v", in)
|
||||
}
|
||||
}
|
||||
|
||||
func mergeExtension(out, in map[int32]Extension) {
|
||||
for extNum, eIn := range in {
|
||||
eOut := Extension{desc: eIn.desc}
|
||||
if eIn.value != nil {
|
||||
v := reflect.New(reflect.TypeOf(eIn.value)).Elem()
|
||||
mergeAny(v, reflect.ValueOf(eIn.value), false, nil)
|
||||
eOut.value = v.Interface()
|
||||
}
|
||||
if eIn.enc != nil {
|
||||
eOut.enc = make([]byte, len(eIn.enc))
|
||||
copy(eOut.enc, eIn.enc)
|
||||
}
|
||||
|
||||
out[extNum] = eOut
|
||||
}
|
||||
}
|
||||
427
watchdog/vendor/github.com/golang/protobuf/proto/decode.go
generated
vendored
427
watchdog/vendor/github.com/golang/protobuf/proto/decode.go
generated
vendored
@ -1,427 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2010 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
package proto
|
||||
|
||||
/*
|
||||
* Routines for decoding protocol buffer data to construct in-memory representations.
|
||||
*/
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
"io"
|
||||
)
|
||||
|
||||
// errOverflow is returned when an integer is too large to be represented.
|
||||
var errOverflow = errors.New("proto: integer overflow")
|
||||
|
||||
// ErrInternalBadWireType is returned by generated code when an incorrect
|
||||
// wire type is encountered. It does not get returned to user code.
|
||||
var ErrInternalBadWireType = errors.New("proto: internal error: bad wiretype for oneof")
|
||||
|
||||
// DecodeVarint reads a varint-encoded integer from the slice.
|
||||
// It returns the integer and the number of bytes consumed, or
|
||||
// zero if there is not enough.
|
||||
// This is the format for the
|
||||
// int32, int64, uint32, uint64, bool, and enum
|
||||
// protocol buffer types.
|
||||
func DecodeVarint(buf []byte) (x uint64, n int) {
|
||||
for shift := uint(0); shift < 64; shift += 7 {
|
||||
if n >= len(buf) {
|
||||
return 0, 0
|
||||
}
|
||||
b := uint64(buf[n])
|
||||
n++
|
||||
x |= (b & 0x7F) << shift
|
||||
if (b & 0x80) == 0 {
|
||||
return x, n
|
||||
}
|
||||
}
|
||||
|
||||
// The number is too large to represent in a 64-bit value.
|
||||
return 0, 0
|
||||
}
|
||||
|
||||
func (p *Buffer) decodeVarintSlow() (x uint64, err error) {
|
||||
i := p.index
|
||||
l := len(p.buf)
|
||||
|
||||
for shift := uint(0); shift < 64; shift += 7 {
|
||||
if i >= l {
|
||||
err = io.ErrUnexpectedEOF
|
||||
return
|
||||
}
|
||||
b := p.buf[i]
|
||||
i++
|
||||
x |= (uint64(b) & 0x7F) << shift
|
||||
if b < 0x80 {
|
||||
p.index = i
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
// The number is too large to represent in a 64-bit value.
|
||||
err = errOverflow
|
||||
return
|
||||
}
|
||||
|
||||
// DecodeVarint reads a varint-encoded integer from the Buffer.
|
||||
// This is the format for the
|
||||
// int32, int64, uint32, uint64, bool, and enum
|
||||
// protocol buffer types.
|
||||
func (p *Buffer) DecodeVarint() (x uint64, err error) {
|
||||
i := p.index
|
||||
buf := p.buf
|
||||
|
||||
if i >= len(buf) {
|
||||
return 0, io.ErrUnexpectedEOF
|
||||
} else if buf[i] < 0x80 {
|
||||
p.index++
|
||||
return uint64(buf[i]), nil
|
||||
} else if len(buf)-i < 10 {
|
||||
return p.decodeVarintSlow()
|
||||
}
|
||||
|
||||
var b uint64
|
||||
// we already checked the first byte
|
||||
x = uint64(buf[i]) - 0x80
|
||||
i++
|
||||
|
||||
b = uint64(buf[i])
|
||||
i++
|
||||
x += b << 7
|
||||
if b&0x80 == 0 {
|
||||
goto done
|
||||
}
|
||||
x -= 0x80 << 7
|
||||
|
||||
b = uint64(buf[i])
|
||||
i++
|
||||
x += b << 14
|
||||
if b&0x80 == 0 {
|
||||
goto done
|
||||
}
|
||||
x -= 0x80 << 14
|
||||
|
||||
b = uint64(buf[i])
|
||||
i++
|
||||
x += b << 21
|
||||
if b&0x80 == 0 {
|
||||
goto done
|
||||
}
|
||||
x -= 0x80 << 21
|
||||
|
||||
b = uint64(buf[i])
|
||||
i++
|
||||
x += b << 28
|
||||
if b&0x80 == 0 {
|
||||
goto done
|
||||
}
|
||||
x -= 0x80 << 28
|
||||
|
||||
b = uint64(buf[i])
|
||||
i++
|
||||
x += b << 35
|
||||
if b&0x80 == 0 {
|
||||
goto done
|
||||
}
|
||||
x -= 0x80 << 35
|
||||
|
||||
b = uint64(buf[i])
|
||||
i++
|
||||
x += b << 42
|
||||
if b&0x80 == 0 {
|
||||
goto done
|
||||
}
|
||||
x -= 0x80 << 42
|
||||
|
||||
b = uint64(buf[i])
|
||||
i++
|
||||
x += b << 49
|
||||
if b&0x80 == 0 {
|
||||
goto done
|
||||
}
|
||||
x -= 0x80 << 49
|
||||
|
||||
b = uint64(buf[i])
|
||||
i++
|
||||
x += b << 56
|
||||
if b&0x80 == 0 {
|
||||
goto done
|
||||
}
|
||||
x -= 0x80 << 56
|
||||
|
||||
b = uint64(buf[i])
|
||||
i++
|
||||
x += b << 63
|
||||
if b&0x80 == 0 {
|
||||
goto done
|
||||
}
|
||||
|
||||
return 0, errOverflow
|
||||
|
||||
done:
|
||||
p.index = i
|
||||
return x, nil
|
||||
}
|
||||
|
||||
// DecodeFixed64 reads a 64-bit integer from the Buffer.
|
||||
// This is the format for the
|
||||
// fixed64, sfixed64, and double protocol buffer types.
|
||||
func (p *Buffer) DecodeFixed64() (x uint64, err error) {
|
||||
// x, err already 0
|
||||
i := p.index + 8
|
||||
if i < 0 || i > len(p.buf) {
|
||||
err = io.ErrUnexpectedEOF
|
||||
return
|
||||
}
|
||||
p.index = i
|
||||
|
||||
x = uint64(p.buf[i-8])
|
||||
x |= uint64(p.buf[i-7]) << 8
|
||||
x |= uint64(p.buf[i-6]) << 16
|
||||
x |= uint64(p.buf[i-5]) << 24
|
||||
x |= uint64(p.buf[i-4]) << 32
|
||||
x |= uint64(p.buf[i-3]) << 40
|
||||
x |= uint64(p.buf[i-2]) << 48
|
||||
x |= uint64(p.buf[i-1]) << 56
|
||||
return
|
||||
}
|
||||
|
||||
// DecodeFixed32 reads a 32-bit integer from the Buffer.
|
||||
// This is the format for the
|
||||
// fixed32, sfixed32, and float protocol buffer types.
|
||||
func (p *Buffer) DecodeFixed32() (x uint64, err error) {
|
||||
// x, err already 0
|
||||
i := p.index + 4
|
||||
if i < 0 || i > len(p.buf) {
|
||||
err = io.ErrUnexpectedEOF
|
||||
return
|
||||
}
|
||||
p.index = i
|
||||
|
||||
x = uint64(p.buf[i-4])
|
||||
x |= uint64(p.buf[i-3]) << 8
|
||||
x |= uint64(p.buf[i-2]) << 16
|
||||
x |= uint64(p.buf[i-1]) << 24
|
||||
return
|
||||
}
|
||||
|
||||
// DecodeZigzag64 reads a zigzag-encoded 64-bit integer
|
||||
// from the Buffer.
|
||||
// This is the format used for the sint64 protocol buffer type.
|
||||
func (p *Buffer) DecodeZigzag64() (x uint64, err error) {
|
||||
x, err = p.DecodeVarint()
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
x = (x >> 1) ^ uint64((int64(x&1)<<63)>>63)
|
||||
return
|
||||
}
|
||||
|
||||
// DecodeZigzag32 reads a zigzag-encoded 32-bit integer
|
||||
// from the Buffer.
|
||||
// This is the format used for the sint32 protocol buffer type.
|
||||
func (p *Buffer) DecodeZigzag32() (x uint64, err error) {
|
||||
x, err = p.DecodeVarint()
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
x = uint64((uint32(x) >> 1) ^ uint32((int32(x&1)<<31)>>31))
|
||||
return
|
||||
}
|
||||
|
||||
// DecodeRawBytes reads a count-delimited byte buffer from the Buffer.
|
||||
// This is the format used for the bytes protocol buffer
|
||||
// type and for embedded messages.
|
||||
func (p *Buffer) DecodeRawBytes(alloc bool) (buf []byte, err error) {
|
||||
n, err := p.DecodeVarint()
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
nb := int(n)
|
||||
if nb < 0 {
|
||||
return nil, fmt.Errorf("proto: bad byte length %d", nb)
|
||||
}
|
||||
end := p.index + nb
|
||||
if end < p.index || end > len(p.buf) {
|
||||
return nil, io.ErrUnexpectedEOF
|
||||
}
|
||||
|
||||
if !alloc {
|
||||
// todo: check if can get more uses of alloc=false
|
||||
buf = p.buf[p.index:end]
|
||||
p.index += nb
|
||||
return
|
||||
}
|
||||
|
||||
buf = make([]byte, nb)
|
||||
copy(buf, p.buf[p.index:])
|
||||
p.index += nb
|
||||
return
|
||||
}
|
||||
|
||||
// DecodeStringBytes reads an encoded string from the Buffer.
|
||||
// This is the format used for the proto2 string type.
|
||||
func (p *Buffer) DecodeStringBytes() (s string, err error) {
|
||||
buf, err := p.DecodeRawBytes(false)
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
return string(buf), nil
|
||||
}
|
||||
|
||||
// Unmarshaler is the interface representing objects that can
|
||||
// unmarshal themselves. The argument points to data that may be
|
||||
// overwritten, so implementations should not keep references to the
|
||||
// buffer.
|
||||
// Unmarshal implementations should not clear the receiver.
|
||||
// Any unmarshaled data should be merged into the receiver.
|
||||
// Callers of Unmarshal that do not want to retain existing data
|
||||
// should Reset the receiver before calling Unmarshal.
|
||||
type Unmarshaler interface {
|
||||
Unmarshal([]byte) error
|
||||
}
|
||||
|
||||
// newUnmarshaler is the interface representing objects that can
|
||||
// unmarshal themselves. The semantics are identical to Unmarshaler.
|
||||
//
|
||||
// This exists to support protoc-gen-go generated messages.
|
||||
// The proto package will stop type-asserting to this interface in the future.
|
||||
//
|
||||
// DO NOT DEPEND ON THIS.
|
||||
type newUnmarshaler interface {
|
||||
XXX_Unmarshal([]byte) error
|
||||
}
|
||||
|
||||
// Unmarshal parses the protocol buffer representation in buf and places the
|
||||
// decoded result in pb. If the struct underlying pb does not match
|
||||
// the data in buf, the results can be unpredictable.
|
||||
//
|
||||
// Unmarshal resets pb before starting to unmarshal, so any
|
||||
// existing data in pb is always removed. Use UnmarshalMerge
|
||||
// to preserve and append to existing data.
|
||||
func Unmarshal(buf []byte, pb Message) error {
|
||||
pb.Reset()
|
||||
if u, ok := pb.(newUnmarshaler); ok {
|
||||
return u.XXX_Unmarshal(buf)
|
||||
}
|
||||
if u, ok := pb.(Unmarshaler); ok {
|
||||
return u.Unmarshal(buf)
|
||||
}
|
||||
return NewBuffer(buf).Unmarshal(pb)
|
||||
}
|
||||
|
||||
// UnmarshalMerge parses the protocol buffer representation in buf and
|
||||
// writes the decoded result to pb. If the struct underlying pb does not match
|
||||
// the data in buf, the results can be unpredictable.
|
||||
//
|
||||
// UnmarshalMerge merges into existing data in pb.
|
||||
// Most code should use Unmarshal instead.
|
||||
func UnmarshalMerge(buf []byte, pb Message) error {
|
||||
if u, ok := pb.(newUnmarshaler); ok {
|
||||
return u.XXX_Unmarshal(buf)
|
||||
}
|
||||
if u, ok := pb.(Unmarshaler); ok {
|
||||
// NOTE: The history of proto have unfortunately been inconsistent
|
||||
// whether Unmarshaler should or should not implicitly clear itself.
|
||||
// Some implementations do, most do not.
|
||||
// Thus, calling this here may or may not do what people want.
|
||||
//
|
||||
// See https://github.com/golang/protobuf/issues/424
|
||||
return u.Unmarshal(buf)
|
||||
}
|
||||
return NewBuffer(buf).Unmarshal(pb)
|
||||
}
|
||||
|
||||
// DecodeMessage reads a count-delimited message from the Buffer.
|
||||
func (p *Buffer) DecodeMessage(pb Message) error {
|
||||
enc, err := p.DecodeRawBytes(false)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return NewBuffer(enc).Unmarshal(pb)
|
||||
}
|
||||
|
||||
// DecodeGroup reads a tag-delimited group from the Buffer.
|
||||
// StartGroup tag is already consumed. This function consumes
|
||||
// EndGroup tag.
|
||||
func (p *Buffer) DecodeGroup(pb Message) error {
|
||||
b := p.buf[p.index:]
|
||||
x, y := findEndGroup(b)
|
||||
if x < 0 {
|
||||
return io.ErrUnexpectedEOF
|
||||
}
|
||||
err := Unmarshal(b[:x], pb)
|
||||
p.index += y
|
||||
return err
|
||||
}
|
||||
|
||||
// Unmarshal parses the protocol buffer representation in the
|
||||
// Buffer and places the decoded result in pb. If the struct
|
||||
// underlying pb does not match the data in the buffer, the results can be
|
||||
// unpredictable.
|
||||
//
|
||||
// Unlike proto.Unmarshal, this does not reset pb before starting to unmarshal.
|
||||
func (p *Buffer) Unmarshal(pb Message) error {
|
||||
// If the object can unmarshal itself, let it.
|
||||
if u, ok := pb.(newUnmarshaler); ok {
|
||||
err := u.XXX_Unmarshal(p.buf[p.index:])
|
||||
p.index = len(p.buf)
|
||||
return err
|
||||
}
|
||||
if u, ok := pb.(Unmarshaler); ok {
|
||||
// NOTE: The history of proto have unfortunately been inconsistent
|
||||
// whether Unmarshaler should or should not implicitly clear itself.
|
||||
// Some implementations do, most do not.
|
||||
// Thus, calling this here may or may not do what people want.
|
||||
//
|
||||
// See https://github.com/golang/protobuf/issues/424
|
||||
err := u.Unmarshal(p.buf[p.index:])
|
||||
p.index = len(p.buf)
|
||||
return err
|
||||
}
|
||||
|
||||
// Slow workaround for messages that aren't Unmarshalers.
|
||||
// This includes some hand-coded .pb.go files and
|
||||
// bootstrap protos.
|
||||
// TODO: fix all of those and then add Unmarshal to
|
||||
// the Message interface. Then:
|
||||
// The cast above and code below can be deleted.
|
||||
// The old unmarshaler can be deleted.
|
||||
// Clients can call Unmarshal directly (can already do that, actually).
|
||||
var info InternalMessageInfo
|
||||
err := info.Unmarshal(pb, p.buf[p.index:])
|
||||
p.index = len(p.buf)
|
||||
return err
|
||||
}
|
||||
63
watchdog/vendor/github.com/golang/protobuf/proto/deprecated.go
generated
vendored
63
watchdog/vendor/github.com/golang/protobuf/proto/deprecated.go
generated
vendored
@ -1,63 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2018 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
package proto
|
||||
|
||||
import "errors"
|
||||
|
||||
// Deprecated: do not use.
|
||||
type Stats struct{ Emalloc, Dmalloc, Encode, Decode, Chit, Cmiss, Size uint64 }
|
||||
|
||||
// Deprecated: do not use.
|
||||
func GetStats() Stats { return Stats{} }
|
||||
|
||||
// Deprecated: do not use.
|
||||
func MarshalMessageSet(interface{}) ([]byte, error) {
|
||||
return nil, errors.New("proto: not implemented")
|
||||
}
|
||||
|
||||
// Deprecated: do not use.
|
||||
func UnmarshalMessageSet([]byte, interface{}) error {
|
||||
return errors.New("proto: not implemented")
|
||||
}
|
||||
|
||||
// Deprecated: do not use.
|
||||
func MarshalMessageSetJSON(interface{}) ([]byte, error) {
|
||||
return nil, errors.New("proto: not implemented")
|
||||
}
|
||||
|
||||
// Deprecated: do not use.
|
||||
func UnmarshalMessageSetJSON([]byte, interface{}) error {
|
||||
return errors.New("proto: not implemented")
|
||||
}
|
||||
|
||||
// Deprecated: do not use.
|
||||
func RegisterMessageSetType(Message, int32, string) {}
|
||||
350
watchdog/vendor/github.com/golang/protobuf/proto/discard.go
generated
vendored
350
watchdog/vendor/github.com/golang/protobuf/proto/discard.go
generated
vendored
@ -1,350 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2017 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
package proto
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"reflect"
|
||||
"strings"
|
||||
"sync"
|
||||
"sync/atomic"
|
||||
)
|
||||
|
||||
type generatedDiscarder interface {
|
||||
XXX_DiscardUnknown()
|
||||
}
|
||||
|
||||
// DiscardUnknown recursively discards all unknown fields from this message
|
||||
// and all embedded messages.
|
||||
//
|
||||
// When unmarshaling a message with unrecognized fields, the tags and values
|
||||
// of such fields are preserved in the Message. This allows a later call to
|
||||
// marshal to be able to produce a message that continues to have those
|
||||
// unrecognized fields. To avoid this, DiscardUnknown is used to
|
||||
// explicitly clear the unknown fields after unmarshaling.
|
||||
//
|
||||
// For proto2 messages, the unknown fields of message extensions are only
|
||||
// discarded from messages that have been accessed via GetExtension.
|
||||
func DiscardUnknown(m Message) {
|
||||
if m, ok := m.(generatedDiscarder); ok {
|
||||
m.XXX_DiscardUnknown()
|
||||
return
|
||||
}
|
||||
// TODO: Dynamically populate a InternalMessageInfo for legacy messages,
|
||||
// but the master branch has no implementation for InternalMessageInfo,
|
||||
// so it would be more work to replicate that approach.
|
||||
discardLegacy(m)
|
||||
}
|
||||
|
||||
// DiscardUnknown recursively discards all unknown fields.
|
||||
func (a *InternalMessageInfo) DiscardUnknown(m Message) {
|
||||
di := atomicLoadDiscardInfo(&a.discard)
|
||||
if di == nil {
|
||||
di = getDiscardInfo(reflect.TypeOf(m).Elem())
|
||||
atomicStoreDiscardInfo(&a.discard, di)
|
||||
}
|
||||
di.discard(toPointer(&m))
|
||||
}
|
||||
|
||||
type discardInfo struct {
|
||||
typ reflect.Type
|
||||
|
||||
initialized int32 // 0: only typ is valid, 1: everything is valid
|
||||
lock sync.Mutex
|
||||
|
||||
fields []discardFieldInfo
|
||||
unrecognized field
|
||||
}
|
||||
|
||||
type discardFieldInfo struct {
|
||||
field field // Offset of field, guaranteed to be valid
|
||||
discard func(src pointer)
|
||||
}
|
||||
|
||||
var (
|
||||
discardInfoMap = map[reflect.Type]*discardInfo{}
|
||||
discardInfoLock sync.Mutex
|
||||
)
|
||||
|
||||
func getDiscardInfo(t reflect.Type) *discardInfo {
|
||||
discardInfoLock.Lock()
|
||||
defer discardInfoLock.Unlock()
|
||||
di := discardInfoMap[t]
|
||||
if di == nil {
|
||||
di = &discardInfo{typ: t}
|
||||
discardInfoMap[t] = di
|
||||
}
|
||||
return di
|
||||
}
|
||||
|
||||
func (di *discardInfo) discard(src pointer) {
|
||||
if src.isNil() {
|
||||
return // Nothing to do.
|
||||
}
|
||||
|
||||
if atomic.LoadInt32(&di.initialized) == 0 {
|
||||
di.computeDiscardInfo()
|
||||
}
|
||||
|
||||
for _, fi := range di.fields {
|
||||
sfp := src.offset(fi.field)
|
||||
fi.discard(sfp)
|
||||
}
|
||||
|
||||
// For proto2 messages, only discard unknown fields in message extensions
|
||||
// that have been accessed via GetExtension.
|
||||
if em, err := extendable(src.asPointerTo(di.typ).Interface()); err == nil {
|
||||
// Ignore lock since DiscardUnknown is not concurrency safe.
|
||||
emm, _ := em.extensionsRead()
|
||||
for _, mx := range emm {
|
||||
if m, ok := mx.value.(Message); ok {
|
||||
DiscardUnknown(m)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if di.unrecognized.IsValid() {
|
||||
*src.offset(di.unrecognized).toBytes() = nil
|
||||
}
|
||||
}
|
||||
|
||||
func (di *discardInfo) computeDiscardInfo() {
|
||||
di.lock.Lock()
|
||||
defer di.lock.Unlock()
|
||||
if di.initialized != 0 {
|
||||
return
|
||||
}
|
||||
t := di.typ
|
||||
n := t.NumField()
|
||||
|
||||
for i := 0; i < n; i++ {
|
||||
f := t.Field(i)
|
||||
if strings.HasPrefix(f.Name, "XXX_") {
|
||||
continue
|
||||
}
|
||||
|
||||
dfi := discardFieldInfo{field: toField(&f)}
|
||||
tf := f.Type
|
||||
|
||||
// Unwrap tf to get its most basic type.
|
||||
var isPointer, isSlice bool
|
||||
if tf.Kind() == reflect.Slice && tf.Elem().Kind() != reflect.Uint8 {
|
||||
isSlice = true
|
||||
tf = tf.Elem()
|
||||
}
|
||||
if tf.Kind() == reflect.Ptr {
|
||||
isPointer = true
|
||||
tf = tf.Elem()
|
||||
}
|
||||
if isPointer && isSlice && tf.Kind() != reflect.Struct {
|
||||
panic(fmt.Sprintf("%v.%s cannot be a slice of pointers to primitive types", t, f.Name))
|
||||
}
|
||||
|
||||
switch tf.Kind() {
|
||||
case reflect.Struct:
|
||||
switch {
|
||||
case !isPointer:
|
||||
panic(fmt.Sprintf("%v.%s cannot be a direct struct value", t, f.Name))
|
||||
case isSlice: // E.g., []*pb.T
|
||||
di := getDiscardInfo(tf)
|
||||
dfi.discard = func(src pointer) {
|
||||
sps := src.getPointerSlice()
|
||||
for _, sp := range sps {
|
||||
if !sp.isNil() {
|
||||
di.discard(sp)
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // E.g., *pb.T
|
||||
di := getDiscardInfo(tf)
|
||||
dfi.discard = func(src pointer) {
|
||||
sp := src.getPointer()
|
||||
if !sp.isNil() {
|
||||
di.discard(sp)
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Map:
|
||||
switch {
|
||||
case isPointer || isSlice:
|
||||
panic(fmt.Sprintf("%v.%s cannot be a pointer to a map or a slice of map values", t, f.Name))
|
||||
default: // E.g., map[K]V
|
||||
if tf.Elem().Kind() == reflect.Ptr { // Proto struct (e.g., *T)
|
||||
dfi.discard = func(src pointer) {
|
||||
sm := src.asPointerTo(tf).Elem()
|
||||
if sm.Len() == 0 {
|
||||
return
|
||||
}
|
||||
for _, key := range sm.MapKeys() {
|
||||
val := sm.MapIndex(key)
|
||||
DiscardUnknown(val.Interface().(Message))
|
||||
}
|
||||
}
|
||||
} else {
|
||||
dfi.discard = func(pointer) {} // Noop
|
||||
}
|
||||
}
|
||||
case reflect.Interface:
|
||||
// Must be oneof field.
|
||||
switch {
|
||||
case isPointer || isSlice:
|
||||
panic(fmt.Sprintf("%v.%s cannot be a pointer to a interface or a slice of interface values", t, f.Name))
|
||||
default: // E.g., interface{}
|
||||
// TODO: Make this faster?
|
||||
dfi.discard = func(src pointer) {
|
||||
su := src.asPointerTo(tf).Elem()
|
||||
if !su.IsNil() {
|
||||
sv := su.Elem().Elem().Field(0)
|
||||
if sv.Kind() == reflect.Ptr && sv.IsNil() {
|
||||
return
|
||||
}
|
||||
switch sv.Type().Kind() {
|
||||
case reflect.Ptr: // Proto struct (e.g., *T)
|
||||
DiscardUnknown(sv.Interface().(Message))
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
default:
|
||||
continue
|
||||
}
|
||||
di.fields = append(di.fields, dfi)
|
||||
}
|
||||
|
||||
di.unrecognized = invalidField
|
||||
if f, ok := t.FieldByName("XXX_unrecognized"); ok {
|
||||
if f.Type != reflect.TypeOf([]byte{}) {
|
||||
panic("expected XXX_unrecognized to be of type []byte")
|
||||
}
|
||||
di.unrecognized = toField(&f)
|
||||
}
|
||||
|
||||
atomic.StoreInt32(&di.initialized, 1)
|
||||
}
|
||||
|
||||
func discardLegacy(m Message) {
|
||||
v := reflect.ValueOf(m)
|
||||
if v.Kind() != reflect.Ptr || v.IsNil() {
|
||||
return
|
||||
}
|
||||
v = v.Elem()
|
||||
if v.Kind() != reflect.Struct {
|
||||
return
|
||||
}
|
||||
t := v.Type()
|
||||
|
||||
for i := 0; i < v.NumField(); i++ {
|
||||
f := t.Field(i)
|
||||
if strings.HasPrefix(f.Name, "XXX_") {
|
||||
continue
|
||||
}
|
||||
vf := v.Field(i)
|
||||
tf := f.Type
|
||||
|
||||
// Unwrap tf to get its most basic type.
|
||||
var isPointer, isSlice bool
|
||||
if tf.Kind() == reflect.Slice && tf.Elem().Kind() != reflect.Uint8 {
|
||||
isSlice = true
|
||||
tf = tf.Elem()
|
||||
}
|
||||
if tf.Kind() == reflect.Ptr {
|
||||
isPointer = true
|
||||
tf = tf.Elem()
|
||||
}
|
||||
if isPointer && isSlice && tf.Kind() != reflect.Struct {
|
||||
panic(fmt.Sprintf("%T.%s cannot be a slice of pointers to primitive types", m, f.Name))
|
||||
}
|
||||
|
||||
switch tf.Kind() {
|
||||
case reflect.Struct:
|
||||
switch {
|
||||
case !isPointer:
|
||||
panic(fmt.Sprintf("%T.%s cannot be a direct struct value", m, f.Name))
|
||||
case isSlice: // E.g., []*pb.T
|
||||
for j := 0; j < vf.Len(); j++ {
|
||||
discardLegacy(vf.Index(j).Interface().(Message))
|
||||
}
|
||||
default: // E.g., *pb.T
|
||||
discardLegacy(vf.Interface().(Message))
|
||||
}
|
||||
case reflect.Map:
|
||||
switch {
|
||||
case isPointer || isSlice:
|
||||
panic(fmt.Sprintf("%T.%s cannot be a pointer to a map or a slice of map values", m, f.Name))
|
||||
default: // E.g., map[K]V
|
||||
tv := vf.Type().Elem()
|
||||
if tv.Kind() == reflect.Ptr && tv.Implements(protoMessageType) { // Proto struct (e.g., *T)
|
||||
for _, key := range vf.MapKeys() {
|
||||
val := vf.MapIndex(key)
|
||||
discardLegacy(val.Interface().(Message))
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Interface:
|
||||
// Must be oneof field.
|
||||
switch {
|
||||
case isPointer || isSlice:
|
||||
panic(fmt.Sprintf("%T.%s cannot be a pointer to a interface or a slice of interface values", m, f.Name))
|
||||
default: // E.g., test_proto.isCommunique_Union interface
|
||||
if !vf.IsNil() && f.Tag.Get("protobuf_oneof") != "" {
|
||||
vf = vf.Elem() // E.g., *test_proto.Communique_Msg
|
||||
if !vf.IsNil() {
|
||||
vf = vf.Elem() // E.g., test_proto.Communique_Msg
|
||||
vf = vf.Field(0) // E.g., Proto struct (e.g., *T) or primitive value
|
||||
if vf.Kind() == reflect.Ptr {
|
||||
discardLegacy(vf.Interface().(Message))
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if vf := v.FieldByName("XXX_unrecognized"); vf.IsValid() {
|
||||
if vf.Type() != reflect.TypeOf([]byte{}) {
|
||||
panic("expected XXX_unrecognized to be of type []byte")
|
||||
}
|
||||
vf.Set(reflect.ValueOf([]byte(nil)))
|
||||
}
|
||||
|
||||
// For proto2 messages, only discard unknown fields in message extensions
|
||||
// that have been accessed via GetExtension.
|
||||
if em, err := extendable(m); err == nil {
|
||||
// Ignore lock since discardLegacy is not concurrency safe.
|
||||
emm, _ := em.extensionsRead()
|
||||
for _, mx := range emm {
|
||||
if m, ok := mx.value.(Message); ok {
|
||||
discardLegacy(m)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
203
watchdog/vendor/github.com/golang/protobuf/proto/encode.go
generated
vendored
203
watchdog/vendor/github.com/golang/protobuf/proto/encode.go
generated
vendored
@ -1,203 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2010 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
package proto
|
||||
|
||||
/*
|
||||
* Routines for encoding data into the wire format for protocol buffers.
|
||||
*/
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"reflect"
|
||||
)
|
||||
|
||||
var (
|
||||
// errRepeatedHasNil is the error returned if Marshal is called with
|
||||
// a struct with a repeated field containing a nil element.
|
||||
errRepeatedHasNil = errors.New("proto: repeated field has nil element")
|
||||
|
||||
// errOneofHasNil is the error returned if Marshal is called with
|
||||
// a struct with a oneof field containing a nil element.
|
||||
errOneofHasNil = errors.New("proto: oneof field has nil value")
|
||||
|
||||
// ErrNil is the error returned if Marshal is called with nil.
|
||||
ErrNil = errors.New("proto: Marshal called with nil")
|
||||
|
||||
// ErrTooLarge is the error returned if Marshal is called with a
|
||||
// message that encodes to >2GB.
|
||||
ErrTooLarge = errors.New("proto: message encodes to over 2 GB")
|
||||
)
|
||||
|
||||
// The fundamental encoders that put bytes on the wire.
|
||||
// Those that take integer types all accept uint64 and are
|
||||
// therefore of type valueEncoder.
|
||||
|
||||
const maxVarintBytes = 10 // maximum length of a varint
|
||||
|
||||
// EncodeVarint returns the varint encoding of x.
|
||||
// This is the format for the
|
||||
// int32, int64, uint32, uint64, bool, and enum
|
||||
// protocol buffer types.
|
||||
// Not used by the package itself, but helpful to clients
|
||||
// wishing to use the same encoding.
|
||||
func EncodeVarint(x uint64) []byte {
|
||||
var buf [maxVarintBytes]byte
|
||||
var n int
|
||||
for n = 0; x > 127; n++ {
|
||||
buf[n] = 0x80 | uint8(x&0x7F)
|
||||
x >>= 7
|
||||
}
|
||||
buf[n] = uint8(x)
|
||||
n++
|
||||
return buf[0:n]
|
||||
}
|
||||
|
||||
// EncodeVarint writes a varint-encoded integer to the Buffer.
|
||||
// This is the format for the
|
||||
// int32, int64, uint32, uint64, bool, and enum
|
||||
// protocol buffer types.
|
||||
func (p *Buffer) EncodeVarint(x uint64) error {
|
||||
for x >= 1<<7 {
|
||||
p.buf = append(p.buf, uint8(x&0x7f|0x80))
|
||||
x >>= 7
|
||||
}
|
||||
p.buf = append(p.buf, uint8(x))
|
||||
return nil
|
||||
}
|
||||
|
||||
// SizeVarint returns the varint encoding size of an integer.
|
||||
func SizeVarint(x uint64) int {
|
||||
switch {
|
||||
case x < 1<<7:
|
||||
return 1
|
||||
case x < 1<<14:
|
||||
return 2
|
||||
case x < 1<<21:
|
||||
return 3
|
||||
case x < 1<<28:
|
||||
return 4
|
||||
case x < 1<<35:
|
||||
return 5
|
||||
case x < 1<<42:
|
||||
return 6
|
||||
case x < 1<<49:
|
||||
return 7
|
||||
case x < 1<<56:
|
||||
return 8
|
||||
case x < 1<<63:
|
||||
return 9
|
||||
}
|
||||
return 10
|
||||
}
|
||||
|
||||
// EncodeFixed64 writes a 64-bit integer to the Buffer.
|
||||
// This is the format for the
|
||||
// fixed64, sfixed64, and double protocol buffer types.
|
||||
func (p *Buffer) EncodeFixed64(x uint64) error {
|
||||
p.buf = append(p.buf,
|
||||
uint8(x),
|
||||
uint8(x>>8),
|
||||
uint8(x>>16),
|
||||
uint8(x>>24),
|
||||
uint8(x>>32),
|
||||
uint8(x>>40),
|
||||
uint8(x>>48),
|
||||
uint8(x>>56))
|
||||
return nil
|
||||
}
|
||||
|
||||
// EncodeFixed32 writes a 32-bit integer to the Buffer.
|
||||
// This is the format for the
|
||||
// fixed32, sfixed32, and float protocol buffer types.
|
||||
func (p *Buffer) EncodeFixed32(x uint64) error {
|
||||
p.buf = append(p.buf,
|
||||
uint8(x),
|
||||
uint8(x>>8),
|
||||
uint8(x>>16),
|
||||
uint8(x>>24))
|
||||
return nil
|
||||
}
|
||||
|
||||
// EncodeZigzag64 writes a zigzag-encoded 64-bit integer
|
||||
// to the Buffer.
|
||||
// This is the format used for the sint64 protocol buffer type.
|
||||
func (p *Buffer) EncodeZigzag64(x uint64) error {
|
||||
// use signed number to get arithmetic right shift.
|
||||
return p.EncodeVarint(uint64((x << 1) ^ uint64((int64(x) >> 63))))
|
||||
}
|
||||
|
||||
// EncodeZigzag32 writes a zigzag-encoded 32-bit integer
|
||||
// to the Buffer.
|
||||
// This is the format used for the sint32 protocol buffer type.
|
||||
func (p *Buffer) EncodeZigzag32(x uint64) error {
|
||||
// use signed number to get arithmetic right shift.
|
||||
return p.EncodeVarint(uint64((uint32(x) << 1) ^ uint32((int32(x) >> 31))))
|
||||
}
|
||||
|
||||
// EncodeRawBytes writes a count-delimited byte buffer to the Buffer.
|
||||
// This is the format used for the bytes protocol buffer
|
||||
// type and for embedded messages.
|
||||
func (p *Buffer) EncodeRawBytes(b []byte) error {
|
||||
p.EncodeVarint(uint64(len(b)))
|
||||
p.buf = append(p.buf, b...)
|
||||
return nil
|
||||
}
|
||||
|
||||
// EncodeStringBytes writes an encoded string to the Buffer.
|
||||
// This is the format used for the proto2 string type.
|
||||
func (p *Buffer) EncodeStringBytes(s string) error {
|
||||
p.EncodeVarint(uint64(len(s)))
|
||||
p.buf = append(p.buf, s...)
|
||||
return nil
|
||||
}
|
||||
|
||||
// Marshaler is the interface representing objects that can marshal themselves.
|
||||
type Marshaler interface {
|
||||
Marshal() ([]byte, error)
|
||||
}
|
||||
|
||||
// EncodeMessage writes the protocol buffer to the Buffer,
|
||||
// prefixed by a varint-encoded length.
|
||||
func (p *Buffer) EncodeMessage(pb Message) error {
|
||||
siz := Size(pb)
|
||||
p.EncodeVarint(uint64(siz))
|
||||
return p.Marshal(pb)
|
||||
}
|
||||
|
||||
// All protocol buffer fields are nillable, but be careful.
|
||||
func isNil(v reflect.Value) bool {
|
||||
switch v.Kind() {
|
||||
case reflect.Interface, reflect.Map, reflect.Ptr, reflect.Slice:
|
||||
return v.IsNil()
|
||||
}
|
||||
return false
|
||||
}
|
||||
301
watchdog/vendor/github.com/golang/protobuf/proto/equal.go
generated
vendored
301
watchdog/vendor/github.com/golang/protobuf/proto/equal.go
generated
vendored
@ -1,301 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2011 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
// Protocol buffer comparison.
|
||||
|
||||
package proto
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"log"
|
||||
"reflect"
|
||||
"strings"
|
||||
)
|
||||
|
||||
/*
|
||||
Equal returns true iff protocol buffers a and b are equal.
|
||||
The arguments must both be pointers to protocol buffer structs.
|
||||
|
||||
Equality is defined in this way:
|
||||
- Two messages are equal iff they are the same type,
|
||||
corresponding fields are equal, unknown field sets
|
||||
are equal, and extensions sets are equal.
|
||||
- Two set scalar fields are equal iff their values are equal.
|
||||
If the fields are of a floating-point type, remember that
|
||||
NaN != x for all x, including NaN. If the message is defined
|
||||
in a proto3 .proto file, fields are not "set"; specifically,
|
||||
zero length proto3 "bytes" fields are equal (nil == {}).
|
||||
- Two repeated fields are equal iff their lengths are the same,
|
||||
and their corresponding elements are equal. Note a "bytes" field,
|
||||
although represented by []byte, is not a repeated field and the
|
||||
rule for the scalar fields described above applies.
|
||||
- Two unset fields are equal.
|
||||
- Two unknown field sets are equal if their current
|
||||
encoded state is equal.
|
||||
- Two extension sets are equal iff they have corresponding
|
||||
elements that are pairwise equal.
|
||||
- Two map fields are equal iff their lengths are the same,
|
||||
and they contain the same set of elements. Zero-length map
|
||||
fields are equal.
|
||||
- Every other combination of things are not equal.
|
||||
|
||||
The return value is undefined if a and b are not protocol buffers.
|
||||
*/
|
||||
func Equal(a, b Message) bool {
|
||||
if a == nil || b == nil {
|
||||
return a == b
|
||||
}
|
||||
v1, v2 := reflect.ValueOf(a), reflect.ValueOf(b)
|
||||
if v1.Type() != v2.Type() {
|
||||
return false
|
||||
}
|
||||
if v1.Kind() == reflect.Ptr {
|
||||
if v1.IsNil() {
|
||||
return v2.IsNil()
|
||||
}
|
||||
if v2.IsNil() {
|
||||
return false
|
||||
}
|
||||
v1, v2 = v1.Elem(), v2.Elem()
|
||||
}
|
||||
if v1.Kind() != reflect.Struct {
|
||||
return false
|
||||
}
|
||||
return equalStruct(v1, v2)
|
||||
}
|
||||
|
||||
// v1 and v2 are known to have the same type.
|
||||
func equalStruct(v1, v2 reflect.Value) bool {
|
||||
sprop := GetProperties(v1.Type())
|
||||
for i := 0; i < v1.NumField(); i++ {
|
||||
f := v1.Type().Field(i)
|
||||
if strings.HasPrefix(f.Name, "XXX_") {
|
||||
continue
|
||||
}
|
||||
f1, f2 := v1.Field(i), v2.Field(i)
|
||||
if f.Type.Kind() == reflect.Ptr {
|
||||
if n1, n2 := f1.IsNil(), f2.IsNil(); n1 && n2 {
|
||||
// both unset
|
||||
continue
|
||||
} else if n1 != n2 {
|
||||
// set/unset mismatch
|
||||
return false
|
||||
}
|
||||
f1, f2 = f1.Elem(), f2.Elem()
|
||||
}
|
||||
if !equalAny(f1, f2, sprop.Prop[i]) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
if em1 := v1.FieldByName("XXX_InternalExtensions"); em1.IsValid() {
|
||||
em2 := v2.FieldByName("XXX_InternalExtensions")
|
||||
if !equalExtensions(v1.Type(), em1.Interface().(XXX_InternalExtensions), em2.Interface().(XXX_InternalExtensions)) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
if em1 := v1.FieldByName("XXX_extensions"); em1.IsValid() {
|
||||
em2 := v2.FieldByName("XXX_extensions")
|
||||
if !equalExtMap(v1.Type(), em1.Interface().(map[int32]Extension), em2.Interface().(map[int32]Extension)) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
uf := v1.FieldByName("XXX_unrecognized")
|
||||
if !uf.IsValid() {
|
||||
return true
|
||||
}
|
||||
|
||||
u1 := uf.Bytes()
|
||||
u2 := v2.FieldByName("XXX_unrecognized").Bytes()
|
||||
return bytes.Equal(u1, u2)
|
||||
}
|
||||
|
||||
// v1 and v2 are known to have the same type.
|
||||
// prop may be nil.
|
||||
func equalAny(v1, v2 reflect.Value, prop *Properties) bool {
|
||||
if v1.Type() == protoMessageType {
|
||||
m1, _ := v1.Interface().(Message)
|
||||
m2, _ := v2.Interface().(Message)
|
||||
return Equal(m1, m2)
|
||||
}
|
||||
switch v1.Kind() {
|
||||
case reflect.Bool:
|
||||
return v1.Bool() == v2.Bool()
|
||||
case reflect.Float32, reflect.Float64:
|
||||
return v1.Float() == v2.Float()
|
||||
case reflect.Int32, reflect.Int64:
|
||||
return v1.Int() == v2.Int()
|
||||
case reflect.Interface:
|
||||
// Probably a oneof field; compare the inner values.
|
||||
n1, n2 := v1.IsNil(), v2.IsNil()
|
||||
if n1 || n2 {
|
||||
return n1 == n2
|
||||
}
|
||||
e1, e2 := v1.Elem(), v2.Elem()
|
||||
if e1.Type() != e2.Type() {
|
||||
return false
|
||||
}
|
||||
return equalAny(e1, e2, nil)
|
||||
case reflect.Map:
|
||||
if v1.Len() != v2.Len() {
|
||||
return false
|
||||
}
|
||||
for _, key := range v1.MapKeys() {
|
||||
val2 := v2.MapIndex(key)
|
||||
if !val2.IsValid() {
|
||||
// This key was not found in the second map.
|
||||
return false
|
||||
}
|
||||
if !equalAny(v1.MapIndex(key), val2, nil) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
case reflect.Ptr:
|
||||
// Maps may have nil values in them, so check for nil.
|
||||
if v1.IsNil() && v2.IsNil() {
|
||||
return true
|
||||
}
|
||||
if v1.IsNil() != v2.IsNil() {
|
||||
return false
|
||||
}
|
||||
return equalAny(v1.Elem(), v2.Elem(), prop)
|
||||
case reflect.Slice:
|
||||
if v1.Type().Elem().Kind() == reflect.Uint8 {
|
||||
// short circuit: []byte
|
||||
|
||||
// Edge case: if this is in a proto3 message, a zero length
|
||||
// bytes field is considered the zero value.
|
||||
if prop != nil && prop.proto3 && v1.Len() == 0 && v2.Len() == 0 {
|
||||
return true
|
||||
}
|
||||
if v1.IsNil() != v2.IsNil() {
|
||||
return false
|
||||
}
|
||||
return bytes.Equal(v1.Interface().([]byte), v2.Interface().([]byte))
|
||||
}
|
||||
|
||||
if v1.Len() != v2.Len() {
|
||||
return false
|
||||
}
|
||||
for i := 0; i < v1.Len(); i++ {
|
||||
if !equalAny(v1.Index(i), v2.Index(i), prop) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
case reflect.String:
|
||||
return v1.Interface().(string) == v2.Interface().(string)
|
||||
case reflect.Struct:
|
||||
return equalStruct(v1, v2)
|
||||
case reflect.Uint32, reflect.Uint64:
|
||||
return v1.Uint() == v2.Uint()
|
||||
}
|
||||
|
||||
// unknown type, so not a protocol buffer
|
||||
log.Printf("proto: don't know how to compare %v", v1)
|
||||
return false
|
||||
}
|
||||
|
||||
// base is the struct type that the extensions are based on.
|
||||
// x1 and x2 are InternalExtensions.
|
||||
func equalExtensions(base reflect.Type, x1, x2 XXX_InternalExtensions) bool {
|
||||
em1, _ := x1.extensionsRead()
|
||||
em2, _ := x2.extensionsRead()
|
||||
return equalExtMap(base, em1, em2)
|
||||
}
|
||||
|
||||
func equalExtMap(base reflect.Type, em1, em2 map[int32]Extension) bool {
|
||||
if len(em1) != len(em2) {
|
||||
return false
|
||||
}
|
||||
|
||||
for extNum, e1 := range em1 {
|
||||
e2, ok := em2[extNum]
|
||||
if !ok {
|
||||
return false
|
||||
}
|
||||
|
||||
m1 := extensionAsLegacyType(e1.value)
|
||||
m2 := extensionAsLegacyType(e2.value)
|
||||
|
||||
if m1 == nil && m2 == nil {
|
||||
// Both have only encoded form.
|
||||
if bytes.Equal(e1.enc, e2.enc) {
|
||||
continue
|
||||
}
|
||||
// The bytes are different, but the extensions might still be
|
||||
// equal. We need to decode them to compare.
|
||||
}
|
||||
|
||||
if m1 != nil && m2 != nil {
|
||||
// Both are unencoded.
|
||||
if !equalAny(reflect.ValueOf(m1), reflect.ValueOf(m2), nil) {
|
||||
return false
|
||||
}
|
||||
continue
|
||||
}
|
||||
|
||||
// At least one is encoded. To do a semantically correct comparison
|
||||
// we need to unmarshal them first.
|
||||
var desc *ExtensionDesc
|
||||
if m := extensionMaps[base]; m != nil {
|
||||
desc = m[extNum]
|
||||
}
|
||||
if desc == nil {
|
||||
// If both have only encoded form and the bytes are the same,
|
||||
// it is handled above. We get here when the bytes are different.
|
||||
// We don't know how to decode it, so just compare them as byte
|
||||
// slices.
|
||||
log.Printf("proto: don't know how to compare extension %d of %v", extNum, base)
|
||||
return false
|
||||
}
|
||||
var err error
|
||||
if m1 == nil {
|
||||
m1, err = decodeExtension(e1.enc, desc)
|
||||
}
|
||||
if m2 == nil && err == nil {
|
||||
m2, err = decodeExtension(e2.enc, desc)
|
||||
}
|
||||
if err != nil {
|
||||
// The encoded form is invalid.
|
||||
log.Printf("proto: badly encoded extension %d of %v: %v", extNum, base, err)
|
||||
return false
|
||||
}
|
||||
if !equalAny(reflect.ValueOf(m1), reflect.ValueOf(m2), nil) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
return true
|
||||
}
|
||||
607
watchdog/vendor/github.com/golang/protobuf/proto/extensions.go
generated
vendored
607
watchdog/vendor/github.com/golang/protobuf/proto/extensions.go
generated
vendored
@ -1,607 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2010 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
package proto
|
||||
|
||||
/*
|
||||
* Types and routines for supporting protocol buffer extensions.
|
||||
*/
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
"io"
|
||||
"reflect"
|
||||
"strconv"
|
||||
"sync"
|
||||
)
|
||||
|
||||
// ErrMissingExtension is the error returned by GetExtension if the named extension is not in the message.
|
||||
var ErrMissingExtension = errors.New("proto: missing extension")
|
||||
|
||||
// ExtensionRange represents a range of message extensions for a protocol buffer.
|
||||
// Used in code generated by the protocol compiler.
|
||||
type ExtensionRange struct {
|
||||
Start, End int32 // both inclusive
|
||||
}
|
||||
|
||||
// extendableProto is an interface implemented by any protocol buffer generated by the current
|
||||
// proto compiler that may be extended.
|
||||
type extendableProto interface {
|
||||
Message
|
||||
ExtensionRangeArray() []ExtensionRange
|
||||
extensionsWrite() map[int32]Extension
|
||||
extensionsRead() (map[int32]Extension, sync.Locker)
|
||||
}
|
||||
|
||||
// extendableProtoV1 is an interface implemented by a protocol buffer generated by the previous
|
||||
// version of the proto compiler that may be extended.
|
||||
type extendableProtoV1 interface {
|
||||
Message
|
||||
ExtensionRangeArray() []ExtensionRange
|
||||
ExtensionMap() map[int32]Extension
|
||||
}
|
||||
|
||||
// extensionAdapter is a wrapper around extendableProtoV1 that implements extendableProto.
|
||||
type extensionAdapter struct {
|
||||
extendableProtoV1
|
||||
}
|
||||
|
||||
func (e extensionAdapter) extensionsWrite() map[int32]Extension {
|
||||
return e.ExtensionMap()
|
||||
}
|
||||
|
||||
func (e extensionAdapter) extensionsRead() (map[int32]Extension, sync.Locker) {
|
||||
return e.ExtensionMap(), notLocker{}
|
||||
}
|
||||
|
||||
// notLocker is a sync.Locker whose Lock and Unlock methods are nops.
|
||||
type notLocker struct{}
|
||||
|
||||
func (n notLocker) Lock() {}
|
||||
func (n notLocker) Unlock() {}
|
||||
|
||||
// extendable returns the extendableProto interface for the given generated proto message.
|
||||
// If the proto message has the old extension format, it returns a wrapper that implements
|
||||
// the extendableProto interface.
|
||||
func extendable(p interface{}) (extendableProto, error) {
|
||||
switch p := p.(type) {
|
||||
case extendableProto:
|
||||
if isNilPtr(p) {
|
||||
return nil, fmt.Errorf("proto: nil %T is not extendable", p)
|
||||
}
|
||||
return p, nil
|
||||
case extendableProtoV1:
|
||||
if isNilPtr(p) {
|
||||
return nil, fmt.Errorf("proto: nil %T is not extendable", p)
|
||||
}
|
||||
return extensionAdapter{p}, nil
|
||||
}
|
||||
// Don't allocate a specific error containing %T:
|
||||
// this is the hot path for Clone and MarshalText.
|
||||
return nil, errNotExtendable
|
||||
}
|
||||
|
||||
var errNotExtendable = errors.New("proto: not an extendable proto.Message")
|
||||
|
||||
func isNilPtr(x interface{}) bool {
|
||||
v := reflect.ValueOf(x)
|
||||
return v.Kind() == reflect.Ptr && v.IsNil()
|
||||
}
|
||||
|
||||
// XXX_InternalExtensions is an internal representation of proto extensions.
|
||||
//
|
||||
// Each generated message struct type embeds an anonymous XXX_InternalExtensions field,
|
||||
// thus gaining the unexported 'extensions' method, which can be called only from the proto package.
|
||||
//
|
||||
// The methods of XXX_InternalExtensions are not concurrency safe in general,
|
||||
// but calls to logically read-only methods such as has and get may be executed concurrently.
|
||||
type XXX_InternalExtensions struct {
|
||||
// The struct must be indirect so that if a user inadvertently copies a
|
||||
// generated message and its embedded XXX_InternalExtensions, they
|
||||
// avoid the mayhem of a copied mutex.
|
||||
//
|
||||
// The mutex serializes all logically read-only operations to p.extensionMap.
|
||||
// It is up to the client to ensure that write operations to p.extensionMap are
|
||||
// mutually exclusive with other accesses.
|
||||
p *struct {
|
||||
mu sync.Mutex
|
||||
extensionMap map[int32]Extension
|
||||
}
|
||||
}
|
||||
|
||||
// extensionsWrite returns the extension map, creating it on first use.
|
||||
func (e *XXX_InternalExtensions) extensionsWrite() map[int32]Extension {
|
||||
if e.p == nil {
|
||||
e.p = new(struct {
|
||||
mu sync.Mutex
|
||||
extensionMap map[int32]Extension
|
||||
})
|
||||
e.p.extensionMap = make(map[int32]Extension)
|
||||
}
|
||||
return e.p.extensionMap
|
||||
}
|
||||
|
||||
// extensionsRead returns the extensions map for read-only use. It may be nil.
|
||||
// The caller must hold the returned mutex's lock when accessing Elements within the map.
|
||||
func (e *XXX_InternalExtensions) extensionsRead() (map[int32]Extension, sync.Locker) {
|
||||
if e.p == nil {
|
||||
return nil, nil
|
||||
}
|
||||
return e.p.extensionMap, &e.p.mu
|
||||
}
|
||||
|
||||
// ExtensionDesc represents an extension specification.
|
||||
// Used in generated code from the protocol compiler.
|
||||
type ExtensionDesc struct {
|
||||
ExtendedType Message // nil pointer to the type that is being extended
|
||||
ExtensionType interface{} // nil pointer to the extension type
|
||||
Field int32 // field number
|
||||
Name string // fully-qualified name of extension, for text formatting
|
||||
Tag string // protobuf tag style
|
||||
Filename string // name of the file in which the extension is defined
|
||||
}
|
||||
|
||||
func (ed *ExtensionDesc) repeated() bool {
|
||||
t := reflect.TypeOf(ed.ExtensionType)
|
||||
return t.Kind() == reflect.Slice && t.Elem().Kind() != reflect.Uint8
|
||||
}
|
||||
|
||||
// Extension represents an extension in a message.
|
||||
type Extension struct {
|
||||
// When an extension is stored in a message using SetExtension
|
||||
// only desc and value are set. When the message is marshaled
|
||||
// enc will be set to the encoded form of the message.
|
||||
//
|
||||
// When a message is unmarshaled and contains extensions, each
|
||||
// extension will have only enc set. When such an extension is
|
||||
// accessed using GetExtension (or GetExtensions) desc and value
|
||||
// will be set.
|
||||
desc *ExtensionDesc
|
||||
|
||||
// value is a concrete value for the extension field. Let the type of
|
||||
// desc.ExtensionType be the "API type" and the type of Extension.value
|
||||
// be the "storage type". The API type and storage type are the same except:
|
||||
// * For scalars (except []byte), the API type uses *T,
|
||||
// while the storage type uses T.
|
||||
// * For repeated fields, the API type uses []T, while the storage type
|
||||
// uses *[]T.
|
||||
//
|
||||
// The reason for the divergence is so that the storage type more naturally
|
||||
// matches what is expected of when retrieving the values through the
|
||||
// protobuf reflection APIs.
|
||||
//
|
||||
// The value may only be populated if desc is also populated.
|
||||
value interface{}
|
||||
|
||||
// enc is the raw bytes for the extension field.
|
||||
enc []byte
|
||||
}
|
||||
|
||||
// SetRawExtension is for testing only.
|
||||
func SetRawExtension(base Message, id int32, b []byte) {
|
||||
epb, err := extendable(base)
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
extmap := epb.extensionsWrite()
|
||||
extmap[id] = Extension{enc: b}
|
||||
}
|
||||
|
||||
// isExtensionField returns true iff the given field number is in an extension range.
|
||||
func isExtensionField(pb extendableProto, field int32) bool {
|
||||
for _, er := range pb.ExtensionRangeArray() {
|
||||
if er.Start <= field && field <= er.End {
|
||||
return true
|
||||
}
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
// checkExtensionTypes checks that the given extension is valid for pb.
|
||||
func checkExtensionTypes(pb extendableProto, extension *ExtensionDesc) error {
|
||||
var pbi interface{} = pb
|
||||
// Check the extended type.
|
||||
if ea, ok := pbi.(extensionAdapter); ok {
|
||||
pbi = ea.extendableProtoV1
|
||||
}
|
||||
if a, b := reflect.TypeOf(pbi), reflect.TypeOf(extension.ExtendedType); a != b {
|
||||
return fmt.Errorf("proto: bad extended type; %v does not extend %v", b, a)
|
||||
}
|
||||
// Check the range.
|
||||
if !isExtensionField(pb, extension.Field) {
|
||||
return errors.New("proto: bad extension number; not in declared ranges")
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// extPropKey is sufficient to uniquely identify an extension.
|
||||
type extPropKey struct {
|
||||
base reflect.Type
|
||||
field int32
|
||||
}
|
||||
|
||||
var extProp = struct {
|
||||
sync.RWMutex
|
||||
m map[extPropKey]*Properties
|
||||
}{
|
||||
m: make(map[extPropKey]*Properties),
|
||||
}
|
||||
|
||||
func extensionProperties(ed *ExtensionDesc) *Properties {
|
||||
key := extPropKey{base: reflect.TypeOf(ed.ExtendedType), field: ed.Field}
|
||||
|
||||
extProp.RLock()
|
||||
if prop, ok := extProp.m[key]; ok {
|
||||
extProp.RUnlock()
|
||||
return prop
|
||||
}
|
||||
extProp.RUnlock()
|
||||
|
||||
extProp.Lock()
|
||||
defer extProp.Unlock()
|
||||
// Check again.
|
||||
if prop, ok := extProp.m[key]; ok {
|
||||
return prop
|
||||
}
|
||||
|
||||
prop := new(Properties)
|
||||
prop.Init(reflect.TypeOf(ed.ExtensionType), "unknown_name", ed.Tag, nil)
|
||||
extProp.m[key] = prop
|
||||
return prop
|
||||
}
|
||||
|
||||
// HasExtension returns whether the given extension is present in pb.
|
||||
func HasExtension(pb Message, extension *ExtensionDesc) bool {
|
||||
// TODO: Check types, field numbers, etc.?
|
||||
epb, err := extendable(pb)
|
||||
if err != nil {
|
||||
return false
|
||||
}
|
||||
extmap, mu := epb.extensionsRead()
|
||||
if extmap == nil {
|
||||
return false
|
||||
}
|
||||
mu.Lock()
|
||||
_, ok := extmap[extension.Field]
|
||||
mu.Unlock()
|
||||
return ok
|
||||
}
|
||||
|
||||
// ClearExtension removes the given extension from pb.
|
||||
func ClearExtension(pb Message, extension *ExtensionDesc) {
|
||||
epb, err := extendable(pb)
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
// TODO: Check types, field numbers, etc.?
|
||||
extmap := epb.extensionsWrite()
|
||||
delete(extmap, extension.Field)
|
||||
}
|
||||
|
||||
// GetExtension retrieves a proto2 extended field from pb.
|
||||
//
|
||||
// If the descriptor is type complete (i.e., ExtensionDesc.ExtensionType is non-nil),
|
||||
// then GetExtension parses the encoded field and returns a Go value of the specified type.
|
||||
// If the field is not present, then the default value is returned (if one is specified),
|
||||
// otherwise ErrMissingExtension is reported.
|
||||
//
|
||||
// If the descriptor is not type complete (i.e., ExtensionDesc.ExtensionType is nil),
|
||||
// then GetExtension returns the raw encoded bytes of the field extension.
|
||||
func GetExtension(pb Message, extension *ExtensionDesc) (interface{}, error) {
|
||||
epb, err := extendable(pb)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
if extension.ExtendedType != nil {
|
||||
// can only check type if this is a complete descriptor
|
||||
if err := checkExtensionTypes(epb, extension); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
}
|
||||
|
||||
emap, mu := epb.extensionsRead()
|
||||
if emap == nil {
|
||||
return defaultExtensionValue(extension)
|
||||
}
|
||||
mu.Lock()
|
||||
defer mu.Unlock()
|
||||
e, ok := emap[extension.Field]
|
||||
if !ok {
|
||||
// defaultExtensionValue returns the default value or
|
||||
// ErrMissingExtension if there is no default.
|
||||
return defaultExtensionValue(extension)
|
||||
}
|
||||
|
||||
if e.value != nil {
|
||||
// Already decoded. Check the descriptor, though.
|
||||
if e.desc != extension {
|
||||
// This shouldn't happen. If it does, it means that
|
||||
// GetExtension was called twice with two different
|
||||
// descriptors with the same field number.
|
||||
return nil, errors.New("proto: descriptor conflict")
|
||||
}
|
||||
return extensionAsLegacyType(e.value), nil
|
||||
}
|
||||
|
||||
if extension.ExtensionType == nil {
|
||||
// incomplete descriptor
|
||||
return e.enc, nil
|
||||
}
|
||||
|
||||
v, err := decodeExtension(e.enc, extension)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// Remember the decoded version and drop the encoded version.
|
||||
// That way it is safe to mutate what we return.
|
||||
e.value = extensionAsStorageType(v)
|
||||
e.desc = extension
|
||||
e.enc = nil
|
||||
emap[extension.Field] = e
|
||||
return extensionAsLegacyType(e.value), nil
|
||||
}
|
||||
|
||||
// defaultExtensionValue returns the default value for extension.
|
||||
// If no default for an extension is defined ErrMissingExtension is returned.
|
||||
func defaultExtensionValue(extension *ExtensionDesc) (interface{}, error) {
|
||||
if extension.ExtensionType == nil {
|
||||
// incomplete descriptor, so no default
|
||||
return nil, ErrMissingExtension
|
||||
}
|
||||
|
||||
t := reflect.TypeOf(extension.ExtensionType)
|
||||
props := extensionProperties(extension)
|
||||
|
||||
sf, _, err := fieldDefault(t, props)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
if sf == nil || sf.value == nil {
|
||||
// There is no default value.
|
||||
return nil, ErrMissingExtension
|
||||
}
|
||||
|
||||
if t.Kind() != reflect.Ptr {
|
||||
// We do not need to return a Ptr, we can directly return sf.value.
|
||||
return sf.value, nil
|
||||
}
|
||||
|
||||
// We need to return an interface{} that is a pointer to sf.value.
|
||||
value := reflect.New(t).Elem()
|
||||
value.Set(reflect.New(value.Type().Elem()))
|
||||
if sf.kind == reflect.Int32 {
|
||||
// We may have an int32 or an enum, but the underlying data is int32.
|
||||
// Since we can't set an int32 into a non int32 reflect.value directly
|
||||
// set it as a int32.
|
||||
value.Elem().SetInt(int64(sf.value.(int32)))
|
||||
} else {
|
||||
value.Elem().Set(reflect.ValueOf(sf.value))
|
||||
}
|
||||
return value.Interface(), nil
|
||||
}
|
||||
|
||||
// decodeExtension decodes an extension encoded in b.
|
||||
func decodeExtension(b []byte, extension *ExtensionDesc) (interface{}, error) {
|
||||
t := reflect.TypeOf(extension.ExtensionType)
|
||||
unmarshal := typeUnmarshaler(t, extension.Tag)
|
||||
|
||||
// t is a pointer to a struct, pointer to basic type or a slice.
|
||||
// Allocate space to store the pointer/slice.
|
||||
value := reflect.New(t).Elem()
|
||||
|
||||
var err error
|
||||
for {
|
||||
x, n := decodeVarint(b)
|
||||
if n == 0 {
|
||||
return nil, io.ErrUnexpectedEOF
|
||||
}
|
||||
b = b[n:]
|
||||
wire := int(x) & 7
|
||||
|
||||
b, err = unmarshal(b, valToPointer(value.Addr()), wire)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
if len(b) == 0 {
|
||||
break
|
||||
}
|
||||
}
|
||||
return value.Interface(), nil
|
||||
}
|
||||
|
||||
// GetExtensions returns a slice of the extensions present in pb that are also listed in es.
|
||||
// The returned slice has the same length as es; missing extensions will appear as nil elements.
|
||||
func GetExtensions(pb Message, es []*ExtensionDesc) (extensions []interface{}, err error) {
|
||||
epb, err := extendable(pb)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
extensions = make([]interface{}, len(es))
|
||||
for i, e := range es {
|
||||
extensions[i], err = GetExtension(epb, e)
|
||||
if err == ErrMissingExtension {
|
||||
err = nil
|
||||
}
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
// ExtensionDescs returns a new slice containing pb's extension descriptors, in undefined order.
|
||||
// For non-registered extensions, ExtensionDescs returns an incomplete descriptor containing
|
||||
// just the Field field, which defines the extension's field number.
|
||||
func ExtensionDescs(pb Message) ([]*ExtensionDesc, error) {
|
||||
epb, err := extendable(pb)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
registeredExtensions := RegisteredExtensions(pb)
|
||||
|
||||
emap, mu := epb.extensionsRead()
|
||||
if emap == nil {
|
||||
return nil, nil
|
||||
}
|
||||
mu.Lock()
|
||||
defer mu.Unlock()
|
||||
extensions := make([]*ExtensionDesc, 0, len(emap))
|
||||
for extid, e := range emap {
|
||||
desc := e.desc
|
||||
if desc == nil {
|
||||
desc = registeredExtensions[extid]
|
||||
if desc == nil {
|
||||
desc = &ExtensionDesc{Field: extid}
|
||||
}
|
||||
}
|
||||
|
||||
extensions = append(extensions, desc)
|
||||
}
|
||||
return extensions, nil
|
||||
}
|
||||
|
||||
// SetExtension sets the specified extension of pb to the specified value.
|
||||
func SetExtension(pb Message, extension *ExtensionDesc, value interface{}) error {
|
||||
epb, err := extendable(pb)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if err := checkExtensionTypes(epb, extension); err != nil {
|
||||
return err
|
||||
}
|
||||
typ := reflect.TypeOf(extension.ExtensionType)
|
||||
if typ != reflect.TypeOf(value) {
|
||||
return fmt.Errorf("proto: bad extension value type. got: %T, want: %T", value, extension.ExtensionType)
|
||||
}
|
||||
// nil extension values need to be caught early, because the
|
||||
// encoder can't distinguish an ErrNil due to a nil extension
|
||||
// from an ErrNil due to a missing field. Extensions are
|
||||
// always optional, so the encoder would just swallow the error
|
||||
// and drop all the extensions from the encoded message.
|
||||
if reflect.ValueOf(value).IsNil() {
|
||||
return fmt.Errorf("proto: SetExtension called with nil value of type %T", value)
|
||||
}
|
||||
|
||||
extmap := epb.extensionsWrite()
|
||||
extmap[extension.Field] = Extension{desc: extension, value: extensionAsStorageType(value)}
|
||||
return nil
|
||||
}
|
||||
|
||||
// ClearAllExtensions clears all extensions from pb.
|
||||
func ClearAllExtensions(pb Message) {
|
||||
epb, err := extendable(pb)
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
m := epb.extensionsWrite()
|
||||
for k := range m {
|
||||
delete(m, k)
|
||||
}
|
||||
}
|
||||
|
||||
// A global registry of extensions.
|
||||
// The generated code will register the generated descriptors by calling RegisterExtension.
|
||||
|
||||
var extensionMaps = make(map[reflect.Type]map[int32]*ExtensionDesc)
|
||||
|
||||
// RegisterExtension is called from the generated code.
|
||||
func RegisterExtension(desc *ExtensionDesc) {
|
||||
st := reflect.TypeOf(desc.ExtendedType).Elem()
|
||||
m := extensionMaps[st]
|
||||
if m == nil {
|
||||
m = make(map[int32]*ExtensionDesc)
|
||||
extensionMaps[st] = m
|
||||
}
|
||||
if _, ok := m[desc.Field]; ok {
|
||||
panic("proto: duplicate extension registered: " + st.String() + " " + strconv.Itoa(int(desc.Field)))
|
||||
}
|
||||
m[desc.Field] = desc
|
||||
}
|
||||
|
||||
// RegisteredExtensions returns a map of the registered extensions of a
|
||||
// protocol buffer struct, indexed by the extension number.
|
||||
// The argument pb should be a nil pointer to the struct type.
|
||||
func RegisteredExtensions(pb Message) map[int32]*ExtensionDesc {
|
||||
return extensionMaps[reflect.TypeOf(pb).Elem()]
|
||||
}
|
||||
|
||||
// extensionAsLegacyType converts an value in the storage type as the API type.
|
||||
// See Extension.value.
|
||||
func extensionAsLegacyType(v interface{}) interface{} {
|
||||
switch rv := reflect.ValueOf(v); rv.Kind() {
|
||||
case reflect.Bool, reflect.Int32, reflect.Int64, reflect.Uint32, reflect.Uint64, reflect.Float32, reflect.Float64, reflect.String:
|
||||
// Represent primitive types as a pointer to the value.
|
||||
rv2 := reflect.New(rv.Type())
|
||||
rv2.Elem().Set(rv)
|
||||
v = rv2.Interface()
|
||||
case reflect.Ptr:
|
||||
// Represent slice types as the value itself.
|
||||
switch rv.Type().Elem().Kind() {
|
||||
case reflect.Slice:
|
||||
if rv.IsNil() {
|
||||
v = reflect.Zero(rv.Type().Elem()).Interface()
|
||||
} else {
|
||||
v = rv.Elem().Interface()
|
||||
}
|
||||
}
|
||||
}
|
||||
return v
|
||||
}
|
||||
|
||||
// extensionAsStorageType converts an value in the API type as the storage type.
|
||||
// See Extension.value.
|
||||
func extensionAsStorageType(v interface{}) interface{} {
|
||||
switch rv := reflect.ValueOf(v); rv.Kind() {
|
||||
case reflect.Ptr:
|
||||
// Represent slice types as the value itself.
|
||||
switch rv.Type().Elem().Kind() {
|
||||
case reflect.Bool, reflect.Int32, reflect.Int64, reflect.Uint32, reflect.Uint64, reflect.Float32, reflect.Float64, reflect.String:
|
||||
if rv.IsNil() {
|
||||
v = reflect.Zero(rv.Type().Elem()).Interface()
|
||||
} else {
|
||||
v = rv.Elem().Interface()
|
||||
}
|
||||
}
|
||||
case reflect.Slice:
|
||||
// Represent slice types as a pointer to the value.
|
||||
if rv.Type().Elem().Kind() != reflect.Uint8 {
|
||||
rv2 := reflect.New(rv.Type())
|
||||
rv2.Elem().Set(rv)
|
||||
v = rv2.Interface()
|
||||
}
|
||||
}
|
||||
return v
|
||||
}
|
||||
965
watchdog/vendor/github.com/golang/protobuf/proto/lib.go
generated
vendored
965
watchdog/vendor/github.com/golang/protobuf/proto/lib.go
generated
vendored
@ -1,965 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2010 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
/*
|
||||
Package proto converts data structures to and from the wire format of
|
||||
protocol buffers. It works in concert with the Go source code generated
|
||||
for .proto files by the protocol compiler.
|
||||
|
||||
A summary of the properties of the protocol buffer interface
|
||||
for a protocol buffer variable v:
|
||||
|
||||
- Names are turned from camel_case to CamelCase for export.
|
||||
- There are no methods on v to set fields; just treat
|
||||
them as structure fields.
|
||||
- There are getters that return a field's value if set,
|
||||
and return the field's default value if unset.
|
||||
The getters work even if the receiver is a nil message.
|
||||
- The zero value for a struct is its correct initialization state.
|
||||
All desired fields must be set before marshaling.
|
||||
- A Reset() method will restore a protobuf struct to its zero state.
|
||||
- Non-repeated fields are pointers to the values; nil means unset.
|
||||
That is, optional or required field int32 f becomes F *int32.
|
||||
- Repeated fields are slices.
|
||||
- Helper functions are available to aid the setting of fields.
|
||||
msg.Foo = proto.String("hello") // set field
|
||||
- Constants are defined to hold the default values of all fields that
|
||||
have them. They have the form Default_StructName_FieldName.
|
||||
Because the getter methods handle defaulted values,
|
||||
direct use of these constants should be rare.
|
||||
- Enums are given type names and maps from names to values.
|
||||
Enum values are prefixed by the enclosing message's name, or by the
|
||||
enum's type name if it is a top-level enum. Enum types have a String
|
||||
method, and a Enum method to assist in message construction.
|
||||
- Nested messages, groups and enums have type names prefixed with the name of
|
||||
the surrounding message type.
|
||||
- Extensions are given descriptor names that start with E_,
|
||||
followed by an underscore-delimited list of the nested messages
|
||||
that contain it (if any) followed by the CamelCased name of the
|
||||
extension field itself. HasExtension, ClearExtension, GetExtension
|
||||
and SetExtension are functions for manipulating extensions.
|
||||
- Oneof field sets are given a single field in their message,
|
||||
with distinguished wrapper types for each possible field value.
|
||||
- Marshal and Unmarshal are functions to encode and decode the wire format.
|
||||
|
||||
When the .proto file specifies `syntax="proto3"`, there are some differences:
|
||||
|
||||
- Non-repeated fields of non-message type are values instead of pointers.
|
||||
- Enum types do not get an Enum method.
|
||||
|
||||
The simplest way to describe this is to see an example.
|
||||
Given file test.proto, containing
|
||||
|
||||
package example;
|
||||
|
||||
enum FOO { X = 17; }
|
||||
|
||||
message Test {
|
||||
required string label = 1;
|
||||
optional int32 type = 2 [default=77];
|
||||
repeated int64 reps = 3;
|
||||
optional group OptionalGroup = 4 {
|
||||
required string RequiredField = 5;
|
||||
}
|
||||
oneof union {
|
||||
int32 number = 6;
|
||||
string name = 7;
|
||||
}
|
||||
}
|
||||
|
||||
The resulting file, test.pb.go, is:
|
||||
|
||||
package example
|
||||
|
||||
import proto "github.com/golang/protobuf/proto"
|
||||
import math "math"
|
||||
|
||||
type FOO int32
|
||||
const (
|
||||
FOO_X FOO = 17
|
||||
)
|
||||
var FOO_name = map[int32]string{
|
||||
17: "X",
|
||||
}
|
||||
var FOO_value = map[string]int32{
|
||||
"X": 17,
|
||||
}
|
||||
|
||||
func (x FOO) Enum() *FOO {
|
||||
p := new(FOO)
|
||||
*p = x
|
||||
return p
|
||||
}
|
||||
func (x FOO) String() string {
|
||||
return proto.EnumName(FOO_name, int32(x))
|
||||
}
|
||||
func (x *FOO) UnmarshalJSON(data []byte) error {
|
||||
value, err := proto.UnmarshalJSONEnum(FOO_value, data)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
*x = FOO(value)
|
||||
return nil
|
||||
}
|
||||
|
||||
type Test struct {
|
||||
Label *string `protobuf:"bytes,1,req,name=label" json:"label,omitempty"`
|
||||
Type *int32 `protobuf:"varint,2,opt,name=type,def=77" json:"type,omitempty"`
|
||||
Reps []int64 `protobuf:"varint,3,rep,name=reps" json:"reps,omitempty"`
|
||||
Optionalgroup *Test_OptionalGroup `protobuf:"group,4,opt,name=OptionalGroup" json:"optionalgroup,omitempty"`
|
||||
// Types that are valid to be assigned to Union:
|
||||
// *Test_Number
|
||||
// *Test_Name
|
||||
Union isTest_Union `protobuf_oneof:"union"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
}
|
||||
func (m *Test) Reset() { *m = Test{} }
|
||||
func (m *Test) String() string { return proto.CompactTextString(m) }
|
||||
func (*Test) ProtoMessage() {}
|
||||
|
||||
type isTest_Union interface {
|
||||
isTest_Union()
|
||||
}
|
||||
|
||||
type Test_Number struct {
|
||||
Number int32 `protobuf:"varint,6,opt,name=number"`
|
||||
}
|
||||
type Test_Name struct {
|
||||
Name string `protobuf:"bytes,7,opt,name=name"`
|
||||
}
|
||||
|
||||
func (*Test_Number) isTest_Union() {}
|
||||
func (*Test_Name) isTest_Union() {}
|
||||
|
||||
func (m *Test) GetUnion() isTest_Union {
|
||||
if m != nil {
|
||||
return m.Union
|
||||
}
|
||||
return nil
|
||||
}
|
||||
const Default_Test_Type int32 = 77
|
||||
|
||||
func (m *Test) GetLabel() string {
|
||||
if m != nil && m.Label != nil {
|
||||
return *m.Label
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
func (m *Test) GetType() int32 {
|
||||
if m != nil && m.Type != nil {
|
||||
return *m.Type
|
||||
}
|
||||
return Default_Test_Type
|
||||
}
|
||||
|
||||
func (m *Test) GetOptionalgroup() *Test_OptionalGroup {
|
||||
if m != nil {
|
||||
return m.Optionalgroup
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
type Test_OptionalGroup struct {
|
||||
RequiredField *string `protobuf:"bytes,5,req" json:"RequiredField,omitempty"`
|
||||
}
|
||||
func (m *Test_OptionalGroup) Reset() { *m = Test_OptionalGroup{} }
|
||||
func (m *Test_OptionalGroup) String() string { return proto.CompactTextString(m) }
|
||||
|
||||
func (m *Test_OptionalGroup) GetRequiredField() string {
|
||||
if m != nil && m.RequiredField != nil {
|
||||
return *m.RequiredField
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
func (m *Test) GetNumber() int32 {
|
||||
if x, ok := m.GetUnion().(*Test_Number); ok {
|
||||
return x.Number
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
func (m *Test) GetName() string {
|
||||
if x, ok := m.GetUnion().(*Test_Name); ok {
|
||||
return x.Name
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
func init() {
|
||||
proto.RegisterEnum("example.FOO", FOO_name, FOO_value)
|
||||
}
|
||||
|
||||
To create and play with a Test object:
|
||||
|
||||
package main
|
||||
|
||||
import (
|
||||
"log"
|
||||
|
||||
"github.com/golang/protobuf/proto"
|
||||
pb "./example.pb"
|
||||
)
|
||||
|
||||
func main() {
|
||||
test := &pb.Test{
|
||||
Label: proto.String("hello"),
|
||||
Type: proto.Int32(17),
|
||||
Reps: []int64{1, 2, 3},
|
||||
Optionalgroup: &pb.Test_OptionalGroup{
|
||||
RequiredField: proto.String("good bye"),
|
||||
},
|
||||
Union: &pb.Test_Name{"fred"},
|
||||
}
|
||||
data, err := proto.Marshal(test)
|
||||
if err != nil {
|
||||
log.Fatal("marshaling error: ", err)
|
||||
}
|
||||
newTest := &pb.Test{}
|
||||
err = proto.Unmarshal(data, newTest)
|
||||
if err != nil {
|
||||
log.Fatal("unmarshaling error: ", err)
|
||||
}
|
||||
// Now test and newTest contain the same data.
|
||||
if test.GetLabel() != newTest.GetLabel() {
|
||||
log.Fatalf("data mismatch %q != %q", test.GetLabel(), newTest.GetLabel())
|
||||
}
|
||||
// Use a type switch to determine which oneof was set.
|
||||
switch u := test.Union.(type) {
|
||||
case *pb.Test_Number: // u.Number contains the number.
|
||||
case *pb.Test_Name: // u.Name contains the string.
|
||||
}
|
||||
// etc.
|
||||
}
|
||||
*/
|
||||
package proto
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"log"
|
||||
"reflect"
|
||||
"sort"
|
||||
"strconv"
|
||||
"sync"
|
||||
)
|
||||
|
||||
// RequiredNotSetError is an error type returned by either Marshal or Unmarshal.
|
||||
// Marshal reports this when a required field is not initialized.
|
||||
// Unmarshal reports this when a required field is missing from the wire data.
|
||||
type RequiredNotSetError struct{ field string }
|
||||
|
||||
func (e *RequiredNotSetError) Error() string {
|
||||
if e.field == "" {
|
||||
return fmt.Sprintf("proto: required field not set")
|
||||
}
|
||||
return fmt.Sprintf("proto: required field %q not set", e.field)
|
||||
}
|
||||
func (e *RequiredNotSetError) RequiredNotSet() bool {
|
||||
return true
|
||||
}
|
||||
|
||||
type invalidUTF8Error struct{ field string }
|
||||
|
||||
func (e *invalidUTF8Error) Error() string {
|
||||
if e.field == "" {
|
||||
return "proto: invalid UTF-8 detected"
|
||||
}
|
||||
return fmt.Sprintf("proto: field %q contains invalid UTF-8", e.field)
|
||||
}
|
||||
func (e *invalidUTF8Error) InvalidUTF8() bool {
|
||||
return true
|
||||
}
|
||||
|
||||
// errInvalidUTF8 is a sentinel error to identify fields with invalid UTF-8.
|
||||
// This error should not be exposed to the external API as such errors should
|
||||
// be recreated with the field information.
|
||||
var errInvalidUTF8 = &invalidUTF8Error{}
|
||||
|
||||
// isNonFatal reports whether the error is either a RequiredNotSet error
|
||||
// or a InvalidUTF8 error.
|
||||
func isNonFatal(err error) bool {
|
||||
if re, ok := err.(interface{ RequiredNotSet() bool }); ok && re.RequiredNotSet() {
|
||||
return true
|
||||
}
|
||||
if re, ok := err.(interface{ InvalidUTF8() bool }); ok && re.InvalidUTF8() {
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
type nonFatal struct{ E error }
|
||||
|
||||
// Merge merges err into nf and reports whether it was successful.
|
||||
// Otherwise it returns false for any fatal non-nil errors.
|
||||
func (nf *nonFatal) Merge(err error) (ok bool) {
|
||||
if err == nil {
|
||||
return true // not an error
|
||||
}
|
||||
if !isNonFatal(err) {
|
||||
return false // fatal error
|
||||
}
|
||||
if nf.E == nil {
|
||||
nf.E = err // store first instance of non-fatal error
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
// Message is implemented by generated protocol buffer messages.
|
||||
type Message interface {
|
||||
Reset()
|
||||
String() string
|
||||
ProtoMessage()
|
||||
}
|
||||
|
||||
// A Buffer is a buffer manager for marshaling and unmarshaling
|
||||
// protocol buffers. It may be reused between invocations to
|
||||
// reduce memory usage. It is not necessary to use a Buffer;
|
||||
// the global functions Marshal and Unmarshal create a
|
||||
// temporary Buffer and are fine for most applications.
|
||||
type Buffer struct {
|
||||
buf []byte // encode/decode byte stream
|
||||
index int // read point
|
||||
|
||||
deterministic bool
|
||||
}
|
||||
|
||||
// NewBuffer allocates a new Buffer and initializes its internal data to
|
||||
// the contents of the argument slice.
|
||||
func NewBuffer(e []byte) *Buffer {
|
||||
return &Buffer{buf: e}
|
||||
}
|
||||
|
||||
// Reset resets the Buffer, ready for marshaling a new protocol buffer.
|
||||
func (p *Buffer) Reset() {
|
||||
p.buf = p.buf[0:0] // for reading/writing
|
||||
p.index = 0 // for reading
|
||||
}
|
||||
|
||||
// SetBuf replaces the internal buffer with the slice,
|
||||
// ready for unmarshaling the contents of the slice.
|
||||
func (p *Buffer) SetBuf(s []byte) {
|
||||
p.buf = s
|
||||
p.index = 0
|
||||
}
|
||||
|
||||
// Bytes returns the contents of the Buffer.
|
||||
func (p *Buffer) Bytes() []byte { return p.buf }
|
||||
|
||||
// SetDeterministic sets whether to use deterministic serialization.
|
||||
//
|
||||
// Deterministic serialization guarantees that for a given binary, equal
|
||||
// messages will always be serialized to the same bytes. This implies:
|
||||
//
|
||||
// - Repeated serialization of a message will return the same bytes.
|
||||
// - Different processes of the same binary (which may be executing on
|
||||
// different machines) will serialize equal messages to the same bytes.
|
||||
//
|
||||
// Note that the deterministic serialization is NOT canonical across
|
||||
// languages. It is not guaranteed to remain stable over time. It is unstable
|
||||
// across different builds with schema changes due to unknown fields.
|
||||
// Users who need canonical serialization (e.g., persistent storage in a
|
||||
// canonical form, fingerprinting, etc.) should define their own
|
||||
// canonicalization specification and implement their own serializer rather
|
||||
// than relying on this API.
|
||||
//
|
||||
// If deterministic serialization is requested, map entries will be sorted
|
||||
// by keys in lexographical order. This is an implementation detail and
|
||||
// subject to change.
|
||||
func (p *Buffer) SetDeterministic(deterministic bool) {
|
||||
p.deterministic = deterministic
|
||||
}
|
||||
|
||||
/*
|
||||
* Helper routines for simplifying the creation of optional fields of basic type.
|
||||
*/
|
||||
|
||||
// Bool is a helper routine that allocates a new bool value
|
||||
// to store v and returns a pointer to it.
|
||||
func Bool(v bool) *bool {
|
||||
return &v
|
||||
}
|
||||
|
||||
// Int32 is a helper routine that allocates a new int32 value
|
||||
// to store v and returns a pointer to it.
|
||||
func Int32(v int32) *int32 {
|
||||
return &v
|
||||
}
|
||||
|
||||
// Int is a helper routine that allocates a new int32 value
|
||||
// to store v and returns a pointer to it, but unlike Int32
|
||||
// its argument value is an int.
|
||||
func Int(v int) *int32 {
|
||||
p := new(int32)
|
||||
*p = int32(v)
|
||||
return p
|
||||
}
|
||||
|
||||
// Int64 is a helper routine that allocates a new int64 value
|
||||
// to store v and returns a pointer to it.
|
||||
func Int64(v int64) *int64 {
|
||||
return &v
|
||||
}
|
||||
|
||||
// Float32 is a helper routine that allocates a new float32 value
|
||||
// to store v and returns a pointer to it.
|
||||
func Float32(v float32) *float32 {
|
||||
return &v
|
||||
}
|
||||
|
||||
// Float64 is a helper routine that allocates a new float64 value
|
||||
// to store v and returns a pointer to it.
|
||||
func Float64(v float64) *float64 {
|
||||
return &v
|
||||
}
|
||||
|
||||
// Uint32 is a helper routine that allocates a new uint32 value
|
||||
// to store v and returns a pointer to it.
|
||||
func Uint32(v uint32) *uint32 {
|
||||
return &v
|
||||
}
|
||||
|
||||
// Uint64 is a helper routine that allocates a new uint64 value
|
||||
// to store v and returns a pointer to it.
|
||||
func Uint64(v uint64) *uint64 {
|
||||
return &v
|
||||
}
|
||||
|
||||
// String is a helper routine that allocates a new string value
|
||||
// to store v and returns a pointer to it.
|
||||
func String(v string) *string {
|
||||
return &v
|
||||
}
|
||||
|
||||
// EnumName is a helper function to simplify printing protocol buffer enums
|
||||
// by name. Given an enum map and a value, it returns a useful string.
|
||||
func EnumName(m map[int32]string, v int32) string {
|
||||
s, ok := m[v]
|
||||
if ok {
|
||||
return s
|
||||
}
|
||||
return strconv.Itoa(int(v))
|
||||
}
|
||||
|
||||
// UnmarshalJSONEnum is a helper function to simplify recovering enum int values
|
||||
// from their JSON-encoded representation. Given a map from the enum's symbolic
|
||||
// names to its int values, and a byte buffer containing the JSON-encoded
|
||||
// value, it returns an int32 that can be cast to the enum type by the caller.
|
||||
//
|
||||
// The function can deal with both JSON representations, numeric and symbolic.
|
||||
func UnmarshalJSONEnum(m map[string]int32, data []byte, enumName string) (int32, error) {
|
||||
if data[0] == '"' {
|
||||
// New style: enums are strings.
|
||||
var repr string
|
||||
if err := json.Unmarshal(data, &repr); err != nil {
|
||||
return -1, err
|
||||
}
|
||||
val, ok := m[repr]
|
||||
if !ok {
|
||||
return 0, fmt.Errorf("unrecognized enum %s value %q", enumName, repr)
|
||||
}
|
||||
return val, nil
|
||||
}
|
||||
// Old style: enums are ints.
|
||||
var val int32
|
||||
if err := json.Unmarshal(data, &val); err != nil {
|
||||
return 0, fmt.Errorf("cannot unmarshal %#q into enum %s", data, enumName)
|
||||
}
|
||||
return val, nil
|
||||
}
|
||||
|
||||
// DebugPrint dumps the encoded data in b in a debugging format with a header
|
||||
// including the string s. Used in testing but made available for general debugging.
|
||||
func (p *Buffer) DebugPrint(s string, b []byte) {
|
||||
var u uint64
|
||||
|
||||
obuf := p.buf
|
||||
index := p.index
|
||||
p.buf = b
|
||||
p.index = 0
|
||||
depth := 0
|
||||
|
||||
fmt.Printf("\n--- %s ---\n", s)
|
||||
|
||||
out:
|
||||
for {
|
||||
for i := 0; i < depth; i++ {
|
||||
fmt.Print(" ")
|
||||
}
|
||||
|
||||
index := p.index
|
||||
if index == len(p.buf) {
|
||||
break
|
||||
}
|
||||
|
||||
op, err := p.DecodeVarint()
|
||||
if err != nil {
|
||||
fmt.Printf("%3d: fetching op err %v\n", index, err)
|
||||
break out
|
||||
}
|
||||
tag := op >> 3
|
||||
wire := op & 7
|
||||
|
||||
switch wire {
|
||||
default:
|
||||
fmt.Printf("%3d: t=%3d unknown wire=%d\n",
|
||||
index, tag, wire)
|
||||
break out
|
||||
|
||||
case WireBytes:
|
||||
var r []byte
|
||||
|
||||
r, err = p.DecodeRawBytes(false)
|
||||
if err != nil {
|
||||
break out
|
||||
}
|
||||
fmt.Printf("%3d: t=%3d bytes [%d]", index, tag, len(r))
|
||||
if len(r) <= 6 {
|
||||
for i := 0; i < len(r); i++ {
|
||||
fmt.Printf(" %.2x", r[i])
|
||||
}
|
||||
} else {
|
||||
for i := 0; i < 3; i++ {
|
||||
fmt.Printf(" %.2x", r[i])
|
||||
}
|
||||
fmt.Printf(" ..")
|
||||
for i := len(r) - 3; i < len(r); i++ {
|
||||
fmt.Printf(" %.2x", r[i])
|
||||
}
|
||||
}
|
||||
fmt.Printf("\n")
|
||||
|
||||
case WireFixed32:
|
||||
u, err = p.DecodeFixed32()
|
||||
if err != nil {
|
||||
fmt.Printf("%3d: t=%3d fix32 err %v\n", index, tag, err)
|
||||
break out
|
||||
}
|
||||
fmt.Printf("%3d: t=%3d fix32 %d\n", index, tag, u)
|
||||
|
||||
case WireFixed64:
|
||||
u, err = p.DecodeFixed64()
|
||||
if err != nil {
|
||||
fmt.Printf("%3d: t=%3d fix64 err %v\n", index, tag, err)
|
||||
break out
|
||||
}
|
||||
fmt.Printf("%3d: t=%3d fix64 %d\n", index, tag, u)
|
||||
|
||||
case WireVarint:
|
||||
u, err = p.DecodeVarint()
|
||||
if err != nil {
|
||||
fmt.Printf("%3d: t=%3d varint err %v\n", index, tag, err)
|
||||
break out
|
||||
}
|
||||
fmt.Printf("%3d: t=%3d varint %d\n", index, tag, u)
|
||||
|
||||
case WireStartGroup:
|
||||
fmt.Printf("%3d: t=%3d start\n", index, tag)
|
||||
depth++
|
||||
|
||||
case WireEndGroup:
|
||||
depth--
|
||||
fmt.Printf("%3d: t=%3d end\n", index, tag)
|
||||
}
|
||||
}
|
||||
|
||||
if depth != 0 {
|
||||
fmt.Printf("%3d: start-end not balanced %d\n", p.index, depth)
|
||||
}
|
||||
fmt.Printf("\n")
|
||||
|
||||
p.buf = obuf
|
||||
p.index = index
|
||||
}
|
||||
|
||||
// SetDefaults sets unset protocol buffer fields to their default values.
|
||||
// It only modifies fields that are both unset and have defined defaults.
|
||||
// It recursively sets default values in any non-nil sub-messages.
|
||||
func SetDefaults(pb Message) {
|
||||
setDefaults(reflect.ValueOf(pb), true, false)
|
||||
}
|
||||
|
||||
// v is a pointer to a struct.
|
||||
func setDefaults(v reflect.Value, recur, zeros bool) {
|
||||
v = v.Elem()
|
||||
|
||||
defaultMu.RLock()
|
||||
dm, ok := defaults[v.Type()]
|
||||
defaultMu.RUnlock()
|
||||
if !ok {
|
||||
dm = buildDefaultMessage(v.Type())
|
||||
defaultMu.Lock()
|
||||
defaults[v.Type()] = dm
|
||||
defaultMu.Unlock()
|
||||
}
|
||||
|
||||
for _, sf := range dm.scalars {
|
||||
f := v.Field(sf.index)
|
||||
if !f.IsNil() {
|
||||
// field already set
|
||||
continue
|
||||
}
|
||||
dv := sf.value
|
||||
if dv == nil && !zeros {
|
||||
// no explicit default, and don't want to set zeros
|
||||
continue
|
||||
}
|
||||
fptr := f.Addr().Interface() // **T
|
||||
// TODO: Consider batching the allocations we do here.
|
||||
switch sf.kind {
|
||||
case reflect.Bool:
|
||||
b := new(bool)
|
||||
if dv != nil {
|
||||
*b = dv.(bool)
|
||||
}
|
||||
*(fptr.(**bool)) = b
|
||||
case reflect.Float32:
|
||||
f := new(float32)
|
||||
if dv != nil {
|
||||
*f = dv.(float32)
|
||||
}
|
||||
*(fptr.(**float32)) = f
|
||||
case reflect.Float64:
|
||||
f := new(float64)
|
||||
if dv != nil {
|
||||
*f = dv.(float64)
|
||||
}
|
||||
*(fptr.(**float64)) = f
|
||||
case reflect.Int32:
|
||||
// might be an enum
|
||||
if ft := f.Type(); ft != int32PtrType {
|
||||
// enum
|
||||
f.Set(reflect.New(ft.Elem()))
|
||||
if dv != nil {
|
||||
f.Elem().SetInt(int64(dv.(int32)))
|
||||
}
|
||||
} else {
|
||||
// int32 field
|
||||
i := new(int32)
|
||||
if dv != nil {
|
||||
*i = dv.(int32)
|
||||
}
|
||||
*(fptr.(**int32)) = i
|
||||
}
|
||||
case reflect.Int64:
|
||||
i := new(int64)
|
||||
if dv != nil {
|
||||
*i = dv.(int64)
|
||||
}
|
||||
*(fptr.(**int64)) = i
|
||||
case reflect.String:
|
||||
s := new(string)
|
||||
if dv != nil {
|
||||
*s = dv.(string)
|
||||
}
|
||||
*(fptr.(**string)) = s
|
||||
case reflect.Uint8:
|
||||
// exceptional case: []byte
|
||||
var b []byte
|
||||
if dv != nil {
|
||||
db := dv.([]byte)
|
||||
b = make([]byte, len(db))
|
||||
copy(b, db)
|
||||
} else {
|
||||
b = []byte{}
|
||||
}
|
||||
*(fptr.(*[]byte)) = b
|
||||
case reflect.Uint32:
|
||||
u := new(uint32)
|
||||
if dv != nil {
|
||||
*u = dv.(uint32)
|
||||
}
|
||||
*(fptr.(**uint32)) = u
|
||||
case reflect.Uint64:
|
||||
u := new(uint64)
|
||||
if dv != nil {
|
||||
*u = dv.(uint64)
|
||||
}
|
||||
*(fptr.(**uint64)) = u
|
||||
default:
|
||||
log.Printf("proto: can't set default for field %v (sf.kind=%v)", f, sf.kind)
|
||||
}
|
||||
}
|
||||
|
||||
for _, ni := range dm.nested {
|
||||
f := v.Field(ni)
|
||||
// f is *T or []*T or map[T]*T
|
||||
switch f.Kind() {
|
||||
case reflect.Ptr:
|
||||
if f.IsNil() {
|
||||
continue
|
||||
}
|
||||
setDefaults(f, recur, zeros)
|
||||
|
||||
case reflect.Slice:
|
||||
for i := 0; i < f.Len(); i++ {
|
||||
e := f.Index(i)
|
||||
if e.IsNil() {
|
||||
continue
|
||||
}
|
||||
setDefaults(e, recur, zeros)
|
||||
}
|
||||
|
||||
case reflect.Map:
|
||||
for _, k := range f.MapKeys() {
|
||||
e := f.MapIndex(k)
|
||||
if e.IsNil() {
|
||||
continue
|
||||
}
|
||||
setDefaults(e, recur, zeros)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
var (
|
||||
// defaults maps a protocol buffer struct type to a slice of the fields,
|
||||
// with its scalar fields set to their proto-declared non-zero default values.
|
||||
defaultMu sync.RWMutex
|
||||
defaults = make(map[reflect.Type]defaultMessage)
|
||||
|
||||
int32PtrType = reflect.TypeOf((*int32)(nil))
|
||||
)
|
||||
|
||||
// defaultMessage represents information about the default values of a message.
|
||||
type defaultMessage struct {
|
||||
scalars []scalarField
|
||||
nested []int // struct field index of nested messages
|
||||
}
|
||||
|
||||
type scalarField struct {
|
||||
index int // struct field index
|
||||
kind reflect.Kind // element type (the T in *T or []T)
|
||||
value interface{} // the proto-declared default value, or nil
|
||||
}
|
||||
|
||||
// t is a struct type.
|
||||
func buildDefaultMessage(t reflect.Type) (dm defaultMessage) {
|
||||
sprop := GetProperties(t)
|
||||
for _, prop := range sprop.Prop {
|
||||
fi, ok := sprop.decoderTags.get(prop.Tag)
|
||||
if !ok {
|
||||
// XXX_unrecognized
|
||||
continue
|
||||
}
|
||||
ft := t.Field(fi).Type
|
||||
|
||||
sf, nested, err := fieldDefault(ft, prop)
|
||||
switch {
|
||||
case err != nil:
|
||||
log.Print(err)
|
||||
case nested:
|
||||
dm.nested = append(dm.nested, fi)
|
||||
case sf != nil:
|
||||
sf.index = fi
|
||||
dm.scalars = append(dm.scalars, *sf)
|
||||
}
|
||||
}
|
||||
|
||||
return dm
|
||||
}
|
||||
|
||||
// fieldDefault returns the scalarField for field type ft.
|
||||
// sf will be nil if the field can not have a default.
|
||||
// nestedMessage will be true if this is a nested message.
|
||||
// Note that sf.index is not set on return.
|
||||
func fieldDefault(ft reflect.Type, prop *Properties) (sf *scalarField, nestedMessage bool, err error) {
|
||||
var canHaveDefault bool
|
||||
switch ft.Kind() {
|
||||
case reflect.Ptr:
|
||||
if ft.Elem().Kind() == reflect.Struct {
|
||||
nestedMessage = true
|
||||
} else {
|
||||
canHaveDefault = true // proto2 scalar field
|
||||
}
|
||||
|
||||
case reflect.Slice:
|
||||
switch ft.Elem().Kind() {
|
||||
case reflect.Ptr:
|
||||
nestedMessage = true // repeated message
|
||||
case reflect.Uint8:
|
||||
canHaveDefault = true // bytes field
|
||||
}
|
||||
|
||||
case reflect.Map:
|
||||
if ft.Elem().Kind() == reflect.Ptr {
|
||||
nestedMessage = true // map with message values
|
||||
}
|
||||
}
|
||||
|
||||
if !canHaveDefault {
|
||||
if nestedMessage {
|
||||
return nil, true, nil
|
||||
}
|
||||
return nil, false, nil
|
||||
}
|
||||
|
||||
// We now know that ft is a pointer or slice.
|
||||
sf = &scalarField{kind: ft.Elem().Kind()}
|
||||
|
||||
// scalar fields without defaults
|
||||
if !prop.HasDefault {
|
||||
return sf, false, nil
|
||||
}
|
||||
|
||||
// a scalar field: either *T or []byte
|
||||
switch ft.Elem().Kind() {
|
||||
case reflect.Bool:
|
||||
x, err := strconv.ParseBool(prop.Default)
|
||||
if err != nil {
|
||||
return nil, false, fmt.Errorf("proto: bad default bool %q: %v", prop.Default, err)
|
||||
}
|
||||
sf.value = x
|
||||
case reflect.Float32:
|
||||
x, err := strconv.ParseFloat(prop.Default, 32)
|
||||
if err != nil {
|
||||
return nil, false, fmt.Errorf("proto: bad default float32 %q: %v", prop.Default, err)
|
||||
}
|
||||
sf.value = float32(x)
|
||||
case reflect.Float64:
|
||||
x, err := strconv.ParseFloat(prop.Default, 64)
|
||||
if err != nil {
|
||||
return nil, false, fmt.Errorf("proto: bad default float64 %q: %v", prop.Default, err)
|
||||
}
|
||||
sf.value = x
|
||||
case reflect.Int32:
|
||||
x, err := strconv.ParseInt(prop.Default, 10, 32)
|
||||
if err != nil {
|
||||
return nil, false, fmt.Errorf("proto: bad default int32 %q: %v", prop.Default, err)
|
||||
}
|
||||
sf.value = int32(x)
|
||||
case reflect.Int64:
|
||||
x, err := strconv.ParseInt(prop.Default, 10, 64)
|
||||
if err != nil {
|
||||
return nil, false, fmt.Errorf("proto: bad default int64 %q: %v", prop.Default, err)
|
||||
}
|
||||
sf.value = x
|
||||
case reflect.String:
|
||||
sf.value = prop.Default
|
||||
case reflect.Uint8:
|
||||
// []byte (not *uint8)
|
||||
sf.value = []byte(prop.Default)
|
||||
case reflect.Uint32:
|
||||
x, err := strconv.ParseUint(prop.Default, 10, 32)
|
||||
if err != nil {
|
||||
return nil, false, fmt.Errorf("proto: bad default uint32 %q: %v", prop.Default, err)
|
||||
}
|
||||
sf.value = uint32(x)
|
||||
case reflect.Uint64:
|
||||
x, err := strconv.ParseUint(prop.Default, 10, 64)
|
||||
if err != nil {
|
||||
return nil, false, fmt.Errorf("proto: bad default uint64 %q: %v", prop.Default, err)
|
||||
}
|
||||
sf.value = x
|
||||
default:
|
||||
return nil, false, fmt.Errorf("proto: unhandled def kind %v", ft.Elem().Kind())
|
||||
}
|
||||
|
||||
return sf, false, nil
|
||||
}
|
||||
|
||||
// mapKeys returns a sort.Interface to be used for sorting the map keys.
|
||||
// Map fields may have key types of non-float scalars, strings and enums.
|
||||
func mapKeys(vs []reflect.Value) sort.Interface {
|
||||
s := mapKeySorter{vs: vs}
|
||||
|
||||
// Type specialization per https://developers.google.com/protocol-buffers/docs/proto#maps.
|
||||
if len(vs) == 0 {
|
||||
return s
|
||||
}
|
||||
switch vs[0].Kind() {
|
||||
case reflect.Int32, reflect.Int64:
|
||||
s.less = func(a, b reflect.Value) bool { return a.Int() < b.Int() }
|
||||
case reflect.Uint32, reflect.Uint64:
|
||||
s.less = func(a, b reflect.Value) bool { return a.Uint() < b.Uint() }
|
||||
case reflect.Bool:
|
||||
s.less = func(a, b reflect.Value) bool { return !a.Bool() && b.Bool() } // false < true
|
||||
case reflect.String:
|
||||
s.less = func(a, b reflect.Value) bool { return a.String() < b.String() }
|
||||
default:
|
||||
panic(fmt.Sprintf("unsupported map key type: %v", vs[0].Kind()))
|
||||
}
|
||||
|
||||
return s
|
||||
}
|
||||
|
||||
type mapKeySorter struct {
|
||||
vs []reflect.Value
|
||||
less func(a, b reflect.Value) bool
|
||||
}
|
||||
|
||||
func (s mapKeySorter) Len() int { return len(s.vs) }
|
||||
func (s mapKeySorter) Swap(i, j int) { s.vs[i], s.vs[j] = s.vs[j], s.vs[i] }
|
||||
func (s mapKeySorter) Less(i, j int) bool {
|
||||
return s.less(s.vs[i], s.vs[j])
|
||||
}
|
||||
|
||||
// isProto3Zero reports whether v is a zero proto3 value.
|
||||
func isProto3Zero(v reflect.Value) bool {
|
||||
switch v.Kind() {
|
||||
case reflect.Bool:
|
||||
return !v.Bool()
|
||||
case reflect.Int32, reflect.Int64:
|
||||
return v.Int() == 0
|
||||
case reflect.Uint32, reflect.Uint64:
|
||||
return v.Uint() == 0
|
||||
case reflect.Float32, reflect.Float64:
|
||||
return v.Float() == 0
|
||||
case reflect.String:
|
||||
return v.String() == ""
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
const (
|
||||
// ProtoPackageIsVersion3 is referenced from generated protocol buffer files
|
||||
// to assert that that code is compatible with this version of the proto package.
|
||||
ProtoPackageIsVersion3 = true
|
||||
|
||||
// ProtoPackageIsVersion2 is referenced from generated protocol buffer files
|
||||
// to assert that that code is compatible with this version of the proto package.
|
||||
ProtoPackageIsVersion2 = true
|
||||
|
||||
// ProtoPackageIsVersion1 is referenced from generated protocol buffer files
|
||||
// to assert that that code is compatible with this version of the proto package.
|
||||
ProtoPackageIsVersion1 = true
|
||||
)
|
||||
|
||||
// InternalMessageInfo is a type used internally by generated .pb.go files.
|
||||
// This type is not intended to be used by non-generated code.
|
||||
// This type is not subject to any compatibility guarantee.
|
||||
type InternalMessageInfo struct {
|
||||
marshal *marshalInfo
|
||||
unmarshal *unmarshalInfo
|
||||
merge *mergeInfo
|
||||
discard *discardInfo
|
||||
}
|
||||
181
watchdog/vendor/github.com/golang/protobuf/proto/message_set.go
generated
vendored
181
watchdog/vendor/github.com/golang/protobuf/proto/message_set.go
generated
vendored
@ -1,181 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2010 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
package proto
|
||||
|
||||
/*
|
||||
* Support for message sets.
|
||||
*/
|
||||
|
||||
import (
|
||||
"errors"
|
||||
)
|
||||
|
||||
// errNoMessageTypeID occurs when a protocol buffer does not have a message type ID.
|
||||
// A message type ID is required for storing a protocol buffer in a message set.
|
||||
var errNoMessageTypeID = errors.New("proto does not have a message type ID")
|
||||
|
||||
// The first two types (_MessageSet_Item and messageSet)
|
||||
// model what the protocol compiler produces for the following protocol message:
|
||||
// message MessageSet {
|
||||
// repeated group Item = 1 {
|
||||
// required int32 type_id = 2;
|
||||
// required string message = 3;
|
||||
// };
|
||||
// }
|
||||
// That is the MessageSet wire format. We can't use a proto to generate these
|
||||
// because that would introduce a circular dependency between it and this package.
|
||||
|
||||
type _MessageSet_Item struct {
|
||||
TypeId *int32 `protobuf:"varint,2,req,name=type_id"`
|
||||
Message []byte `protobuf:"bytes,3,req,name=message"`
|
||||
}
|
||||
|
||||
type messageSet struct {
|
||||
Item []*_MessageSet_Item `protobuf:"group,1,rep"`
|
||||
XXX_unrecognized []byte
|
||||
// TODO: caching?
|
||||
}
|
||||
|
||||
// Make sure messageSet is a Message.
|
||||
var _ Message = (*messageSet)(nil)
|
||||
|
||||
// messageTypeIder is an interface satisfied by a protocol buffer type
|
||||
// that may be stored in a MessageSet.
|
||||
type messageTypeIder interface {
|
||||
MessageTypeId() int32
|
||||
}
|
||||
|
||||
func (ms *messageSet) find(pb Message) *_MessageSet_Item {
|
||||
mti, ok := pb.(messageTypeIder)
|
||||
if !ok {
|
||||
return nil
|
||||
}
|
||||
id := mti.MessageTypeId()
|
||||
for _, item := range ms.Item {
|
||||
if *item.TypeId == id {
|
||||
return item
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (ms *messageSet) Has(pb Message) bool {
|
||||
return ms.find(pb) != nil
|
||||
}
|
||||
|
||||
func (ms *messageSet) Unmarshal(pb Message) error {
|
||||
if item := ms.find(pb); item != nil {
|
||||
return Unmarshal(item.Message, pb)
|
||||
}
|
||||
if _, ok := pb.(messageTypeIder); !ok {
|
||||
return errNoMessageTypeID
|
||||
}
|
||||
return nil // TODO: return error instead?
|
||||
}
|
||||
|
||||
func (ms *messageSet) Marshal(pb Message) error {
|
||||
msg, err := Marshal(pb)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if item := ms.find(pb); item != nil {
|
||||
// reuse existing item
|
||||
item.Message = msg
|
||||
return nil
|
||||
}
|
||||
|
||||
mti, ok := pb.(messageTypeIder)
|
||||
if !ok {
|
||||
return errNoMessageTypeID
|
||||
}
|
||||
|
||||
mtid := mti.MessageTypeId()
|
||||
ms.Item = append(ms.Item, &_MessageSet_Item{
|
||||
TypeId: &mtid,
|
||||
Message: msg,
|
||||
})
|
||||
return nil
|
||||
}
|
||||
|
||||
func (ms *messageSet) Reset() { *ms = messageSet{} }
|
||||
func (ms *messageSet) String() string { return CompactTextString(ms) }
|
||||
func (*messageSet) ProtoMessage() {}
|
||||
|
||||
// Support for the message_set_wire_format message option.
|
||||
|
||||
func skipVarint(buf []byte) []byte {
|
||||
i := 0
|
||||
for ; buf[i]&0x80 != 0; i++ {
|
||||
}
|
||||
return buf[i+1:]
|
||||
}
|
||||
|
||||
// unmarshalMessageSet decodes the extension map encoded in buf in the message set wire format.
|
||||
// It is called by Unmarshal methods on protocol buffer messages with the message_set_wire_format option.
|
||||
func unmarshalMessageSet(buf []byte, exts interface{}) error {
|
||||
var m map[int32]Extension
|
||||
switch exts := exts.(type) {
|
||||
case *XXX_InternalExtensions:
|
||||
m = exts.extensionsWrite()
|
||||
case map[int32]Extension:
|
||||
m = exts
|
||||
default:
|
||||
return errors.New("proto: not an extension map")
|
||||
}
|
||||
|
||||
ms := new(messageSet)
|
||||
if err := Unmarshal(buf, ms); err != nil {
|
||||
return err
|
||||
}
|
||||
for _, item := range ms.Item {
|
||||
id := *item.TypeId
|
||||
msg := item.Message
|
||||
|
||||
// Restore wire type and field number varint, plus length varint.
|
||||
// Be careful to preserve duplicate items.
|
||||
b := EncodeVarint(uint64(id)<<3 | WireBytes)
|
||||
if ext, ok := m[id]; ok {
|
||||
// Existing data; rip off the tag and length varint
|
||||
// so we join the new data correctly.
|
||||
// We can assume that ext.enc is set because we are unmarshaling.
|
||||
o := ext.enc[len(b):] // skip wire type and field number
|
||||
_, n := DecodeVarint(o) // calculate length of length varint
|
||||
o = o[n:] // skip length varint
|
||||
msg = append(o, msg...) // join old data and new data
|
||||
}
|
||||
b = append(b, EncodeVarint(uint64(len(msg)))...)
|
||||
b = append(b, msg...)
|
||||
|
||||
m[id] = Extension{enc: b}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
360
watchdog/vendor/github.com/golang/protobuf/proto/pointer_reflect.go
generated
vendored
360
watchdog/vendor/github.com/golang/protobuf/proto/pointer_reflect.go
generated
vendored
@ -1,360 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2012 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
// +build purego appengine js
|
||||
|
||||
// This file contains an implementation of proto field accesses using package reflect.
|
||||
// It is slower than the code in pointer_unsafe.go but it avoids package unsafe and can
|
||||
// be used on App Engine.
|
||||
|
||||
package proto
|
||||
|
||||
import (
|
||||
"reflect"
|
||||
"sync"
|
||||
)
|
||||
|
||||
const unsafeAllowed = false
|
||||
|
||||
// A field identifies a field in a struct, accessible from a pointer.
|
||||
// In this implementation, a field is identified by the sequence of field indices
|
||||
// passed to reflect's FieldByIndex.
|
||||
type field []int
|
||||
|
||||
// toField returns a field equivalent to the given reflect field.
|
||||
func toField(f *reflect.StructField) field {
|
||||
return f.Index
|
||||
}
|
||||
|
||||
// invalidField is an invalid field identifier.
|
||||
var invalidField = field(nil)
|
||||
|
||||
// zeroField is a noop when calling pointer.offset.
|
||||
var zeroField = field([]int{})
|
||||
|
||||
// IsValid reports whether the field identifier is valid.
|
||||
func (f field) IsValid() bool { return f != nil }
|
||||
|
||||
// The pointer type is for the table-driven decoder.
|
||||
// The implementation here uses a reflect.Value of pointer type to
|
||||
// create a generic pointer. In pointer_unsafe.go we use unsafe
|
||||
// instead of reflect to implement the same (but faster) interface.
|
||||
type pointer struct {
|
||||
v reflect.Value
|
||||
}
|
||||
|
||||
// toPointer converts an interface of pointer type to a pointer
|
||||
// that points to the same target.
|
||||
func toPointer(i *Message) pointer {
|
||||
return pointer{v: reflect.ValueOf(*i)}
|
||||
}
|
||||
|
||||
// toAddrPointer converts an interface to a pointer that points to
|
||||
// the interface data.
|
||||
func toAddrPointer(i *interface{}, isptr, deref bool) pointer {
|
||||
v := reflect.ValueOf(*i)
|
||||
u := reflect.New(v.Type())
|
||||
u.Elem().Set(v)
|
||||
if deref {
|
||||
u = u.Elem()
|
||||
}
|
||||
return pointer{v: u}
|
||||
}
|
||||
|
||||
// valToPointer converts v to a pointer. v must be of pointer type.
|
||||
func valToPointer(v reflect.Value) pointer {
|
||||
return pointer{v: v}
|
||||
}
|
||||
|
||||
// offset converts from a pointer to a structure to a pointer to
|
||||
// one of its fields.
|
||||
func (p pointer) offset(f field) pointer {
|
||||
return pointer{v: p.v.Elem().FieldByIndex(f).Addr()}
|
||||
}
|
||||
|
||||
func (p pointer) isNil() bool {
|
||||
return p.v.IsNil()
|
||||
}
|
||||
|
||||
// grow updates the slice s in place to make it one element longer.
|
||||
// s must be addressable.
|
||||
// Returns the (addressable) new element.
|
||||
func grow(s reflect.Value) reflect.Value {
|
||||
n, m := s.Len(), s.Cap()
|
||||
if n < m {
|
||||
s.SetLen(n + 1)
|
||||
} else {
|
||||
s.Set(reflect.Append(s, reflect.Zero(s.Type().Elem())))
|
||||
}
|
||||
return s.Index(n)
|
||||
}
|
||||
|
||||
func (p pointer) toInt64() *int64 {
|
||||
return p.v.Interface().(*int64)
|
||||
}
|
||||
func (p pointer) toInt64Ptr() **int64 {
|
||||
return p.v.Interface().(**int64)
|
||||
}
|
||||
func (p pointer) toInt64Slice() *[]int64 {
|
||||
return p.v.Interface().(*[]int64)
|
||||
}
|
||||
|
||||
var int32ptr = reflect.TypeOf((*int32)(nil))
|
||||
|
||||
func (p pointer) toInt32() *int32 {
|
||||
return p.v.Convert(int32ptr).Interface().(*int32)
|
||||
}
|
||||
|
||||
// The toInt32Ptr/Slice methods don't work because of enums.
|
||||
// Instead, we must use set/get methods for the int32ptr/slice case.
|
||||
/*
|
||||
func (p pointer) toInt32Ptr() **int32 {
|
||||
return p.v.Interface().(**int32)
|
||||
}
|
||||
func (p pointer) toInt32Slice() *[]int32 {
|
||||
return p.v.Interface().(*[]int32)
|
||||
}
|
||||
*/
|
||||
func (p pointer) getInt32Ptr() *int32 {
|
||||
if p.v.Type().Elem().Elem() == reflect.TypeOf(int32(0)) {
|
||||
// raw int32 type
|
||||
return p.v.Elem().Interface().(*int32)
|
||||
}
|
||||
// an enum
|
||||
return p.v.Elem().Convert(int32PtrType).Interface().(*int32)
|
||||
}
|
||||
func (p pointer) setInt32Ptr(v int32) {
|
||||
// Allocate value in a *int32. Possibly convert that to a *enum.
|
||||
// Then assign it to a **int32 or **enum.
|
||||
// Note: we can convert *int32 to *enum, but we can't convert
|
||||
// **int32 to **enum!
|
||||
p.v.Elem().Set(reflect.ValueOf(&v).Convert(p.v.Type().Elem()))
|
||||
}
|
||||
|
||||
// getInt32Slice copies []int32 from p as a new slice.
|
||||
// This behavior differs from the implementation in pointer_unsafe.go.
|
||||
func (p pointer) getInt32Slice() []int32 {
|
||||
if p.v.Type().Elem().Elem() == reflect.TypeOf(int32(0)) {
|
||||
// raw int32 type
|
||||
return p.v.Elem().Interface().([]int32)
|
||||
}
|
||||
// an enum
|
||||
// Allocate a []int32, then assign []enum's values into it.
|
||||
// Note: we can't convert []enum to []int32.
|
||||
slice := p.v.Elem()
|
||||
s := make([]int32, slice.Len())
|
||||
for i := 0; i < slice.Len(); i++ {
|
||||
s[i] = int32(slice.Index(i).Int())
|
||||
}
|
||||
return s
|
||||
}
|
||||
|
||||
// setInt32Slice copies []int32 into p as a new slice.
|
||||
// This behavior differs from the implementation in pointer_unsafe.go.
|
||||
func (p pointer) setInt32Slice(v []int32) {
|
||||
if p.v.Type().Elem().Elem() == reflect.TypeOf(int32(0)) {
|
||||
// raw int32 type
|
||||
p.v.Elem().Set(reflect.ValueOf(v))
|
||||
return
|
||||
}
|
||||
// an enum
|
||||
// Allocate a []enum, then assign []int32's values into it.
|
||||
// Note: we can't convert []enum to []int32.
|
||||
slice := reflect.MakeSlice(p.v.Type().Elem(), len(v), cap(v))
|
||||
for i, x := range v {
|
||||
slice.Index(i).SetInt(int64(x))
|
||||
}
|
||||
p.v.Elem().Set(slice)
|
||||
}
|
||||
func (p pointer) appendInt32Slice(v int32) {
|
||||
grow(p.v.Elem()).SetInt(int64(v))
|
||||
}
|
||||
|
||||
func (p pointer) toUint64() *uint64 {
|
||||
return p.v.Interface().(*uint64)
|
||||
}
|
||||
func (p pointer) toUint64Ptr() **uint64 {
|
||||
return p.v.Interface().(**uint64)
|
||||
}
|
||||
func (p pointer) toUint64Slice() *[]uint64 {
|
||||
return p.v.Interface().(*[]uint64)
|
||||
}
|
||||
func (p pointer) toUint32() *uint32 {
|
||||
return p.v.Interface().(*uint32)
|
||||
}
|
||||
func (p pointer) toUint32Ptr() **uint32 {
|
||||
return p.v.Interface().(**uint32)
|
||||
}
|
||||
func (p pointer) toUint32Slice() *[]uint32 {
|
||||
return p.v.Interface().(*[]uint32)
|
||||
}
|
||||
func (p pointer) toBool() *bool {
|
||||
return p.v.Interface().(*bool)
|
||||
}
|
||||
func (p pointer) toBoolPtr() **bool {
|
||||
return p.v.Interface().(**bool)
|
||||
}
|
||||
func (p pointer) toBoolSlice() *[]bool {
|
||||
return p.v.Interface().(*[]bool)
|
||||
}
|
||||
func (p pointer) toFloat64() *float64 {
|
||||
return p.v.Interface().(*float64)
|
||||
}
|
||||
func (p pointer) toFloat64Ptr() **float64 {
|
||||
return p.v.Interface().(**float64)
|
||||
}
|
||||
func (p pointer) toFloat64Slice() *[]float64 {
|
||||
return p.v.Interface().(*[]float64)
|
||||
}
|
||||
func (p pointer) toFloat32() *float32 {
|
||||
return p.v.Interface().(*float32)
|
||||
}
|
||||
func (p pointer) toFloat32Ptr() **float32 {
|
||||
return p.v.Interface().(**float32)
|
||||
}
|
||||
func (p pointer) toFloat32Slice() *[]float32 {
|
||||
return p.v.Interface().(*[]float32)
|
||||
}
|
||||
func (p pointer) toString() *string {
|
||||
return p.v.Interface().(*string)
|
||||
}
|
||||
func (p pointer) toStringPtr() **string {
|
||||
return p.v.Interface().(**string)
|
||||
}
|
||||
func (p pointer) toStringSlice() *[]string {
|
||||
return p.v.Interface().(*[]string)
|
||||
}
|
||||
func (p pointer) toBytes() *[]byte {
|
||||
return p.v.Interface().(*[]byte)
|
||||
}
|
||||
func (p pointer) toBytesSlice() *[][]byte {
|
||||
return p.v.Interface().(*[][]byte)
|
||||
}
|
||||
func (p pointer) toExtensions() *XXX_InternalExtensions {
|
||||
return p.v.Interface().(*XXX_InternalExtensions)
|
||||
}
|
||||
func (p pointer) toOldExtensions() *map[int32]Extension {
|
||||
return p.v.Interface().(*map[int32]Extension)
|
||||
}
|
||||
func (p pointer) getPointer() pointer {
|
||||
return pointer{v: p.v.Elem()}
|
||||
}
|
||||
func (p pointer) setPointer(q pointer) {
|
||||
p.v.Elem().Set(q.v)
|
||||
}
|
||||
func (p pointer) appendPointer(q pointer) {
|
||||
grow(p.v.Elem()).Set(q.v)
|
||||
}
|
||||
|
||||
// getPointerSlice copies []*T from p as a new []pointer.
|
||||
// This behavior differs from the implementation in pointer_unsafe.go.
|
||||
func (p pointer) getPointerSlice() []pointer {
|
||||
if p.v.IsNil() {
|
||||
return nil
|
||||
}
|
||||
n := p.v.Elem().Len()
|
||||
s := make([]pointer, n)
|
||||
for i := 0; i < n; i++ {
|
||||
s[i] = pointer{v: p.v.Elem().Index(i)}
|
||||
}
|
||||
return s
|
||||
}
|
||||
|
||||
// setPointerSlice copies []pointer into p as a new []*T.
|
||||
// This behavior differs from the implementation in pointer_unsafe.go.
|
||||
func (p pointer) setPointerSlice(v []pointer) {
|
||||
if v == nil {
|
||||
p.v.Elem().Set(reflect.New(p.v.Elem().Type()).Elem())
|
||||
return
|
||||
}
|
||||
s := reflect.MakeSlice(p.v.Elem().Type(), 0, len(v))
|
||||
for _, p := range v {
|
||||
s = reflect.Append(s, p.v)
|
||||
}
|
||||
p.v.Elem().Set(s)
|
||||
}
|
||||
|
||||
// getInterfacePointer returns a pointer that points to the
|
||||
// interface data of the interface pointed by p.
|
||||
func (p pointer) getInterfacePointer() pointer {
|
||||
if p.v.Elem().IsNil() {
|
||||
return pointer{v: p.v.Elem()}
|
||||
}
|
||||
return pointer{v: p.v.Elem().Elem().Elem().Field(0).Addr()} // *interface -> interface -> *struct -> struct
|
||||
}
|
||||
|
||||
func (p pointer) asPointerTo(t reflect.Type) reflect.Value {
|
||||
// TODO: check that p.v.Type().Elem() == t?
|
||||
return p.v
|
||||
}
|
||||
|
||||
func atomicLoadUnmarshalInfo(p **unmarshalInfo) *unmarshalInfo {
|
||||
atomicLock.Lock()
|
||||
defer atomicLock.Unlock()
|
||||
return *p
|
||||
}
|
||||
func atomicStoreUnmarshalInfo(p **unmarshalInfo, v *unmarshalInfo) {
|
||||
atomicLock.Lock()
|
||||
defer atomicLock.Unlock()
|
||||
*p = v
|
||||
}
|
||||
func atomicLoadMarshalInfo(p **marshalInfo) *marshalInfo {
|
||||
atomicLock.Lock()
|
||||
defer atomicLock.Unlock()
|
||||
return *p
|
||||
}
|
||||
func atomicStoreMarshalInfo(p **marshalInfo, v *marshalInfo) {
|
||||
atomicLock.Lock()
|
||||
defer atomicLock.Unlock()
|
||||
*p = v
|
||||
}
|
||||
func atomicLoadMergeInfo(p **mergeInfo) *mergeInfo {
|
||||
atomicLock.Lock()
|
||||
defer atomicLock.Unlock()
|
||||
return *p
|
||||
}
|
||||
func atomicStoreMergeInfo(p **mergeInfo, v *mergeInfo) {
|
||||
atomicLock.Lock()
|
||||
defer atomicLock.Unlock()
|
||||
*p = v
|
||||
}
|
||||
func atomicLoadDiscardInfo(p **discardInfo) *discardInfo {
|
||||
atomicLock.Lock()
|
||||
defer atomicLock.Unlock()
|
||||
return *p
|
||||
}
|
||||
func atomicStoreDiscardInfo(p **discardInfo, v *discardInfo) {
|
||||
atomicLock.Lock()
|
||||
defer atomicLock.Unlock()
|
||||
*p = v
|
||||
}
|
||||
|
||||
var atomicLock sync.Mutex
|
||||
313
watchdog/vendor/github.com/golang/protobuf/proto/pointer_unsafe.go
generated
vendored
313
watchdog/vendor/github.com/golang/protobuf/proto/pointer_unsafe.go
generated
vendored
@ -1,313 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2012 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
// +build !purego,!appengine,!js
|
||||
|
||||
// This file contains the implementation of the proto field accesses using package unsafe.
|
||||
|
||||
package proto
|
||||
|
||||
import (
|
||||
"reflect"
|
||||
"sync/atomic"
|
||||
"unsafe"
|
||||
)
|
||||
|
||||
const unsafeAllowed = true
|
||||
|
||||
// A field identifies a field in a struct, accessible from a pointer.
|
||||
// In this implementation, a field is identified by its byte offset from the start of the struct.
|
||||
type field uintptr
|
||||
|
||||
// toField returns a field equivalent to the given reflect field.
|
||||
func toField(f *reflect.StructField) field {
|
||||
return field(f.Offset)
|
||||
}
|
||||
|
||||
// invalidField is an invalid field identifier.
|
||||
const invalidField = ^field(0)
|
||||
|
||||
// zeroField is a noop when calling pointer.offset.
|
||||
const zeroField = field(0)
|
||||
|
||||
// IsValid reports whether the field identifier is valid.
|
||||
func (f field) IsValid() bool {
|
||||
return f != invalidField
|
||||
}
|
||||
|
||||
// The pointer type below is for the new table-driven encoder/decoder.
|
||||
// The implementation here uses unsafe.Pointer to create a generic pointer.
|
||||
// In pointer_reflect.go we use reflect instead of unsafe to implement
|
||||
// the same (but slower) interface.
|
||||
type pointer struct {
|
||||
p unsafe.Pointer
|
||||
}
|
||||
|
||||
// size of pointer
|
||||
var ptrSize = unsafe.Sizeof(uintptr(0))
|
||||
|
||||
// toPointer converts an interface of pointer type to a pointer
|
||||
// that points to the same target.
|
||||
func toPointer(i *Message) pointer {
|
||||
// Super-tricky - read pointer out of data word of interface value.
|
||||
// Saves ~25ns over the equivalent:
|
||||
// return valToPointer(reflect.ValueOf(*i))
|
||||
return pointer{p: (*[2]unsafe.Pointer)(unsafe.Pointer(i))[1]}
|
||||
}
|
||||
|
||||
// toAddrPointer converts an interface to a pointer that points to
|
||||
// the interface data.
|
||||
func toAddrPointer(i *interface{}, isptr, deref bool) (p pointer) {
|
||||
// Super-tricky - read or get the address of data word of interface value.
|
||||
if isptr {
|
||||
// The interface is of pointer type, thus it is a direct interface.
|
||||
// The data word is the pointer data itself. We take its address.
|
||||
p = pointer{p: unsafe.Pointer(uintptr(unsafe.Pointer(i)) + ptrSize)}
|
||||
} else {
|
||||
// The interface is not of pointer type. The data word is the pointer
|
||||
// to the data.
|
||||
p = pointer{p: (*[2]unsafe.Pointer)(unsafe.Pointer(i))[1]}
|
||||
}
|
||||
if deref {
|
||||
p.p = *(*unsafe.Pointer)(p.p)
|
||||
}
|
||||
return p
|
||||
}
|
||||
|
||||
// valToPointer converts v to a pointer. v must be of pointer type.
|
||||
func valToPointer(v reflect.Value) pointer {
|
||||
return pointer{p: unsafe.Pointer(v.Pointer())}
|
||||
}
|
||||
|
||||
// offset converts from a pointer to a structure to a pointer to
|
||||
// one of its fields.
|
||||
func (p pointer) offset(f field) pointer {
|
||||
// For safety, we should panic if !f.IsValid, however calling panic causes
|
||||
// this to no longer be inlineable, which is a serious performance cost.
|
||||
/*
|
||||
if !f.IsValid() {
|
||||
panic("invalid field")
|
||||
}
|
||||
*/
|
||||
return pointer{p: unsafe.Pointer(uintptr(p.p) + uintptr(f))}
|
||||
}
|
||||
|
||||
func (p pointer) isNil() bool {
|
||||
return p.p == nil
|
||||
}
|
||||
|
||||
func (p pointer) toInt64() *int64 {
|
||||
return (*int64)(p.p)
|
||||
}
|
||||
func (p pointer) toInt64Ptr() **int64 {
|
||||
return (**int64)(p.p)
|
||||
}
|
||||
func (p pointer) toInt64Slice() *[]int64 {
|
||||
return (*[]int64)(p.p)
|
||||
}
|
||||
func (p pointer) toInt32() *int32 {
|
||||
return (*int32)(p.p)
|
||||
}
|
||||
|
||||
// See pointer_reflect.go for why toInt32Ptr/Slice doesn't exist.
|
||||
/*
|
||||
func (p pointer) toInt32Ptr() **int32 {
|
||||
return (**int32)(p.p)
|
||||
}
|
||||
func (p pointer) toInt32Slice() *[]int32 {
|
||||
return (*[]int32)(p.p)
|
||||
}
|
||||
*/
|
||||
func (p pointer) getInt32Ptr() *int32 {
|
||||
return *(**int32)(p.p)
|
||||
}
|
||||
func (p pointer) setInt32Ptr(v int32) {
|
||||
*(**int32)(p.p) = &v
|
||||
}
|
||||
|
||||
// getInt32Slice loads a []int32 from p.
|
||||
// The value returned is aliased with the original slice.
|
||||
// This behavior differs from the implementation in pointer_reflect.go.
|
||||
func (p pointer) getInt32Slice() []int32 {
|
||||
return *(*[]int32)(p.p)
|
||||
}
|
||||
|
||||
// setInt32Slice stores a []int32 to p.
|
||||
// The value set is aliased with the input slice.
|
||||
// This behavior differs from the implementation in pointer_reflect.go.
|
||||
func (p pointer) setInt32Slice(v []int32) {
|
||||
*(*[]int32)(p.p) = v
|
||||
}
|
||||
|
||||
// TODO: Can we get rid of appendInt32Slice and use setInt32Slice instead?
|
||||
func (p pointer) appendInt32Slice(v int32) {
|
||||
s := (*[]int32)(p.p)
|
||||
*s = append(*s, v)
|
||||
}
|
||||
|
||||
func (p pointer) toUint64() *uint64 {
|
||||
return (*uint64)(p.p)
|
||||
}
|
||||
func (p pointer) toUint64Ptr() **uint64 {
|
||||
return (**uint64)(p.p)
|
||||
}
|
||||
func (p pointer) toUint64Slice() *[]uint64 {
|
||||
return (*[]uint64)(p.p)
|
||||
}
|
||||
func (p pointer) toUint32() *uint32 {
|
||||
return (*uint32)(p.p)
|
||||
}
|
||||
func (p pointer) toUint32Ptr() **uint32 {
|
||||
return (**uint32)(p.p)
|
||||
}
|
||||
func (p pointer) toUint32Slice() *[]uint32 {
|
||||
return (*[]uint32)(p.p)
|
||||
}
|
||||
func (p pointer) toBool() *bool {
|
||||
return (*bool)(p.p)
|
||||
}
|
||||
func (p pointer) toBoolPtr() **bool {
|
||||
return (**bool)(p.p)
|
||||
}
|
||||
func (p pointer) toBoolSlice() *[]bool {
|
||||
return (*[]bool)(p.p)
|
||||
}
|
||||
func (p pointer) toFloat64() *float64 {
|
||||
return (*float64)(p.p)
|
||||
}
|
||||
func (p pointer) toFloat64Ptr() **float64 {
|
||||
return (**float64)(p.p)
|
||||
}
|
||||
func (p pointer) toFloat64Slice() *[]float64 {
|
||||
return (*[]float64)(p.p)
|
||||
}
|
||||
func (p pointer) toFloat32() *float32 {
|
||||
return (*float32)(p.p)
|
||||
}
|
||||
func (p pointer) toFloat32Ptr() **float32 {
|
||||
return (**float32)(p.p)
|
||||
}
|
||||
func (p pointer) toFloat32Slice() *[]float32 {
|
||||
return (*[]float32)(p.p)
|
||||
}
|
||||
func (p pointer) toString() *string {
|
||||
return (*string)(p.p)
|
||||
}
|
||||
func (p pointer) toStringPtr() **string {
|
||||
return (**string)(p.p)
|
||||
}
|
||||
func (p pointer) toStringSlice() *[]string {
|
||||
return (*[]string)(p.p)
|
||||
}
|
||||
func (p pointer) toBytes() *[]byte {
|
||||
return (*[]byte)(p.p)
|
||||
}
|
||||
func (p pointer) toBytesSlice() *[][]byte {
|
||||
return (*[][]byte)(p.p)
|
||||
}
|
||||
func (p pointer) toExtensions() *XXX_InternalExtensions {
|
||||
return (*XXX_InternalExtensions)(p.p)
|
||||
}
|
||||
func (p pointer) toOldExtensions() *map[int32]Extension {
|
||||
return (*map[int32]Extension)(p.p)
|
||||
}
|
||||
|
||||
// getPointerSlice loads []*T from p as a []pointer.
|
||||
// The value returned is aliased with the original slice.
|
||||
// This behavior differs from the implementation in pointer_reflect.go.
|
||||
func (p pointer) getPointerSlice() []pointer {
|
||||
// Super-tricky - p should point to a []*T where T is a
|
||||
// message type. We load it as []pointer.
|
||||
return *(*[]pointer)(p.p)
|
||||
}
|
||||
|
||||
// setPointerSlice stores []pointer into p as a []*T.
|
||||
// The value set is aliased with the input slice.
|
||||
// This behavior differs from the implementation in pointer_reflect.go.
|
||||
func (p pointer) setPointerSlice(v []pointer) {
|
||||
// Super-tricky - p should point to a []*T where T is a
|
||||
// message type. We store it as []pointer.
|
||||
*(*[]pointer)(p.p) = v
|
||||
}
|
||||
|
||||
// getPointer loads the pointer at p and returns it.
|
||||
func (p pointer) getPointer() pointer {
|
||||
return pointer{p: *(*unsafe.Pointer)(p.p)}
|
||||
}
|
||||
|
||||
// setPointer stores the pointer q at p.
|
||||
func (p pointer) setPointer(q pointer) {
|
||||
*(*unsafe.Pointer)(p.p) = q.p
|
||||
}
|
||||
|
||||
// append q to the slice pointed to by p.
|
||||
func (p pointer) appendPointer(q pointer) {
|
||||
s := (*[]unsafe.Pointer)(p.p)
|
||||
*s = append(*s, q.p)
|
||||
}
|
||||
|
||||
// getInterfacePointer returns a pointer that points to the
|
||||
// interface data of the interface pointed by p.
|
||||
func (p pointer) getInterfacePointer() pointer {
|
||||
// Super-tricky - read pointer out of data word of interface value.
|
||||
return pointer{p: (*(*[2]unsafe.Pointer)(p.p))[1]}
|
||||
}
|
||||
|
||||
// asPointerTo returns a reflect.Value that is a pointer to an
|
||||
// object of type t stored at p.
|
||||
func (p pointer) asPointerTo(t reflect.Type) reflect.Value {
|
||||
return reflect.NewAt(t, p.p)
|
||||
}
|
||||
|
||||
func atomicLoadUnmarshalInfo(p **unmarshalInfo) *unmarshalInfo {
|
||||
return (*unmarshalInfo)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(p))))
|
||||
}
|
||||
func atomicStoreUnmarshalInfo(p **unmarshalInfo, v *unmarshalInfo) {
|
||||
atomic.StorePointer((*unsafe.Pointer)(unsafe.Pointer(p)), unsafe.Pointer(v))
|
||||
}
|
||||
func atomicLoadMarshalInfo(p **marshalInfo) *marshalInfo {
|
||||
return (*marshalInfo)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(p))))
|
||||
}
|
||||
func atomicStoreMarshalInfo(p **marshalInfo, v *marshalInfo) {
|
||||
atomic.StorePointer((*unsafe.Pointer)(unsafe.Pointer(p)), unsafe.Pointer(v))
|
||||
}
|
||||
func atomicLoadMergeInfo(p **mergeInfo) *mergeInfo {
|
||||
return (*mergeInfo)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(p))))
|
||||
}
|
||||
func atomicStoreMergeInfo(p **mergeInfo, v *mergeInfo) {
|
||||
atomic.StorePointer((*unsafe.Pointer)(unsafe.Pointer(p)), unsafe.Pointer(v))
|
||||
}
|
||||
func atomicLoadDiscardInfo(p **discardInfo) *discardInfo {
|
||||
return (*discardInfo)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(p))))
|
||||
}
|
||||
func atomicStoreDiscardInfo(p **discardInfo, v *discardInfo) {
|
||||
atomic.StorePointer((*unsafe.Pointer)(unsafe.Pointer(p)), unsafe.Pointer(v))
|
||||
}
|
||||
545
watchdog/vendor/github.com/golang/protobuf/proto/properties.go
generated
vendored
545
watchdog/vendor/github.com/golang/protobuf/proto/properties.go
generated
vendored
@ -1,545 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2010 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
package proto
|
||||
|
||||
/*
|
||||
* Routines for encoding data into the wire format for protocol buffers.
|
||||
*/
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"log"
|
||||
"os"
|
||||
"reflect"
|
||||
"sort"
|
||||
"strconv"
|
||||
"strings"
|
||||
"sync"
|
||||
)
|
||||
|
||||
const debug bool = false
|
||||
|
||||
// Constants that identify the encoding of a value on the wire.
|
||||
const (
|
||||
WireVarint = 0
|
||||
WireFixed64 = 1
|
||||
WireBytes = 2
|
||||
WireStartGroup = 3
|
||||
WireEndGroup = 4
|
||||
WireFixed32 = 5
|
||||
)
|
||||
|
||||
// tagMap is an optimization over map[int]int for typical protocol buffer
|
||||
// use-cases. Encoded protocol buffers are often in tag order with small tag
|
||||
// numbers.
|
||||
type tagMap struct {
|
||||
fastTags []int
|
||||
slowTags map[int]int
|
||||
}
|
||||
|
||||
// tagMapFastLimit is the upper bound on the tag number that will be stored in
|
||||
// the tagMap slice rather than its map.
|
||||
const tagMapFastLimit = 1024
|
||||
|
||||
func (p *tagMap) get(t int) (int, bool) {
|
||||
if t > 0 && t < tagMapFastLimit {
|
||||
if t >= len(p.fastTags) {
|
||||
return 0, false
|
||||
}
|
||||
fi := p.fastTags[t]
|
||||
return fi, fi >= 0
|
||||
}
|
||||
fi, ok := p.slowTags[t]
|
||||
return fi, ok
|
||||
}
|
||||
|
||||
func (p *tagMap) put(t int, fi int) {
|
||||
if t > 0 && t < tagMapFastLimit {
|
||||
for len(p.fastTags) < t+1 {
|
||||
p.fastTags = append(p.fastTags, -1)
|
||||
}
|
||||
p.fastTags[t] = fi
|
||||
return
|
||||
}
|
||||
if p.slowTags == nil {
|
||||
p.slowTags = make(map[int]int)
|
||||
}
|
||||
p.slowTags[t] = fi
|
||||
}
|
||||
|
||||
// StructProperties represents properties for all the fields of a struct.
|
||||
// decoderTags and decoderOrigNames should only be used by the decoder.
|
||||
type StructProperties struct {
|
||||
Prop []*Properties // properties for each field
|
||||
reqCount int // required count
|
||||
decoderTags tagMap // map from proto tag to struct field number
|
||||
decoderOrigNames map[string]int // map from original name to struct field number
|
||||
order []int // list of struct field numbers in tag order
|
||||
|
||||
// OneofTypes contains information about the oneof fields in this message.
|
||||
// It is keyed by the original name of a field.
|
||||
OneofTypes map[string]*OneofProperties
|
||||
}
|
||||
|
||||
// OneofProperties represents information about a specific field in a oneof.
|
||||
type OneofProperties struct {
|
||||
Type reflect.Type // pointer to generated struct type for this oneof field
|
||||
Field int // struct field number of the containing oneof in the message
|
||||
Prop *Properties
|
||||
}
|
||||
|
||||
// Implement the sorting interface so we can sort the fields in tag order, as recommended by the spec.
|
||||
// See encode.go, (*Buffer).enc_struct.
|
||||
|
||||
func (sp *StructProperties) Len() int { return len(sp.order) }
|
||||
func (sp *StructProperties) Less(i, j int) bool {
|
||||
return sp.Prop[sp.order[i]].Tag < sp.Prop[sp.order[j]].Tag
|
||||
}
|
||||
func (sp *StructProperties) Swap(i, j int) { sp.order[i], sp.order[j] = sp.order[j], sp.order[i] }
|
||||
|
||||
// Properties represents the protocol-specific behavior of a single struct field.
|
||||
type Properties struct {
|
||||
Name string // name of the field, for error messages
|
||||
OrigName string // original name before protocol compiler (always set)
|
||||
JSONName string // name to use for JSON; determined by protoc
|
||||
Wire string
|
||||
WireType int
|
||||
Tag int
|
||||
Required bool
|
||||
Optional bool
|
||||
Repeated bool
|
||||
Packed bool // relevant for repeated primitives only
|
||||
Enum string // set for enum types only
|
||||
proto3 bool // whether this is known to be a proto3 field
|
||||
oneof bool // whether this is a oneof field
|
||||
|
||||
Default string // default value
|
||||
HasDefault bool // whether an explicit default was provided
|
||||
|
||||
stype reflect.Type // set for struct types only
|
||||
sprop *StructProperties // set for struct types only
|
||||
|
||||
mtype reflect.Type // set for map types only
|
||||
MapKeyProp *Properties // set for map types only
|
||||
MapValProp *Properties // set for map types only
|
||||
}
|
||||
|
||||
// String formats the properties in the protobuf struct field tag style.
|
||||
func (p *Properties) String() string {
|
||||
s := p.Wire
|
||||
s += ","
|
||||
s += strconv.Itoa(p.Tag)
|
||||
if p.Required {
|
||||
s += ",req"
|
||||
}
|
||||
if p.Optional {
|
||||
s += ",opt"
|
||||
}
|
||||
if p.Repeated {
|
||||
s += ",rep"
|
||||
}
|
||||
if p.Packed {
|
||||
s += ",packed"
|
||||
}
|
||||
s += ",name=" + p.OrigName
|
||||
if p.JSONName != p.OrigName {
|
||||
s += ",json=" + p.JSONName
|
||||
}
|
||||
if p.proto3 {
|
||||
s += ",proto3"
|
||||
}
|
||||
if p.oneof {
|
||||
s += ",oneof"
|
||||
}
|
||||
if len(p.Enum) > 0 {
|
||||
s += ",enum=" + p.Enum
|
||||
}
|
||||
if p.HasDefault {
|
||||
s += ",def=" + p.Default
|
||||
}
|
||||
return s
|
||||
}
|
||||
|
||||
// Parse populates p by parsing a string in the protobuf struct field tag style.
|
||||
func (p *Properties) Parse(s string) {
|
||||
// "bytes,49,opt,name=foo,def=hello!"
|
||||
fields := strings.Split(s, ",") // breaks def=, but handled below.
|
||||
if len(fields) < 2 {
|
||||
fmt.Fprintf(os.Stderr, "proto: tag has too few fields: %q\n", s)
|
||||
return
|
||||
}
|
||||
|
||||
p.Wire = fields[0]
|
||||
switch p.Wire {
|
||||
case "varint":
|
||||
p.WireType = WireVarint
|
||||
case "fixed32":
|
||||
p.WireType = WireFixed32
|
||||
case "fixed64":
|
||||
p.WireType = WireFixed64
|
||||
case "zigzag32":
|
||||
p.WireType = WireVarint
|
||||
case "zigzag64":
|
||||
p.WireType = WireVarint
|
||||
case "bytes", "group":
|
||||
p.WireType = WireBytes
|
||||
// no numeric converter for non-numeric types
|
||||
default:
|
||||
fmt.Fprintf(os.Stderr, "proto: tag has unknown wire type: %q\n", s)
|
||||
return
|
||||
}
|
||||
|
||||
var err error
|
||||
p.Tag, err = strconv.Atoi(fields[1])
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
|
||||
outer:
|
||||
for i := 2; i < len(fields); i++ {
|
||||
f := fields[i]
|
||||
switch {
|
||||
case f == "req":
|
||||
p.Required = true
|
||||
case f == "opt":
|
||||
p.Optional = true
|
||||
case f == "rep":
|
||||
p.Repeated = true
|
||||
case f == "packed":
|
||||
p.Packed = true
|
||||
case strings.HasPrefix(f, "name="):
|
||||
p.OrigName = f[5:]
|
||||
case strings.HasPrefix(f, "json="):
|
||||
p.JSONName = f[5:]
|
||||
case strings.HasPrefix(f, "enum="):
|
||||
p.Enum = f[5:]
|
||||
case f == "proto3":
|
||||
p.proto3 = true
|
||||
case f == "oneof":
|
||||
p.oneof = true
|
||||
case strings.HasPrefix(f, "def="):
|
||||
p.HasDefault = true
|
||||
p.Default = f[4:] // rest of string
|
||||
if i+1 < len(fields) {
|
||||
// Commas aren't escaped, and def is always last.
|
||||
p.Default += "," + strings.Join(fields[i+1:], ",")
|
||||
break outer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
var protoMessageType = reflect.TypeOf((*Message)(nil)).Elem()
|
||||
|
||||
// setFieldProps initializes the field properties for submessages and maps.
|
||||
func (p *Properties) setFieldProps(typ reflect.Type, f *reflect.StructField, lockGetProp bool) {
|
||||
switch t1 := typ; t1.Kind() {
|
||||
case reflect.Ptr:
|
||||
if t1.Elem().Kind() == reflect.Struct {
|
||||
p.stype = t1.Elem()
|
||||
}
|
||||
|
||||
case reflect.Slice:
|
||||
if t2 := t1.Elem(); t2.Kind() == reflect.Ptr && t2.Elem().Kind() == reflect.Struct {
|
||||
p.stype = t2.Elem()
|
||||
}
|
||||
|
||||
case reflect.Map:
|
||||
p.mtype = t1
|
||||
p.MapKeyProp = &Properties{}
|
||||
p.MapKeyProp.init(reflect.PtrTo(p.mtype.Key()), "Key", f.Tag.Get("protobuf_key"), nil, lockGetProp)
|
||||
p.MapValProp = &Properties{}
|
||||
vtype := p.mtype.Elem()
|
||||
if vtype.Kind() != reflect.Ptr && vtype.Kind() != reflect.Slice {
|
||||
// The value type is not a message (*T) or bytes ([]byte),
|
||||
// so we need encoders for the pointer to this type.
|
||||
vtype = reflect.PtrTo(vtype)
|
||||
}
|
||||
p.MapValProp.init(vtype, "Value", f.Tag.Get("protobuf_val"), nil, lockGetProp)
|
||||
}
|
||||
|
||||
if p.stype != nil {
|
||||
if lockGetProp {
|
||||
p.sprop = GetProperties(p.stype)
|
||||
} else {
|
||||
p.sprop = getPropertiesLocked(p.stype)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
var (
|
||||
marshalerType = reflect.TypeOf((*Marshaler)(nil)).Elem()
|
||||
)
|
||||
|
||||
// Init populates the properties from a protocol buffer struct tag.
|
||||
func (p *Properties) Init(typ reflect.Type, name, tag string, f *reflect.StructField) {
|
||||
p.init(typ, name, tag, f, true)
|
||||
}
|
||||
|
||||
func (p *Properties) init(typ reflect.Type, name, tag string, f *reflect.StructField, lockGetProp bool) {
|
||||
// "bytes,49,opt,def=hello!"
|
||||
p.Name = name
|
||||
p.OrigName = name
|
||||
if tag == "" {
|
||||
return
|
||||
}
|
||||
p.Parse(tag)
|
||||
p.setFieldProps(typ, f, lockGetProp)
|
||||
}
|
||||
|
||||
var (
|
||||
propertiesMu sync.RWMutex
|
||||
propertiesMap = make(map[reflect.Type]*StructProperties)
|
||||
)
|
||||
|
||||
// GetProperties returns the list of properties for the type represented by t.
|
||||
// t must represent a generated struct type of a protocol message.
|
||||
func GetProperties(t reflect.Type) *StructProperties {
|
||||
if t.Kind() != reflect.Struct {
|
||||
panic("proto: type must have kind struct")
|
||||
}
|
||||
|
||||
// Most calls to GetProperties in a long-running program will be
|
||||
// retrieving details for types we have seen before.
|
||||
propertiesMu.RLock()
|
||||
sprop, ok := propertiesMap[t]
|
||||
propertiesMu.RUnlock()
|
||||
if ok {
|
||||
return sprop
|
||||
}
|
||||
|
||||
propertiesMu.Lock()
|
||||
sprop = getPropertiesLocked(t)
|
||||
propertiesMu.Unlock()
|
||||
return sprop
|
||||
}
|
||||
|
||||
type (
|
||||
oneofFuncsIface interface {
|
||||
XXX_OneofFuncs() (func(Message, *Buffer) error, func(Message, int, int, *Buffer) (bool, error), func(Message) int, []interface{})
|
||||
}
|
||||
oneofWrappersIface interface {
|
||||
XXX_OneofWrappers() []interface{}
|
||||
}
|
||||
)
|
||||
|
||||
// getPropertiesLocked requires that propertiesMu is held.
|
||||
func getPropertiesLocked(t reflect.Type) *StructProperties {
|
||||
if prop, ok := propertiesMap[t]; ok {
|
||||
return prop
|
||||
}
|
||||
|
||||
prop := new(StructProperties)
|
||||
// in case of recursive protos, fill this in now.
|
||||
propertiesMap[t] = prop
|
||||
|
||||
// build properties
|
||||
prop.Prop = make([]*Properties, t.NumField())
|
||||
prop.order = make([]int, t.NumField())
|
||||
|
||||
for i := 0; i < t.NumField(); i++ {
|
||||
f := t.Field(i)
|
||||
p := new(Properties)
|
||||
name := f.Name
|
||||
p.init(f.Type, name, f.Tag.Get("protobuf"), &f, false)
|
||||
|
||||
oneof := f.Tag.Get("protobuf_oneof") // special case
|
||||
if oneof != "" {
|
||||
// Oneof fields don't use the traditional protobuf tag.
|
||||
p.OrigName = oneof
|
||||
}
|
||||
prop.Prop[i] = p
|
||||
prop.order[i] = i
|
||||
if debug {
|
||||
print(i, " ", f.Name, " ", t.String(), " ")
|
||||
if p.Tag > 0 {
|
||||
print(p.String())
|
||||
}
|
||||
print("\n")
|
||||
}
|
||||
}
|
||||
|
||||
// Re-order prop.order.
|
||||
sort.Sort(prop)
|
||||
|
||||
var oots []interface{}
|
||||
switch m := reflect.Zero(reflect.PtrTo(t)).Interface().(type) {
|
||||
case oneofFuncsIface:
|
||||
_, _, _, oots = m.XXX_OneofFuncs()
|
||||
case oneofWrappersIface:
|
||||
oots = m.XXX_OneofWrappers()
|
||||
}
|
||||
if len(oots) > 0 {
|
||||
// Interpret oneof metadata.
|
||||
prop.OneofTypes = make(map[string]*OneofProperties)
|
||||
for _, oot := range oots {
|
||||
oop := &OneofProperties{
|
||||
Type: reflect.ValueOf(oot).Type(), // *T
|
||||
Prop: new(Properties),
|
||||
}
|
||||
sft := oop.Type.Elem().Field(0)
|
||||
oop.Prop.Name = sft.Name
|
||||
oop.Prop.Parse(sft.Tag.Get("protobuf"))
|
||||
// There will be exactly one interface field that
|
||||
// this new value is assignable to.
|
||||
for i := 0; i < t.NumField(); i++ {
|
||||
f := t.Field(i)
|
||||
if f.Type.Kind() != reflect.Interface {
|
||||
continue
|
||||
}
|
||||
if !oop.Type.AssignableTo(f.Type) {
|
||||
continue
|
||||
}
|
||||
oop.Field = i
|
||||
break
|
||||
}
|
||||
prop.OneofTypes[oop.Prop.OrigName] = oop
|
||||
}
|
||||
}
|
||||
|
||||
// build required counts
|
||||
// build tags
|
||||
reqCount := 0
|
||||
prop.decoderOrigNames = make(map[string]int)
|
||||
for i, p := range prop.Prop {
|
||||
if strings.HasPrefix(p.Name, "XXX_") {
|
||||
// Internal fields should not appear in tags/origNames maps.
|
||||
// They are handled specially when encoding and decoding.
|
||||
continue
|
||||
}
|
||||
if p.Required {
|
||||
reqCount++
|
||||
}
|
||||
prop.decoderTags.put(p.Tag, i)
|
||||
prop.decoderOrigNames[p.OrigName] = i
|
||||
}
|
||||
prop.reqCount = reqCount
|
||||
|
||||
return prop
|
||||
}
|
||||
|
||||
// A global registry of enum types.
|
||||
// The generated code will register the generated maps by calling RegisterEnum.
|
||||
|
||||
var enumValueMaps = make(map[string]map[string]int32)
|
||||
|
||||
// RegisterEnum is called from the generated code to install the enum descriptor
|
||||
// maps into the global table to aid parsing text format protocol buffers.
|
||||
func RegisterEnum(typeName string, unusedNameMap map[int32]string, valueMap map[string]int32) {
|
||||
if _, ok := enumValueMaps[typeName]; ok {
|
||||
panic("proto: duplicate enum registered: " + typeName)
|
||||
}
|
||||
enumValueMaps[typeName] = valueMap
|
||||
}
|
||||
|
||||
// EnumValueMap returns the mapping from names to integers of the
|
||||
// enum type enumType, or a nil if not found.
|
||||
func EnumValueMap(enumType string) map[string]int32 {
|
||||
return enumValueMaps[enumType]
|
||||
}
|
||||
|
||||
// A registry of all linked message types.
|
||||
// The string is a fully-qualified proto name ("pkg.Message").
|
||||
var (
|
||||
protoTypedNils = make(map[string]Message) // a map from proto names to typed nil pointers
|
||||
protoMapTypes = make(map[string]reflect.Type) // a map from proto names to map types
|
||||
revProtoTypes = make(map[reflect.Type]string)
|
||||
)
|
||||
|
||||
// RegisterType is called from generated code and maps from the fully qualified
|
||||
// proto name to the type (pointer to struct) of the protocol buffer.
|
||||
func RegisterType(x Message, name string) {
|
||||
if _, ok := protoTypedNils[name]; ok {
|
||||
// TODO: Some day, make this a panic.
|
||||
log.Printf("proto: duplicate proto type registered: %s", name)
|
||||
return
|
||||
}
|
||||
t := reflect.TypeOf(x)
|
||||
if v := reflect.ValueOf(x); v.Kind() == reflect.Ptr && v.Pointer() == 0 {
|
||||
// Generated code always calls RegisterType with nil x.
|
||||
// This check is just for extra safety.
|
||||
protoTypedNils[name] = x
|
||||
} else {
|
||||
protoTypedNils[name] = reflect.Zero(t).Interface().(Message)
|
||||
}
|
||||
revProtoTypes[t] = name
|
||||
}
|
||||
|
||||
// RegisterMapType is called from generated code and maps from the fully qualified
|
||||
// proto name to the native map type of the proto map definition.
|
||||
func RegisterMapType(x interface{}, name string) {
|
||||
if reflect.TypeOf(x).Kind() != reflect.Map {
|
||||
panic(fmt.Sprintf("RegisterMapType(%T, %q); want map", x, name))
|
||||
}
|
||||
if _, ok := protoMapTypes[name]; ok {
|
||||
log.Printf("proto: duplicate proto type registered: %s", name)
|
||||
return
|
||||
}
|
||||
t := reflect.TypeOf(x)
|
||||
protoMapTypes[name] = t
|
||||
revProtoTypes[t] = name
|
||||
}
|
||||
|
||||
// MessageName returns the fully-qualified proto name for the given message type.
|
||||
func MessageName(x Message) string {
|
||||
type xname interface {
|
||||
XXX_MessageName() string
|
||||
}
|
||||
if m, ok := x.(xname); ok {
|
||||
return m.XXX_MessageName()
|
||||
}
|
||||
return revProtoTypes[reflect.TypeOf(x)]
|
||||
}
|
||||
|
||||
// MessageType returns the message type (pointer to struct) for a named message.
|
||||
// The type is not guaranteed to implement proto.Message if the name refers to a
|
||||
// map entry.
|
||||
func MessageType(name string) reflect.Type {
|
||||
if t, ok := protoTypedNils[name]; ok {
|
||||
return reflect.TypeOf(t)
|
||||
}
|
||||
return protoMapTypes[name]
|
||||
}
|
||||
|
||||
// A registry of all linked proto files.
|
||||
var (
|
||||
protoFiles = make(map[string][]byte) // file name => fileDescriptor
|
||||
)
|
||||
|
||||
// RegisterFile is called from generated code and maps from the
|
||||
// full file name of a .proto file to its compressed FileDescriptorProto.
|
||||
func RegisterFile(filename string, fileDescriptor []byte) {
|
||||
protoFiles[filename] = fileDescriptor
|
||||
}
|
||||
|
||||
// FileDescriptor returns the compressed FileDescriptorProto for a .proto file.
|
||||
func FileDescriptor(filename string) []byte { return protoFiles[filename] }
|
||||
2776
watchdog/vendor/github.com/golang/protobuf/proto/table_marshal.go
generated
vendored
2776
watchdog/vendor/github.com/golang/protobuf/proto/table_marshal.go
generated
vendored
File diff suppressed because it is too large
Load Diff
654
watchdog/vendor/github.com/golang/protobuf/proto/table_merge.go
generated
vendored
654
watchdog/vendor/github.com/golang/protobuf/proto/table_merge.go
generated
vendored
@ -1,654 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2016 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
package proto
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"reflect"
|
||||
"strings"
|
||||
"sync"
|
||||
"sync/atomic"
|
||||
)
|
||||
|
||||
// Merge merges the src message into dst.
|
||||
// This assumes that dst and src of the same type and are non-nil.
|
||||
func (a *InternalMessageInfo) Merge(dst, src Message) {
|
||||
mi := atomicLoadMergeInfo(&a.merge)
|
||||
if mi == nil {
|
||||
mi = getMergeInfo(reflect.TypeOf(dst).Elem())
|
||||
atomicStoreMergeInfo(&a.merge, mi)
|
||||
}
|
||||
mi.merge(toPointer(&dst), toPointer(&src))
|
||||
}
|
||||
|
||||
type mergeInfo struct {
|
||||
typ reflect.Type
|
||||
|
||||
initialized int32 // 0: only typ is valid, 1: everything is valid
|
||||
lock sync.Mutex
|
||||
|
||||
fields []mergeFieldInfo
|
||||
unrecognized field // Offset of XXX_unrecognized
|
||||
}
|
||||
|
||||
type mergeFieldInfo struct {
|
||||
field field // Offset of field, guaranteed to be valid
|
||||
|
||||
// isPointer reports whether the value in the field is a pointer.
|
||||
// This is true for the following situations:
|
||||
// * Pointer to struct
|
||||
// * Pointer to basic type (proto2 only)
|
||||
// * Slice (first value in slice header is a pointer)
|
||||
// * String (first value in string header is a pointer)
|
||||
isPointer bool
|
||||
|
||||
// basicWidth reports the width of the field assuming that it is directly
|
||||
// embedded in the struct (as is the case for basic types in proto3).
|
||||
// The possible values are:
|
||||
// 0: invalid
|
||||
// 1: bool
|
||||
// 4: int32, uint32, float32
|
||||
// 8: int64, uint64, float64
|
||||
basicWidth int
|
||||
|
||||
// Where dst and src are pointers to the types being merged.
|
||||
merge func(dst, src pointer)
|
||||
}
|
||||
|
||||
var (
|
||||
mergeInfoMap = map[reflect.Type]*mergeInfo{}
|
||||
mergeInfoLock sync.Mutex
|
||||
)
|
||||
|
||||
func getMergeInfo(t reflect.Type) *mergeInfo {
|
||||
mergeInfoLock.Lock()
|
||||
defer mergeInfoLock.Unlock()
|
||||
mi := mergeInfoMap[t]
|
||||
if mi == nil {
|
||||
mi = &mergeInfo{typ: t}
|
||||
mergeInfoMap[t] = mi
|
||||
}
|
||||
return mi
|
||||
}
|
||||
|
||||
// merge merges src into dst assuming they are both of type *mi.typ.
|
||||
func (mi *mergeInfo) merge(dst, src pointer) {
|
||||
if dst.isNil() {
|
||||
panic("proto: nil destination")
|
||||
}
|
||||
if src.isNil() {
|
||||
return // Nothing to do.
|
||||
}
|
||||
|
||||
if atomic.LoadInt32(&mi.initialized) == 0 {
|
||||
mi.computeMergeInfo()
|
||||
}
|
||||
|
||||
for _, fi := range mi.fields {
|
||||
sfp := src.offset(fi.field)
|
||||
|
||||
// As an optimization, we can avoid the merge function call cost
|
||||
// if we know for sure that the source will have no effect
|
||||
// by checking if it is the zero value.
|
||||
if unsafeAllowed {
|
||||
if fi.isPointer && sfp.getPointer().isNil() { // Could be slice or string
|
||||
continue
|
||||
}
|
||||
if fi.basicWidth > 0 {
|
||||
switch {
|
||||
case fi.basicWidth == 1 && !*sfp.toBool():
|
||||
continue
|
||||
case fi.basicWidth == 4 && *sfp.toUint32() == 0:
|
||||
continue
|
||||
case fi.basicWidth == 8 && *sfp.toUint64() == 0:
|
||||
continue
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
dfp := dst.offset(fi.field)
|
||||
fi.merge(dfp, sfp)
|
||||
}
|
||||
|
||||
// TODO: Make this faster?
|
||||
out := dst.asPointerTo(mi.typ).Elem()
|
||||
in := src.asPointerTo(mi.typ).Elem()
|
||||
if emIn, err := extendable(in.Addr().Interface()); err == nil {
|
||||
emOut, _ := extendable(out.Addr().Interface())
|
||||
mIn, muIn := emIn.extensionsRead()
|
||||
if mIn != nil {
|
||||
mOut := emOut.extensionsWrite()
|
||||
muIn.Lock()
|
||||
mergeExtension(mOut, mIn)
|
||||
muIn.Unlock()
|
||||
}
|
||||
}
|
||||
|
||||
if mi.unrecognized.IsValid() {
|
||||
if b := *src.offset(mi.unrecognized).toBytes(); len(b) > 0 {
|
||||
*dst.offset(mi.unrecognized).toBytes() = append([]byte(nil), b...)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (mi *mergeInfo) computeMergeInfo() {
|
||||
mi.lock.Lock()
|
||||
defer mi.lock.Unlock()
|
||||
if mi.initialized != 0 {
|
||||
return
|
||||
}
|
||||
t := mi.typ
|
||||
n := t.NumField()
|
||||
|
||||
props := GetProperties(t)
|
||||
for i := 0; i < n; i++ {
|
||||
f := t.Field(i)
|
||||
if strings.HasPrefix(f.Name, "XXX_") {
|
||||
continue
|
||||
}
|
||||
|
||||
mfi := mergeFieldInfo{field: toField(&f)}
|
||||
tf := f.Type
|
||||
|
||||
// As an optimization, we can avoid the merge function call cost
|
||||
// if we know for sure that the source will have no effect
|
||||
// by checking if it is the zero value.
|
||||
if unsafeAllowed {
|
||||
switch tf.Kind() {
|
||||
case reflect.Ptr, reflect.Slice, reflect.String:
|
||||
// As a special case, we assume slices and strings are pointers
|
||||
// since we know that the first field in the SliceSlice or
|
||||
// StringHeader is a data pointer.
|
||||
mfi.isPointer = true
|
||||
case reflect.Bool:
|
||||
mfi.basicWidth = 1
|
||||
case reflect.Int32, reflect.Uint32, reflect.Float32:
|
||||
mfi.basicWidth = 4
|
||||
case reflect.Int64, reflect.Uint64, reflect.Float64:
|
||||
mfi.basicWidth = 8
|
||||
}
|
||||
}
|
||||
|
||||
// Unwrap tf to get at its most basic type.
|
||||
var isPointer, isSlice bool
|
||||
if tf.Kind() == reflect.Slice && tf.Elem().Kind() != reflect.Uint8 {
|
||||
isSlice = true
|
||||
tf = tf.Elem()
|
||||
}
|
||||
if tf.Kind() == reflect.Ptr {
|
||||
isPointer = true
|
||||
tf = tf.Elem()
|
||||
}
|
||||
if isPointer && isSlice && tf.Kind() != reflect.Struct {
|
||||
panic("both pointer and slice for basic type in " + tf.Name())
|
||||
}
|
||||
|
||||
switch tf.Kind() {
|
||||
case reflect.Int32:
|
||||
switch {
|
||||
case isSlice: // E.g., []int32
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
// NOTE: toInt32Slice is not defined (see pointer_reflect.go).
|
||||
/*
|
||||
sfsp := src.toInt32Slice()
|
||||
if *sfsp != nil {
|
||||
dfsp := dst.toInt32Slice()
|
||||
*dfsp = append(*dfsp, *sfsp...)
|
||||
if *dfsp == nil {
|
||||
*dfsp = []int64{}
|
||||
}
|
||||
}
|
||||
*/
|
||||
sfs := src.getInt32Slice()
|
||||
if sfs != nil {
|
||||
dfs := dst.getInt32Slice()
|
||||
dfs = append(dfs, sfs...)
|
||||
if dfs == nil {
|
||||
dfs = []int32{}
|
||||
}
|
||||
dst.setInt32Slice(dfs)
|
||||
}
|
||||
}
|
||||
case isPointer: // E.g., *int32
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
// NOTE: toInt32Ptr is not defined (see pointer_reflect.go).
|
||||
/*
|
||||
sfpp := src.toInt32Ptr()
|
||||
if *sfpp != nil {
|
||||
dfpp := dst.toInt32Ptr()
|
||||
if *dfpp == nil {
|
||||
*dfpp = Int32(**sfpp)
|
||||
} else {
|
||||
**dfpp = **sfpp
|
||||
}
|
||||
}
|
||||
*/
|
||||
sfp := src.getInt32Ptr()
|
||||
if sfp != nil {
|
||||
dfp := dst.getInt32Ptr()
|
||||
if dfp == nil {
|
||||
dst.setInt32Ptr(*sfp)
|
||||
} else {
|
||||
*dfp = *sfp
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // E.g., int32
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
if v := *src.toInt32(); v != 0 {
|
||||
*dst.toInt32() = v
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Int64:
|
||||
switch {
|
||||
case isSlice: // E.g., []int64
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfsp := src.toInt64Slice()
|
||||
if *sfsp != nil {
|
||||
dfsp := dst.toInt64Slice()
|
||||
*dfsp = append(*dfsp, *sfsp...)
|
||||
if *dfsp == nil {
|
||||
*dfsp = []int64{}
|
||||
}
|
||||
}
|
||||
}
|
||||
case isPointer: // E.g., *int64
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfpp := src.toInt64Ptr()
|
||||
if *sfpp != nil {
|
||||
dfpp := dst.toInt64Ptr()
|
||||
if *dfpp == nil {
|
||||
*dfpp = Int64(**sfpp)
|
||||
} else {
|
||||
**dfpp = **sfpp
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // E.g., int64
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
if v := *src.toInt64(); v != 0 {
|
||||
*dst.toInt64() = v
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Uint32:
|
||||
switch {
|
||||
case isSlice: // E.g., []uint32
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfsp := src.toUint32Slice()
|
||||
if *sfsp != nil {
|
||||
dfsp := dst.toUint32Slice()
|
||||
*dfsp = append(*dfsp, *sfsp...)
|
||||
if *dfsp == nil {
|
||||
*dfsp = []uint32{}
|
||||
}
|
||||
}
|
||||
}
|
||||
case isPointer: // E.g., *uint32
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfpp := src.toUint32Ptr()
|
||||
if *sfpp != nil {
|
||||
dfpp := dst.toUint32Ptr()
|
||||
if *dfpp == nil {
|
||||
*dfpp = Uint32(**sfpp)
|
||||
} else {
|
||||
**dfpp = **sfpp
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // E.g., uint32
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
if v := *src.toUint32(); v != 0 {
|
||||
*dst.toUint32() = v
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Uint64:
|
||||
switch {
|
||||
case isSlice: // E.g., []uint64
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfsp := src.toUint64Slice()
|
||||
if *sfsp != nil {
|
||||
dfsp := dst.toUint64Slice()
|
||||
*dfsp = append(*dfsp, *sfsp...)
|
||||
if *dfsp == nil {
|
||||
*dfsp = []uint64{}
|
||||
}
|
||||
}
|
||||
}
|
||||
case isPointer: // E.g., *uint64
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfpp := src.toUint64Ptr()
|
||||
if *sfpp != nil {
|
||||
dfpp := dst.toUint64Ptr()
|
||||
if *dfpp == nil {
|
||||
*dfpp = Uint64(**sfpp)
|
||||
} else {
|
||||
**dfpp = **sfpp
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // E.g., uint64
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
if v := *src.toUint64(); v != 0 {
|
||||
*dst.toUint64() = v
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Float32:
|
||||
switch {
|
||||
case isSlice: // E.g., []float32
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfsp := src.toFloat32Slice()
|
||||
if *sfsp != nil {
|
||||
dfsp := dst.toFloat32Slice()
|
||||
*dfsp = append(*dfsp, *sfsp...)
|
||||
if *dfsp == nil {
|
||||
*dfsp = []float32{}
|
||||
}
|
||||
}
|
||||
}
|
||||
case isPointer: // E.g., *float32
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfpp := src.toFloat32Ptr()
|
||||
if *sfpp != nil {
|
||||
dfpp := dst.toFloat32Ptr()
|
||||
if *dfpp == nil {
|
||||
*dfpp = Float32(**sfpp)
|
||||
} else {
|
||||
**dfpp = **sfpp
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // E.g., float32
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
if v := *src.toFloat32(); v != 0 {
|
||||
*dst.toFloat32() = v
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Float64:
|
||||
switch {
|
||||
case isSlice: // E.g., []float64
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfsp := src.toFloat64Slice()
|
||||
if *sfsp != nil {
|
||||
dfsp := dst.toFloat64Slice()
|
||||
*dfsp = append(*dfsp, *sfsp...)
|
||||
if *dfsp == nil {
|
||||
*dfsp = []float64{}
|
||||
}
|
||||
}
|
||||
}
|
||||
case isPointer: // E.g., *float64
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfpp := src.toFloat64Ptr()
|
||||
if *sfpp != nil {
|
||||
dfpp := dst.toFloat64Ptr()
|
||||
if *dfpp == nil {
|
||||
*dfpp = Float64(**sfpp)
|
||||
} else {
|
||||
**dfpp = **sfpp
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // E.g., float64
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
if v := *src.toFloat64(); v != 0 {
|
||||
*dst.toFloat64() = v
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Bool:
|
||||
switch {
|
||||
case isSlice: // E.g., []bool
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfsp := src.toBoolSlice()
|
||||
if *sfsp != nil {
|
||||
dfsp := dst.toBoolSlice()
|
||||
*dfsp = append(*dfsp, *sfsp...)
|
||||
if *dfsp == nil {
|
||||
*dfsp = []bool{}
|
||||
}
|
||||
}
|
||||
}
|
||||
case isPointer: // E.g., *bool
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfpp := src.toBoolPtr()
|
||||
if *sfpp != nil {
|
||||
dfpp := dst.toBoolPtr()
|
||||
if *dfpp == nil {
|
||||
*dfpp = Bool(**sfpp)
|
||||
} else {
|
||||
**dfpp = **sfpp
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // E.g., bool
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
if v := *src.toBool(); v {
|
||||
*dst.toBool() = v
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.String:
|
||||
switch {
|
||||
case isSlice: // E.g., []string
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfsp := src.toStringSlice()
|
||||
if *sfsp != nil {
|
||||
dfsp := dst.toStringSlice()
|
||||
*dfsp = append(*dfsp, *sfsp...)
|
||||
if *dfsp == nil {
|
||||
*dfsp = []string{}
|
||||
}
|
||||
}
|
||||
}
|
||||
case isPointer: // E.g., *string
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sfpp := src.toStringPtr()
|
||||
if *sfpp != nil {
|
||||
dfpp := dst.toStringPtr()
|
||||
if *dfpp == nil {
|
||||
*dfpp = String(**sfpp)
|
||||
} else {
|
||||
**dfpp = **sfpp
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // E.g., string
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
if v := *src.toString(); v != "" {
|
||||
*dst.toString() = v
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Slice:
|
||||
isProto3 := props.Prop[i].proto3
|
||||
switch {
|
||||
case isPointer:
|
||||
panic("bad pointer in byte slice case in " + tf.Name())
|
||||
case tf.Elem().Kind() != reflect.Uint8:
|
||||
panic("bad element kind in byte slice case in " + tf.Name())
|
||||
case isSlice: // E.g., [][]byte
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sbsp := src.toBytesSlice()
|
||||
if *sbsp != nil {
|
||||
dbsp := dst.toBytesSlice()
|
||||
for _, sb := range *sbsp {
|
||||
if sb == nil {
|
||||
*dbsp = append(*dbsp, nil)
|
||||
} else {
|
||||
*dbsp = append(*dbsp, append([]byte{}, sb...))
|
||||
}
|
||||
}
|
||||
if *dbsp == nil {
|
||||
*dbsp = [][]byte{}
|
||||
}
|
||||
}
|
||||
}
|
||||
default: // E.g., []byte
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sbp := src.toBytes()
|
||||
if *sbp != nil {
|
||||
dbp := dst.toBytes()
|
||||
if !isProto3 || len(*sbp) > 0 {
|
||||
*dbp = append([]byte{}, *sbp...)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Struct:
|
||||
switch {
|
||||
case !isPointer:
|
||||
panic(fmt.Sprintf("message field %s without pointer", tf))
|
||||
case isSlice: // E.g., []*pb.T
|
||||
mi := getMergeInfo(tf)
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sps := src.getPointerSlice()
|
||||
if sps != nil {
|
||||
dps := dst.getPointerSlice()
|
||||
for _, sp := range sps {
|
||||
var dp pointer
|
||||
if !sp.isNil() {
|
||||
dp = valToPointer(reflect.New(tf))
|
||||
mi.merge(dp, sp)
|
||||
}
|
||||
dps = append(dps, dp)
|
||||
}
|
||||
if dps == nil {
|
||||
dps = []pointer{}
|
||||
}
|
||||
dst.setPointerSlice(dps)
|
||||
}
|
||||
}
|
||||
default: // E.g., *pb.T
|
||||
mi := getMergeInfo(tf)
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sp := src.getPointer()
|
||||
if !sp.isNil() {
|
||||
dp := dst.getPointer()
|
||||
if dp.isNil() {
|
||||
dp = valToPointer(reflect.New(tf))
|
||||
dst.setPointer(dp)
|
||||
}
|
||||
mi.merge(dp, sp)
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Map:
|
||||
switch {
|
||||
case isPointer || isSlice:
|
||||
panic("bad pointer or slice in map case in " + tf.Name())
|
||||
default: // E.g., map[K]V
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
sm := src.asPointerTo(tf).Elem()
|
||||
if sm.Len() == 0 {
|
||||
return
|
||||
}
|
||||
dm := dst.asPointerTo(tf).Elem()
|
||||
if dm.IsNil() {
|
||||
dm.Set(reflect.MakeMap(tf))
|
||||
}
|
||||
|
||||
switch tf.Elem().Kind() {
|
||||
case reflect.Ptr: // Proto struct (e.g., *T)
|
||||
for _, key := range sm.MapKeys() {
|
||||
val := sm.MapIndex(key)
|
||||
val = reflect.ValueOf(Clone(val.Interface().(Message)))
|
||||
dm.SetMapIndex(key, val)
|
||||
}
|
||||
case reflect.Slice: // E.g. Bytes type (e.g., []byte)
|
||||
for _, key := range sm.MapKeys() {
|
||||
val := sm.MapIndex(key)
|
||||
val = reflect.ValueOf(append([]byte{}, val.Bytes()...))
|
||||
dm.SetMapIndex(key, val)
|
||||
}
|
||||
default: // Basic type (e.g., string)
|
||||
for _, key := range sm.MapKeys() {
|
||||
val := sm.MapIndex(key)
|
||||
dm.SetMapIndex(key, val)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
case reflect.Interface:
|
||||
// Must be oneof field.
|
||||
switch {
|
||||
case isPointer || isSlice:
|
||||
panic("bad pointer or slice in interface case in " + tf.Name())
|
||||
default: // E.g., interface{}
|
||||
// TODO: Make this faster?
|
||||
mfi.merge = func(dst, src pointer) {
|
||||
su := src.asPointerTo(tf).Elem()
|
||||
if !su.IsNil() {
|
||||
du := dst.asPointerTo(tf).Elem()
|
||||
typ := su.Elem().Type()
|
||||
if du.IsNil() || du.Elem().Type() != typ {
|
||||
du.Set(reflect.New(typ.Elem())) // Initialize interface if empty
|
||||
}
|
||||
sv := su.Elem().Elem().Field(0)
|
||||
if sv.Kind() == reflect.Ptr && sv.IsNil() {
|
||||
return
|
||||
}
|
||||
dv := du.Elem().Elem().Field(0)
|
||||
if dv.Kind() == reflect.Ptr && dv.IsNil() {
|
||||
dv.Set(reflect.New(sv.Type().Elem())) // Initialize proto message if empty
|
||||
}
|
||||
switch sv.Type().Kind() {
|
||||
case reflect.Ptr: // Proto struct (e.g., *T)
|
||||
Merge(dv.Interface().(Message), sv.Interface().(Message))
|
||||
case reflect.Slice: // E.g. Bytes type (e.g., []byte)
|
||||
dv.Set(reflect.ValueOf(append([]byte{}, sv.Bytes()...)))
|
||||
default: // Basic type (e.g., string)
|
||||
dv.Set(sv)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
default:
|
||||
panic(fmt.Sprintf("merger not found for type:%s", tf))
|
||||
}
|
||||
mi.fields = append(mi.fields, mfi)
|
||||
}
|
||||
|
||||
mi.unrecognized = invalidField
|
||||
if f, ok := t.FieldByName("XXX_unrecognized"); ok {
|
||||
if f.Type != reflect.TypeOf([]byte{}) {
|
||||
panic("expected XXX_unrecognized to be of type []byte")
|
||||
}
|
||||
mi.unrecognized = toField(&f)
|
||||
}
|
||||
|
||||
atomic.StoreInt32(&mi.initialized, 1)
|
||||
}
|
||||
2053
watchdog/vendor/github.com/golang/protobuf/proto/table_unmarshal.go
generated
vendored
2053
watchdog/vendor/github.com/golang/protobuf/proto/table_unmarshal.go
generated
vendored
File diff suppressed because it is too large
Load Diff
843
watchdog/vendor/github.com/golang/protobuf/proto/text.go
generated
vendored
843
watchdog/vendor/github.com/golang/protobuf/proto/text.go
generated
vendored
@ -1,843 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2010 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
package proto
|
||||
|
||||
// Functions for writing the text protocol buffer format.
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"bytes"
|
||||
"encoding"
|
||||
"errors"
|
||||
"fmt"
|
||||
"io"
|
||||
"log"
|
||||
"math"
|
||||
"reflect"
|
||||
"sort"
|
||||
"strings"
|
||||
)
|
||||
|
||||
var (
|
||||
newline = []byte("\n")
|
||||
spaces = []byte(" ")
|
||||
endBraceNewline = []byte("}\n")
|
||||
backslashN = []byte{'\\', 'n'}
|
||||
backslashR = []byte{'\\', 'r'}
|
||||
backslashT = []byte{'\\', 't'}
|
||||
backslashDQ = []byte{'\\', '"'}
|
||||
backslashBS = []byte{'\\', '\\'}
|
||||
posInf = []byte("inf")
|
||||
negInf = []byte("-inf")
|
||||
nan = []byte("nan")
|
||||
)
|
||||
|
||||
type writer interface {
|
||||
io.Writer
|
||||
WriteByte(byte) error
|
||||
}
|
||||
|
||||
// textWriter is an io.Writer that tracks its indentation level.
|
||||
type textWriter struct {
|
||||
ind int
|
||||
complete bool // if the current position is a complete line
|
||||
compact bool // whether to write out as a one-liner
|
||||
w writer
|
||||
}
|
||||
|
||||
func (w *textWriter) WriteString(s string) (n int, err error) {
|
||||
if !strings.Contains(s, "\n") {
|
||||
if !w.compact && w.complete {
|
||||
w.writeIndent()
|
||||
}
|
||||
w.complete = false
|
||||
return io.WriteString(w.w, s)
|
||||
}
|
||||
// WriteString is typically called without newlines, so this
|
||||
// codepath and its copy are rare. We copy to avoid
|
||||
// duplicating all of Write's logic here.
|
||||
return w.Write([]byte(s))
|
||||
}
|
||||
|
||||
func (w *textWriter) Write(p []byte) (n int, err error) {
|
||||
newlines := bytes.Count(p, newline)
|
||||
if newlines == 0 {
|
||||
if !w.compact && w.complete {
|
||||
w.writeIndent()
|
||||
}
|
||||
n, err = w.w.Write(p)
|
||||
w.complete = false
|
||||
return n, err
|
||||
}
|
||||
|
||||
frags := bytes.SplitN(p, newline, newlines+1)
|
||||
if w.compact {
|
||||
for i, frag := range frags {
|
||||
if i > 0 {
|
||||
if err := w.w.WriteByte(' '); err != nil {
|
||||
return n, err
|
||||
}
|
||||
n++
|
||||
}
|
||||
nn, err := w.w.Write(frag)
|
||||
n += nn
|
||||
if err != nil {
|
||||
return n, err
|
||||
}
|
||||
}
|
||||
return n, nil
|
||||
}
|
||||
|
||||
for i, frag := range frags {
|
||||
if w.complete {
|
||||
w.writeIndent()
|
||||
}
|
||||
nn, err := w.w.Write(frag)
|
||||
n += nn
|
||||
if err != nil {
|
||||
return n, err
|
||||
}
|
||||
if i+1 < len(frags) {
|
||||
if err := w.w.WriteByte('\n'); err != nil {
|
||||
return n, err
|
||||
}
|
||||
n++
|
||||
}
|
||||
}
|
||||
w.complete = len(frags[len(frags)-1]) == 0
|
||||
return n, nil
|
||||
}
|
||||
|
||||
func (w *textWriter) WriteByte(c byte) error {
|
||||
if w.compact && c == '\n' {
|
||||
c = ' '
|
||||
}
|
||||
if !w.compact && w.complete {
|
||||
w.writeIndent()
|
||||
}
|
||||
err := w.w.WriteByte(c)
|
||||
w.complete = c == '\n'
|
||||
return err
|
||||
}
|
||||
|
||||
func (w *textWriter) indent() { w.ind++ }
|
||||
|
||||
func (w *textWriter) unindent() {
|
||||
if w.ind == 0 {
|
||||
log.Print("proto: textWriter unindented too far")
|
||||
return
|
||||
}
|
||||
w.ind--
|
||||
}
|
||||
|
||||
func writeName(w *textWriter, props *Properties) error {
|
||||
if _, err := w.WriteString(props.OrigName); err != nil {
|
||||
return err
|
||||
}
|
||||
if props.Wire != "group" {
|
||||
return w.WriteByte(':')
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func requiresQuotes(u string) bool {
|
||||
// When type URL contains any characters except [0-9A-Za-z./\-]*, it must be quoted.
|
||||
for _, ch := range u {
|
||||
switch {
|
||||
case ch == '.' || ch == '/' || ch == '_':
|
||||
continue
|
||||
case '0' <= ch && ch <= '9':
|
||||
continue
|
||||
case 'A' <= ch && ch <= 'Z':
|
||||
continue
|
||||
case 'a' <= ch && ch <= 'z':
|
||||
continue
|
||||
default:
|
||||
return true
|
||||
}
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
// isAny reports whether sv is a google.protobuf.Any message
|
||||
func isAny(sv reflect.Value) bool {
|
||||
type wkt interface {
|
||||
XXX_WellKnownType() string
|
||||
}
|
||||
t, ok := sv.Addr().Interface().(wkt)
|
||||
return ok && t.XXX_WellKnownType() == "Any"
|
||||
}
|
||||
|
||||
// writeProto3Any writes an expanded google.protobuf.Any message.
|
||||
//
|
||||
// It returns (false, nil) if sv value can't be unmarshaled (e.g. because
|
||||
// required messages are not linked in).
|
||||
//
|
||||
// It returns (true, error) when sv was written in expanded format or an error
|
||||
// was encountered.
|
||||
func (tm *TextMarshaler) writeProto3Any(w *textWriter, sv reflect.Value) (bool, error) {
|
||||
turl := sv.FieldByName("TypeUrl")
|
||||
val := sv.FieldByName("Value")
|
||||
if !turl.IsValid() || !val.IsValid() {
|
||||
return true, errors.New("proto: invalid google.protobuf.Any message")
|
||||
}
|
||||
|
||||
b, ok := val.Interface().([]byte)
|
||||
if !ok {
|
||||
return true, errors.New("proto: invalid google.protobuf.Any message")
|
||||
}
|
||||
|
||||
parts := strings.Split(turl.String(), "/")
|
||||
mt := MessageType(parts[len(parts)-1])
|
||||
if mt == nil {
|
||||
return false, nil
|
||||
}
|
||||
m := reflect.New(mt.Elem())
|
||||
if err := Unmarshal(b, m.Interface().(Message)); err != nil {
|
||||
return false, nil
|
||||
}
|
||||
w.Write([]byte("["))
|
||||
u := turl.String()
|
||||
if requiresQuotes(u) {
|
||||
writeString(w, u)
|
||||
} else {
|
||||
w.Write([]byte(u))
|
||||
}
|
||||
if w.compact {
|
||||
w.Write([]byte("]:<"))
|
||||
} else {
|
||||
w.Write([]byte("]: <\n"))
|
||||
w.ind++
|
||||
}
|
||||
if err := tm.writeStruct(w, m.Elem()); err != nil {
|
||||
return true, err
|
||||
}
|
||||
if w.compact {
|
||||
w.Write([]byte("> "))
|
||||
} else {
|
||||
w.ind--
|
||||
w.Write([]byte(">\n"))
|
||||
}
|
||||
return true, nil
|
||||
}
|
||||
|
||||
func (tm *TextMarshaler) writeStruct(w *textWriter, sv reflect.Value) error {
|
||||
if tm.ExpandAny && isAny(sv) {
|
||||
if canExpand, err := tm.writeProto3Any(w, sv); canExpand {
|
||||
return err
|
||||
}
|
||||
}
|
||||
st := sv.Type()
|
||||
sprops := GetProperties(st)
|
||||
for i := 0; i < sv.NumField(); i++ {
|
||||
fv := sv.Field(i)
|
||||
props := sprops.Prop[i]
|
||||
name := st.Field(i).Name
|
||||
|
||||
if name == "XXX_NoUnkeyedLiteral" {
|
||||
continue
|
||||
}
|
||||
|
||||
if strings.HasPrefix(name, "XXX_") {
|
||||
// There are two XXX_ fields:
|
||||
// XXX_unrecognized []byte
|
||||
// XXX_extensions map[int32]proto.Extension
|
||||
// The first is handled here;
|
||||
// the second is handled at the bottom of this function.
|
||||
if name == "XXX_unrecognized" && !fv.IsNil() {
|
||||
if err := writeUnknownStruct(w, fv.Interface().([]byte)); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
continue
|
||||
}
|
||||
if fv.Kind() == reflect.Ptr && fv.IsNil() {
|
||||
// Field not filled in. This could be an optional field or
|
||||
// a required field that wasn't filled in. Either way, there
|
||||
// isn't anything we can show for it.
|
||||
continue
|
||||
}
|
||||
if fv.Kind() == reflect.Slice && fv.IsNil() {
|
||||
// Repeated field that is empty, or a bytes field that is unused.
|
||||
continue
|
||||
}
|
||||
|
||||
if props.Repeated && fv.Kind() == reflect.Slice {
|
||||
// Repeated field.
|
||||
for j := 0; j < fv.Len(); j++ {
|
||||
if err := writeName(w, props); err != nil {
|
||||
return err
|
||||
}
|
||||
if !w.compact {
|
||||
if err := w.WriteByte(' '); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
v := fv.Index(j)
|
||||
if v.Kind() == reflect.Ptr && v.IsNil() {
|
||||
// A nil message in a repeated field is not valid,
|
||||
// but we can handle that more gracefully than panicking.
|
||||
if _, err := w.Write([]byte("<nil>\n")); err != nil {
|
||||
return err
|
||||
}
|
||||
continue
|
||||
}
|
||||
if err := tm.writeAny(w, v, props); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := w.WriteByte('\n'); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
continue
|
||||
}
|
||||
if fv.Kind() == reflect.Map {
|
||||
// Map fields are rendered as a repeated struct with key/value fields.
|
||||
keys := fv.MapKeys()
|
||||
sort.Sort(mapKeys(keys))
|
||||
for _, key := range keys {
|
||||
val := fv.MapIndex(key)
|
||||
if err := writeName(w, props); err != nil {
|
||||
return err
|
||||
}
|
||||
if !w.compact {
|
||||
if err := w.WriteByte(' '); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
// open struct
|
||||
if err := w.WriteByte('<'); err != nil {
|
||||
return err
|
||||
}
|
||||
if !w.compact {
|
||||
if err := w.WriteByte('\n'); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
w.indent()
|
||||
// key
|
||||
if _, err := w.WriteString("key:"); err != nil {
|
||||
return err
|
||||
}
|
||||
if !w.compact {
|
||||
if err := w.WriteByte(' '); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
if err := tm.writeAny(w, key, props.MapKeyProp); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := w.WriteByte('\n'); err != nil {
|
||||
return err
|
||||
}
|
||||
// nil values aren't legal, but we can avoid panicking because of them.
|
||||
if val.Kind() != reflect.Ptr || !val.IsNil() {
|
||||
// value
|
||||
if _, err := w.WriteString("value:"); err != nil {
|
||||
return err
|
||||
}
|
||||
if !w.compact {
|
||||
if err := w.WriteByte(' '); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
if err := tm.writeAny(w, val, props.MapValProp); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := w.WriteByte('\n'); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
// close struct
|
||||
w.unindent()
|
||||
if err := w.WriteByte('>'); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := w.WriteByte('\n'); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
continue
|
||||
}
|
||||
if props.proto3 && fv.Kind() == reflect.Slice && fv.Len() == 0 {
|
||||
// empty bytes field
|
||||
continue
|
||||
}
|
||||
if fv.Kind() != reflect.Ptr && fv.Kind() != reflect.Slice {
|
||||
// proto3 non-repeated scalar field; skip if zero value
|
||||
if isProto3Zero(fv) {
|
||||
continue
|
||||
}
|
||||
}
|
||||
|
||||
if fv.Kind() == reflect.Interface {
|
||||
// Check if it is a oneof.
|
||||
if st.Field(i).Tag.Get("protobuf_oneof") != "" {
|
||||
// fv is nil, or holds a pointer to generated struct.
|
||||
// That generated struct has exactly one field,
|
||||
// which has a protobuf struct tag.
|
||||
if fv.IsNil() {
|
||||
continue
|
||||
}
|
||||
inner := fv.Elem().Elem() // interface -> *T -> T
|
||||
tag := inner.Type().Field(0).Tag.Get("protobuf")
|
||||
props = new(Properties) // Overwrite the outer props var, but not its pointee.
|
||||
props.Parse(tag)
|
||||
// Write the value in the oneof, not the oneof itself.
|
||||
fv = inner.Field(0)
|
||||
|
||||
// Special case to cope with malformed messages gracefully:
|
||||
// If the value in the oneof is a nil pointer, don't panic
|
||||
// in writeAny.
|
||||
if fv.Kind() == reflect.Ptr && fv.IsNil() {
|
||||
// Use errors.New so writeAny won't render quotes.
|
||||
msg := errors.New("/* nil */")
|
||||
fv = reflect.ValueOf(&msg).Elem()
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if err := writeName(w, props); err != nil {
|
||||
return err
|
||||
}
|
||||
if !w.compact {
|
||||
if err := w.WriteByte(' '); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
|
||||
// Enums have a String method, so writeAny will work fine.
|
||||
if err := tm.writeAny(w, fv, props); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
if err := w.WriteByte('\n'); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
|
||||
// Extensions (the XXX_extensions field).
|
||||
pv := sv.Addr()
|
||||
if _, err := extendable(pv.Interface()); err == nil {
|
||||
if err := tm.writeExtensions(w, pv); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
// writeAny writes an arbitrary field.
|
||||
func (tm *TextMarshaler) writeAny(w *textWriter, v reflect.Value, props *Properties) error {
|
||||
v = reflect.Indirect(v)
|
||||
|
||||
// Floats have special cases.
|
||||
if v.Kind() == reflect.Float32 || v.Kind() == reflect.Float64 {
|
||||
x := v.Float()
|
||||
var b []byte
|
||||
switch {
|
||||
case math.IsInf(x, 1):
|
||||
b = posInf
|
||||
case math.IsInf(x, -1):
|
||||
b = negInf
|
||||
case math.IsNaN(x):
|
||||
b = nan
|
||||
}
|
||||
if b != nil {
|
||||
_, err := w.Write(b)
|
||||
return err
|
||||
}
|
||||
// Other values are handled below.
|
||||
}
|
||||
|
||||
// We don't attempt to serialise every possible value type; only those
|
||||
// that can occur in protocol buffers.
|
||||
switch v.Kind() {
|
||||
case reflect.Slice:
|
||||
// Should only be a []byte; repeated fields are handled in writeStruct.
|
||||
if err := writeString(w, string(v.Bytes())); err != nil {
|
||||
return err
|
||||
}
|
||||
case reflect.String:
|
||||
if err := writeString(w, v.String()); err != nil {
|
||||
return err
|
||||
}
|
||||
case reflect.Struct:
|
||||
// Required/optional group/message.
|
||||
var bra, ket byte = '<', '>'
|
||||
if props != nil && props.Wire == "group" {
|
||||
bra, ket = '{', '}'
|
||||
}
|
||||
if err := w.WriteByte(bra); err != nil {
|
||||
return err
|
||||
}
|
||||
if !w.compact {
|
||||
if err := w.WriteByte('\n'); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
w.indent()
|
||||
if v.CanAddr() {
|
||||
// Calling v.Interface on a struct causes the reflect package to
|
||||
// copy the entire struct. This is racy with the new Marshaler
|
||||
// since we atomically update the XXX_sizecache.
|
||||
//
|
||||
// Thus, we retrieve a pointer to the struct if possible to avoid
|
||||
// a race since v.Interface on the pointer doesn't copy the struct.
|
||||
//
|
||||
// If v is not addressable, then we are not worried about a race
|
||||
// since it implies that the binary Marshaler cannot possibly be
|
||||
// mutating this value.
|
||||
v = v.Addr()
|
||||
}
|
||||
if etm, ok := v.Interface().(encoding.TextMarshaler); ok {
|
||||
text, err := etm.MarshalText()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if _, err = w.Write(text); err != nil {
|
||||
return err
|
||||
}
|
||||
} else {
|
||||
if v.Kind() == reflect.Ptr {
|
||||
v = v.Elem()
|
||||
}
|
||||
if err := tm.writeStruct(w, v); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
w.unindent()
|
||||
if err := w.WriteByte(ket); err != nil {
|
||||
return err
|
||||
}
|
||||
default:
|
||||
_, err := fmt.Fprint(w, v.Interface())
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// equivalent to C's isprint.
|
||||
func isprint(c byte) bool {
|
||||
return c >= 0x20 && c < 0x7f
|
||||
}
|
||||
|
||||
// writeString writes a string in the protocol buffer text format.
|
||||
// It is similar to strconv.Quote except we don't use Go escape sequences,
|
||||
// we treat the string as a byte sequence, and we use octal escapes.
|
||||
// These differences are to maintain interoperability with the other
|
||||
// languages' implementations of the text format.
|
||||
func writeString(w *textWriter, s string) error {
|
||||
// use WriteByte here to get any needed indent
|
||||
if err := w.WriteByte('"'); err != nil {
|
||||
return err
|
||||
}
|
||||
// Loop over the bytes, not the runes.
|
||||
for i := 0; i < len(s); i++ {
|
||||
var err error
|
||||
// Divergence from C++: we don't escape apostrophes.
|
||||
// There's no need to escape them, and the C++ parser
|
||||
// copes with a naked apostrophe.
|
||||
switch c := s[i]; c {
|
||||
case '\n':
|
||||
_, err = w.w.Write(backslashN)
|
||||
case '\r':
|
||||
_, err = w.w.Write(backslashR)
|
||||
case '\t':
|
||||
_, err = w.w.Write(backslashT)
|
||||
case '"':
|
||||
_, err = w.w.Write(backslashDQ)
|
||||
case '\\':
|
||||
_, err = w.w.Write(backslashBS)
|
||||
default:
|
||||
if isprint(c) {
|
||||
err = w.w.WriteByte(c)
|
||||
} else {
|
||||
_, err = fmt.Fprintf(w.w, "\\%03o", c)
|
||||
}
|
||||
}
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
return w.WriteByte('"')
|
||||
}
|
||||
|
||||
func writeUnknownStruct(w *textWriter, data []byte) (err error) {
|
||||
if !w.compact {
|
||||
if _, err := fmt.Fprintf(w, "/* %d unknown bytes */\n", len(data)); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
b := NewBuffer(data)
|
||||
for b.index < len(b.buf) {
|
||||
x, err := b.DecodeVarint()
|
||||
if err != nil {
|
||||
_, err := fmt.Fprintf(w, "/* %v */\n", err)
|
||||
return err
|
||||
}
|
||||
wire, tag := x&7, x>>3
|
||||
if wire == WireEndGroup {
|
||||
w.unindent()
|
||||
if _, err := w.Write(endBraceNewline); err != nil {
|
||||
return err
|
||||
}
|
||||
continue
|
||||
}
|
||||
if _, err := fmt.Fprint(w, tag); err != nil {
|
||||
return err
|
||||
}
|
||||
if wire != WireStartGroup {
|
||||
if err := w.WriteByte(':'); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
if !w.compact || wire == WireStartGroup {
|
||||
if err := w.WriteByte(' '); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
switch wire {
|
||||
case WireBytes:
|
||||
buf, e := b.DecodeRawBytes(false)
|
||||
if e == nil {
|
||||
_, err = fmt.Fprintf(w, "%q", buf)
|
||||
} else {
|
||||
_, err = fmt.Fprintf(w, "/* %v */", e)
|
||||
}
|
||||
case WireFixed32:
|
||||
x, err = b.DecodeFixed32()
|
||||
err = writeUnknownInt(w, x, err)
|
||||
case WireFixed64:
|
||||
x, err = b.DecodeFixed64()
|
||||
err = writeUnknownInt(w, x, err)
|
||||
case WireStartGroup:
|
||||
err = w.WriteByte('{')
|
||||
w.indent()
|
||||
case WireVarint:
|
||||
x, err = b.DecodeVarint()
|
||||
err = writeUnknownInt(w, x, err)
|
||||
default:
|
||||
_, err = fmt.Fprintf(w, "/* unknown wire type %d */", wire)
|
||||
}
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if err = w.WriteByte('\n'); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func writeUnknownInt(w *textWriter, x uint64, err error) error {
|
||||
if err == nil {
|
||||
_, err = fmt.Fprint(w, x)
|
||||
} else {
|
||||
_, err = fmt.Fprintf(w, "/* %v */", err)
|
||||
}
|
||||
return err
|
||||
}
|
||||
|
||||
type int32Slice []int32
|
||||
|
||||
func (s int32Slice) Len() int { return len(s) }
|
||||
func (s int32Slice) Less(i, j int) bool { return s[i] < s[j] }
|
||||
func (s int32Slice) Swap(i, j int) { s[i], s[j] = s[j], s[i] }
|
||||
|
||||
// writeExtensions writes all the extensions in pv.
|
||||
// pv is assumed to be a pointer to a protocol message struct that is extendable.
|
||||
func (tm *TextMarshaler) writeExtensions(w *textWriter, pv reflect.Value) error {
|
||||
emap := extensionMaps[pv.Type().Elem()]
|
||||
ep, _ := extendable(pv.Interface())
|
||||
|
||||
// Order the extensions by ID.
|
||||
// This isn't strictly necessary, but it will give us
|
||||
// canonical output, which will also make testing easier.
|
||||
m, mu := ep.extensionsRead()
|
||||
if m == nil {
|
||||
return nil
|
||||
}
|
||||
mu.Lock()
|
||||
ids := make([]int32, 0, len(m))
|
||||
for id := range m {
|
||||
ids = append(ids, id)
|
||||
}
|
||||
sort.Sort(int32Slice(ids))
|
||||
mu.Unlock()
|
||||
|
||||
for _, extNum := range ids {
|
||||
ext := m[extNum]
|
||||
var desc *ExtensionDesc
|
||||
if emap != nil {
|
||||
desc = emap[extNum]
|
||||
}
|
||||
if desc == nil {
|
||||
// Unknown extension.
|
||||
if err := writeUnknownStruct(w, ext.enc); err != nil {
|
||||
return err
|
||||
}
|
||||
continue
|
||||
}
|
||||
|
||||
pb, err := GetExtension(ep, desc)
|
||||
if err != nil {
|
||||
return fmt.Errorf("failed getting extension: %v", err)
|
||||
}
|
||||
|
||||
// Repeated extensions will appear as a slice.
|
||||
if !desc.repeated() {
|
||||
if err := tm.writeExtension(w, desc.Name, pb); err != nil {
|
||||
return err
|
||||
}
|
||||
} else {
|
||||
v := reflect.ValueOf(pb)
|
||||
for i := 0; i < v.Len(); i++ {
|
||||
if err := tm.writeExtension(w, desc.Name, v.Index(i).Interface()); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (tm *TextMarshaler) writeExtension(w *textWriter, name string, pb interface{}) error {
|
||||
if _, err := fmt.Fprintf(w, "[%s]:", name); err != nil {
|
||||
return err
|
||||
}
|
||||
if !w.compact {
|
||||
if err := w.WriteByte(' '); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
if err := tm.writeAny(w, reflect.ValueOf(pb), nil); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := w.WriteByte('\n'); err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (w *textWriter) writeIndent() {
|
||||
if !w.complete {
|
||||
return
|
||||
}
|
||||
remain := w.ind * 2
|
||||
for remain > 0 {
|
||||
n := remain
|
||||
if n > len(spaces) {
|
||||
n = len(spaces)
|
||||
}
|
||||
w.w.Write(spaces[:n])
|
||||
remain -= n
|
||||
}
|
||||
w.complete = false
|
||||
}
|
||||
|
||||
// TextMarshaler is a configurable text format marshaler.
|
||||
type TextMarshaler struct {
|
||||
Compact bool // use compact text format (one line).
|
||||
ExpandAny bool // expand google.protobuf.Any messages of known types
|
||||
}
|
||||
|
||||
// Marshal writes a given protocol buffer in text format.
|
||||
// The only errors returned are from w.
|
||||
func (tm *TextMarshaler) Marshal(w io.Writer, pb Message) error {
|
||||
val := reflect.ValueOf(pb)
|
||||
if pb == nil || val.IsNil() {
|
||||
w.Write([]byte("<nil>"))
|
||||
return nil
|
||||
}
|
||||
var bw *bufio.Writer
|
||||
ww, ok := w.(writer)
|
||||
if !ok {
|
||||
bw = bufio.NewWriter(w)
|
||||
ww = bw
|
||||
}
|
||||
aw := &textWriter{
|
||||
w: ww,
|
||||
complete: true,
|
||||
compact: tm.Compact,
|
||||
}
|
||||
|
||||
if etm, ok := pb.(encoding.TextMarshaler); ok {
|
||||
text, err := etm.MarshalText()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if _, err = aw.Write(text); err != nil {
|
||||
return err
|
||||
}
|
||||
if bw != nil {
|
||||
return bw.Flush()
|
||||
}
|
||||
return nil
|
||||
}
|
||||
// Dereference the received pointer so we don't have outer < and >.
|
||||
v := reflect.Indirect(val)
|
||||
if err := tm.writeStruct(aw, v); err != nil {
|
||||
return err
|
||||
}
|
||||
if bw != nil {
|
||||
return bw.Flush()
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// Text is the same as Marshal, but returns the string directly.
|
||||
func (tm *TextMarshaler) Text(pb Message) string {
|
||||
var buf bytes.Buffer
|
||||
tm.Marshal(&buf, pb)
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
var (
|
||||
defaultTextMarshaler = TextMarshaler{}
|
||||
compactTextMarshaler = TextMarshaler{Compact: true}
|
||||
)
|
||||
|
||||
// TODO: consider removing some of the Marshal functions below.
|
||||
|
||||
// MarshalText writes a given protocol buffer in text format.
|
||||
// The only errors returned are from w.
|
||||
func MarshalText(w io.Writer, pb Message) error { return defaultTextMarshaler.Marshal(w, pb) }
|
||||
|
||||
// MarshalTextString is the same as MarshalText, but returns the string directly.
|
||||
func MarshalTextString(pb Message) string { return defaultTextMarshaler.Text(pb) }
|
||||
|
||||
// CompactText writes a given protocol buffer in compact text format (one line).
|
||||
func CompactText(w io.Writer, pb Message) error { return compactTextMarshaler.Marshal(w, pb) }
|
||||
|
||||
// CompactTextString is the same as CompactText, but returns the string directly.
|
||||
func CompactTextString(pb Message) string { return compactTextMarshaler.Text(pb) }
|
||||
880
watchdog/vendor/github.com/golang/protobuf/proto/text_parser.go
generated
vendored
880
watchdog/vendor/github.com/golang/protobuf/proto/text_parser.go
generated
vendored
@ -1,880 +0,0 @@
|
||||
// Go support for Protocol Buffers - Google's data interchange format
|
||||
//
|
||||
// Copyright 2010 The Go Authors. All rights reserved.
|
||||
// https://github.com/golang/protobuf
|
||||
//
|
||||
// Redistribution and use in source and binary forms, with or without
|
||||
// modification, are permitted provided that the following conditions are
|
||||
// met:
|
||||
//
|
||||
// * Redistributions of source code must retain the above copyright
|
||||
// notice, this list of conditions and the following disclaimer.
|
||||
// * Redistributions in binary form must reproduce the above
|
||||
// copyright notice, this list of conditions and the following disclaimer
|
||||
// in the documentation and/or other materials provided with the
|
||||
// distribution.
|
||||
// * Neither the name of Google Inc. nor the names of its
|
||||
// contributors may be used to endorse or promote products derived from
|
||||
// this software without specific prior written permission.
|
||||
//
|
||||
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
package proto
|
||||
|
||||
// Functions for parsing the Text protocol buffer format.
|
||||
// TODO: message sets.
|
||||
|
||||
import (
|
||||
"encoding"
|
||||
"errors"
|
||||
"fmt"
|
||||
"reflect"
|
||||
"strconv"
|
||||
"strings"
|
||||
"unicode/utf8"
|
||||
)
|
||||
|
||||
// Error string emitted when deserializing Any and fields are already set
|
||||
const anyRepeatedlyUnpacked = "Any message unpacked multiple times, or %q already set"
|
||||
|
||||
type ParseError struct {
|
||||
Message string
|
||||
Line int // 1-based line number
|
||||
Offset int // 0-based byte offset from start of input
|
||||
}
|
||||
|
||||
func (p *ParseError) Error() string {
|
||||
if p.Line == 1 {
|
||||
// show offset only for first line
|
||||
return fmt.Sprintf("line 1.%d: %v", p.Offset, p.Message)
|
||||
}
|
||||
return fmt.Sprintf("line %d: %v", p.Line, p.Message)
|
||||
}
|
||||
|
||||
type token struct {
|
||||
value string
|
||||
err *ParseError
|
||||
line int // line number
|
||||
offset int // byte number from start of input, not start of line
|
||||
unquoted string // the unquoted version of value, if it was a quoted string
|
||||
}
|
||||
|
||||
func (t *token) String() string {
|
||||
if t.err == nil {
|
||||
return fmt.Sprintf("%q (line=%d, offset=%d)", t.value, t.line, t.offset)
|
||||
}
|
||||
return fmt.Sprintf("parse error: %v", t.err)
|
||||
}
|
||||
|
||||
type textParser struct {
|
||||
s string // remaining input
|
||||
done bool // whether the parsing is finished (success or error)
|
||||
backed bool // whether back() was called
|
||||
offset, line int
|
||||
cur token
|
||||
}
|
||||
|
||||
func newTextParser(s string) *textParser {
|
||||
p := new(textParser)
|
||||
p.s = s
|
||||
p.line = 1
|
||||
p.cur.line = 1
|
||||
return p
|
||||
}
|
||||
|
||||
func (p *textParser) errorf(format string, a ...interface{}) *ParseError {
|
||||
pe := &ParseError{fmt.Sprintf(format, a...), p.cur.line, p.cur.offset}
|
||||
p.cur.err = pe
|
||||
p.done = true
|
||||
return pe
|
||||
}
|
||||
|
||||
// Numbers and identifiers are matched by [-+._A-Za-z0-9]
|
||||
func isIdentOrNumberChar(c byte) bool {
|
||||
switch {
|
||||
case 'A' <= c && c <= 'Z', 'a' <= c && c <= 'z':
|
||||
return true
|
||||
case '0' <= c && c <= '9':
|
||||
return true
|
||||
}
|
||||
switch c {
|
||||
case '-', '+', '.', '_':
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func isWhitespace(c byte) bool {
|
||||
switch c {
|
||||
case ' ', '\t', '\n', '\r':
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func isQuote(c byte) bool {
|
||||
switch c {
|
||||
case '"', '\'':
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func (p *textParser) skipWhitespace() {
|
||||
i := 0
|
||||
for i < len(p.s) && (isWhitespace(p.s[i]) || p.s[i] == '#') {
|
||||
if p.s[i] == '#' {
|
||||
// comment; skip to end of line or input
|
||||
for i < len(p.s) && p.s[i] != '\n' {
|
||||
i++
|
||||
}
|
||||
if i == len(p.s) {
|
||||
break
|
||||
}
|
||||
}
|
||||
if p.s[i] == '\n' {
|
||||
p.line++
|
||||
}
|
||||
i++
|
||||
}
|
||||
p.offset += i
|
||||
p.s = p.s[i:len(p.s)]
|
||||
if len(p.s) == 0 {
|
||||
p.done = true
|
||||
}
|
||||
}
|
||||
|
||||
func (p *textParser) advance() {
|
||||
// Skip whitespace
|
||||
p.skipWhitespace()
|
||||
if p.done {
|
||||
return
|
||||
}
|
||||
|
||||
// Start of non-whitespace
|
||||
p.cur.err = nil
|
||||
p.cur.offset, p.cur.line = p.offset, p.line
|
||||
p.cur.unquoted = ""
|
||||
switch p.s[0] {
|
||||
case '<', '>', '{', '}', ':', '[', ']', ';', ',', '/':
|
||||
// Single symbol
|
||||
p.cur.value, p.s = p.s[0:1], p.s[1:len(p.s)]
|
||||
case '"', '\'':
|
||||
// Quoted string
|
||||
i := 1
|
||||
for i < len(p.s) && p.s[i] != p.s[0] && p.s[i] != '\n' {
|
||||
if p.s[i] == '\\' && i+1 < len(p.s) {
|
||||
// skip escaped char
|
||||
i++
|
||||
}
|
||||
i++
|
||||
}
|
||||
if i >= len(p.s) || p.s[i] != p.s[0] {
|
||||
p.errorf("unmatched quote")
|
||||
return
|
||||
}
|
||||
unq, err := unquoteC(p.s[1:i], rune(p.s[0]))
|
||||
if err != nil {
|
||||
p.errorf("invalid quoted string %s: %v", p.s[0:i+1], err)
|
||||
return
|
||||
}
|
||||
p.cur.value, p.s = p.s[0:i+1], p.s[i+1:len(p.s)]
|
||||
p.cur.unquoted = unq
|
||||
default:
|
||||
i := 0
|
||||
for i < len(p.s) && isIdentOrNumberChar(p.s[i]) {
|
||||
i++
|
||||
}
|
||||
if i == 0 {
|
||||
p.errorf("unexpected byte %#x", p.s[0])
|
||||
return
|
||||
}
|
||||
p.cur.value, p.s = p.s[0:i], p.s[i:len(p.s)]
|
||||
}
|
||||
p.offset += len(p.cur.value)
|
||||
}
|
||||
|
||||
var (
|
||||
errBadUTF8 = errors.New("proto: bad UTF-8")
|
||||
)
|
||||
|
||||
func unquoteC(s string, quote rune) (string, error) {
|
||||
// This is based on C++'s tokenizer.cc.
|
||||
// Despite its name, this is *not* parsing C syntax.
|
||||
// For instance, "\0" is an invalid quoted string.
|
||||
|
||||
// Avoid allocation in trivial cases.
|
||||
simple := true
|
||||
for _, r := range s {
|
||||
if r == '\\' || r == quote {
|
||||
simple = false
|
||||
break
|
||||
}
|
||||
}
|
||||
if simple {
|
||||
return s, nil
|
||||
}
|
||||
|
||||
buf := make([]byte, 0, 3*len(s)/2)
|
||||
for len(s) > 0 {
|
||||
r, n := utf8.DecodeRuneInString(s)
|
||||
if r == utf8.RuneError && n == 1 {
|
||||
return "", errBadUTF8
|
||||
}
|
||||
s = s[n:]
|
||||
if r != '\\' {
|
||||
if r < utf8.RuneSelf {
|
||||
buf = append(buf, byte(r))
|
||||
} else {
|
||||
buf = append(buf, string(r)...)
|
||||
}
|
||||
continue
|
||||
}
|
||||
|
||||
ch, tail, err := unescape(s)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
buf = append(buf, ch...)
|
||||
s = tail
|
||||
}
|
||||
return string(buf), nil
|
||||
}
|
||||
|
||||
func unescape(s string) (ch string, tail string, err error) {
|
||||
r, n := utf8.DecodeRuneInString(s)
|
||||
if r == utf8.RuneError && n == 1 {
|
||||
return "", "", errBadUTF8
|
||||
}
|
||||
s = s[n:]
|
||||
switch r {
|
||||
case 'a':
|
||||
return "\a", s, nil
|
||||
case 'b':
|
||||
return "\b", s, nil
|
||||
case 'f':
|
||||
return "\f", s, nil
|
||||
case 'n':
|
||||
return "\n", s, nil
|
||||
case 'r':
|
||||
return "\r", s, nil
|
||||
case 't':
|
||||
return "\t", s, nil
|
||||
case 'v':
|
||||
return "\v", s, nil
|
||||
case '?':
|
||||
return "?", s, nil // trigraph workaround
|
||||
case '\'', '"', '\\':
|
||||
return string(r), s, nil
|
||||
case '0', '1', '2', '3', '4', '5', '6', '7':
|
||||
if len(s) < 2 {
|
||||
return "", "", fmt.Errorf(`\%c requires 2 following digits`, r)
|
||||
}
|
||||
ss := string(r) + s[:2]
|
||||
s = s[2:]
|
||||
i, err := strconv.ParseUint(ss, 8, 8)
|
||||
if err != nil {
|
||||
return "", "", fmt.Errorf(`\%s contains non-octal digits`, ss)
|
||||
}
|
||||
return string([]byte{byte(i)}), s, nil
|
||||
case 'x', 'X', 'u', 'U':
|
||||
var n int
|
||||
switch r {
|
||||
case 'x', 'X':
|
||||
n = 2
|
||||
case 'u':
|
||||
n = 4
|
||||
case 'U':
|
||||
n = 8
|
||||
}
|
||||
if len(s) < n {
|
||||
return "", "", fmt.Errorf(`\%c requires %d following digits`, r, n)
|
||||
}
|
||||
ss := s[:n]
|
||||
s = s[n:]
|
||||
i, err := strconv.ParseUint(ss, 16, 64)
|
||||
if err != nil {
|
||||
return "", "", fmt.Errorf(`\%c%s contains non-hexadecimal digits`, r, ss)
|
||||
}
|
||||
if r == 'x' || r == 'X' {
|
||||
return string([]byte{byte(i)}), s, nil
|
||||
}
|
||||
if i > utf8.MaxRune {
|
||||
return "", "", fmt.Errorf(`\%c%s is not a valid Unicode code point`, r, ss)
|
||||
}
|
||||
return string(i), s, nil
|
||||
}
|
||||
return "", "", fmt.Errorf(`unknown escape \%c`, r)
|
||||
}
|
||||
|
||||
// Back off the parser by one token. Can only be done between calls to next().
|
||||
// It makes the next advance() a no-op.
|
||||
func (p *textParser) back() { p.backed = true }
|
||||
|
||||
// Advances the parser and returns the new current token.
|
||||
func (p *textParser) next() *token {
|
||||
if p.backed || p.done {
|
||||
p.backed = false
|
||||
return &p.cur
|
||||
}
|
||||
p.advance()
|
||||
if p.done {
|
||||
p.cur.value = ""
|
||||
} else if len(p.cur.value) > 0 && isQuote(p.cur.value[0]) {
|
||||
// Look for multiple quoted strings separated by whitespace,
|
||||
// and concatenate them.
|
||||
cat := p.cur
|
||||
for {
|
||||
p.skipWhitespace()
|
||||
if p.done || !isQuote(p.s[0]) {
|
||||
break
|
||||
}
|
||||
p.advance()
|
||||
if p.cur.err != nil {
|
||||
return &p.cur
|
||||
}
|
||||
cat.value += " " + p.cur.value
|
||||
cat.unquoted += p.cur.unquoted
|
||||
}
|
||||
p.done = false // parser may have seen EOF, but we want to return cat
|
||||
p.cur = cat
|
||||
}
|
||||
return &p.cur
|
||||
}
|
||||
|
||||
func (p *textParser) consumeToken(s string) error {
|
||||
tok := p.next()
|
||||
if tok.err != nil {
|
||||
return tok.err
|
||||
}
|
||||
if tok.value != s {
|
||||
p.back()
|
||||
return p.errorf("expected %q, found %q", s, tok.value)
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// Return a RequiredNotSetError indicating which required field was not set.
|
||||
func (p *textParser) missingRequiredFieldError(sv reflect.Value) *RequiredNotSetError {
|
||||
st := sv.Type()
|
||||
sprops := GetProperties(st)
|
||||
for i := 0; i < st.NumField(); i++ {
|
||||
if !isNil(sv.Field(i)) {
|
||||
continue
|
||||
}
|
||||
|
||||
props := sprops.Prop[i]
|
||||
if props.Required {
|
||||
return &RequiredNotSetError{fmt.Sprintf("%v.%v", st, props.OrigName)}
|
||||
}
|
||||
}
|
||||
return &RequiredNotSetError{fmt.Sprintf("%v.<unknown field name>", st)} // should not happen
|
||||
}
|
||||
|
||||
// Returns the index in the struct for the named field, as well as the parsed tag properties.
|
||||
func structFieldByName(sprops *StructProperties, name string) (int, *Properties, bool) {
|
||||
i, ok := sprops.decoderOrigNames[name]
|
||||
if ok {
|
||||
return i, sprops.Prop[i], true
|
||||
}
|
||||
return -1, nil, false
|
||||
}
|
||||
|
||||
// Consume a ':' from the input stream (if the next token is a colon),
|
||||
// returning an error if a colon is needed but not present.
|
||||
func (p *textParser) checkForColon(props *Properties, typ reflect.Type) *ParseError {
|
||||
tok := p.next()
|
||||
if tok.err != nil {
|
||||
return tok.err
|
||||
}
|
||||
if tok.value != ":" {
|
||||
// Colon is optional when the field is a group or message.
|
||||
needColon := true
|
||||
switch props.Wire {
|
||||
case "group":
|
||||
needColon = false
|
||||
case "bytes":
|
||||
// A "bytes" field is either a message, a string, or a repeated field;
|
||||
// those three become *T, *string and []T respectively, so we can check for
|
||||
// this field being a pointer to a non-string.
|
||||
if typ.Kind() == reflect.Ptr {
|
||||
// *T or *string
|
||||
if typ.Elem().Kind() == reflect.String {
|
||||
break
|
||||
}
|
||||
} else if typ.Kind() == reflect.Slice {
|
||||
// []T or []*T
|
||||
if typ.Elem().Kind() != reflect.Ptr {
|
||||
break
|
||||
}
|
||||
} else if typ.Kind() == reflect.String {
|
||||
// The proto3 exception is for a string field,
|
||||
// which requires a colon.
|
||||
break
|
||||
}
|
||||
needColon = false
|
||||
}
|
||||
if needColon {
|
||||
return p.errorf("expected ':', found %q", tok.value)
|
||||
}
|
||||
p.back()
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *textParser) readStruct(sv reflect.Value, terminator string) error {
|
||||
st := sv.Type()
|
||||
sprops := GetProperties(st)
|
||||
reqCount := sprops.reqCount
|
||||
var reqFieldErr error
|
||||
fieldSet := make(map[string]bool)
|
||||
// A struct is a sequence of "name: value", terminated by one of
|
||||
// '>' or '}', or the end of the input. A name may also be
|
||||
// "[extension]" or "[type/url]".
|
||||
//
|
||||
// The whole struct can also be an expanded Any message, like:
|
||||
// [type/url] < ... struct contents ... >
|
||||
for {
|
||||
tok := p.next()
|
||||
if tok.err != nil {
|
||||
return tok.err
|
||||
}
|
||||
if tok.value == terminator {
|
||||
break
|
||||
}
|
||||
if tok.value == "[" {
|
||||
// Looks like an extension or an Any.
|
||||
//
|
||||
// TODO: Check whether we need to handle
|
||||
// namespace rooted names (e.g. ".something.Foo").
|
||||
extName, err := p.consumeExtName()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
if s := strings.LastIndex(extName, "/"); s >= 0 {
|
||||
// If it contains a slash, it's an Any type URL.
|
||||
messageName := extName[s+1:]
|
||||
mt := MessageType(messageName)
|
||||
if mt == nil {
|
||||
return p.errorf("unrecognized message %q in google.protobuf.Any", messageName)
|
||||
}
|
||||
tok = p.next()
|
||||
if tok.err != nil {
|
||||
return tok.err
|
||||
}
|
||||
// consume an optional colon
|
||||
if tok.value == ":" {
|
||||
tok = p.next()
|
||||
if tok.err != nil {
|
||||
return tok.err
|
||||
}
|
||||
}
|
||||
var terminator string
|
||||
switch tok.value {
|
||||
case "<":
|
||||
terminator = ">"
|
||||
case "{":
|
||||
terminator = "}"
|
||||
default:
|
||||
return p.errorf("expected '{' or '<', found %q", tok.value)
|
||||
}
|
||||
v := reflect.New(mt.Elem())
|
||||
if pe := p.readStruct(v.Elem(), terminator); pe != nil {
|
||||
return pe
|
||||
}
|
||||
b, err := Marshal(v.Interface().(Message))
|
||||
if err != nil {
|
||||
return p.errorf("failed to marshal message of type %q: %v", messageName, err)
|
||||
}
|
||||
if fieldSet["type_url"] {
|
||||
return p.errorf(anyRepeatedlyUnpacked, "type_url")
|
||||
}
|
||||
if fieldSet["value"] {
|
||||
return p.errorf(anyRepeatedlyUnpacked, "value")
|
||||
}
|
||||
sv.FieldByName("TypeUrl").SetString(extName)
|
||||
sv.FieldByName("Value").SetBytes(b)
|
||||
fieldSet["type_url"] = true
|
||||
fieldSet["value"] = true
|
||||
continue
|
||||
}
|
||||
|
||||
var desc *ExtensionDesc
|
||||
// This could be faster, but it's functional.
|
||||
// TODO: Do something smarter than a linear scan.
|
||||
for _, d := range RegisteredExtensions(reflect.New(st).Interface().(Message)) {
|
||||
if d.Name == extName {
|
||||
desc = d
|
||||
break
|
||||
}
|
||||
}
|
||||
if desc == nil {
|
||||
return p.errorf("unrecognized extension %q", extName)
|
||||
}
|
||||
|
||||
props := &Properties{}
|
||||
props.Parse(desc.Tag)
|
||||
|
||||
typ := reflect.TypeOf(desc.ExtensionType)
|
||||
if err := p.checkForColon(props, typ); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
rep := desc.repeated()
|
||||
|
||||
// Read the extension structure, and set it in
|
||||
// the value we're constructing.
|
||||
var ext reflect.Value
|
||||
if !rep {
|
||||
ext = reflect.New(typ).Elem()
|
||||
} else {
|
||||
ext = reflect.New(typ.Elem()).Elem()
|
||||
}
|
||||
if err := p.readAny(ext, props); err != nil {
|
||||
if _, ok := err.(*RequiredNotSetError); !ok {
|
||||
return err
|
||||
}
|
||||
reqFieldErr = err
|
||||
}
|
||||
ep := sv.Addr().Interface().(Message)
|
||||
if !rep {
|
||||
SetExtension(ep, desc, ext.Interface())
|
||||
} else {
|
||||
old, err := GetExtension(ep, desc)
|
||||
var sl reflect.Value
|
||||
if err == nil {
|
||||
sl = reflect.ValueOf(old) // existing slice
|
||||
} else {
|
||||
sl = reflect.MakeSlice(typ, 0, 1)
|
||||
}
|
||||
sl = reflect.Append(sl, ext)
|
||||
SetExtension(ep, desc, sl.Interface())
|
||||
}
|
||||
if err := p.consumeOptionalSeparator(); err != nil {
|
||||
return err
|
||||
}
|
||||
continue
|
||||
}
|
||||
|
||||
// This is a normal, non-extension field.
|
||||
name := tok.value
|
||||
var dst reflect.Value
|
||||
fi, props, ok := structFieldByName(sprops, name)
|
||||
if ok {
|
||||
dst = sv.Field(fi)
|
||||
} else if oop, ok := sprops.OneofTypes[name]; ok {
|
||||
// It is a oneof.
|
||||
props = oop.Prop
|
||||
nv := reflect.New(oop.Type.Elem())
|
||||
dst = nv.Elem().Field(0)
|
||||
field := sv.Field(oop.Field)
|
||||
if !field.IsNil() {
|
||||
return p.errorf("field '%s' would overwrite already parsed oneof '%s'", name, sv.Type().Field(oop.Field).Name)
|
||||
}
|
||||
field.Set(nv)
|
||||
}
|
||||
if !dst.IsValid() {
|
||||
return p.errorf("unknown field name %q in %v", name, st)
|
||||
}
|
||||
|
||||
if dst.Kind() == reflect.Map {
|
||||
// Consume any colon.
|
||||
if err := p.checkForColon(props, dst.Type()); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
// Construct the map if it doesn't already exist.
|
||||
if dst.IsNil() {
|
||||
dst.Set(reflect.MakeMap(dst.Type()))
|
||||
}
|
||||
key := reflect.New(dst.Type().Key()).Elem()
|
||||
val := reflect.New(dst.Type().Elem()).Elem()
|
||||
|
||||
// The map entry should be this sequence of tokens:
|
||||
// < key : KEY value : VALUE >
|
||||
// However, implementations may omit key or value, and technically
|
||||
// we should support them in any order. See b/28924776 for a time
|
||||
// this went wrong.
|
||||
|
||||
tok := p.next()
|
||||
var terminator string
|
||||
switch tok.value {
|
||||
case "<":
|
||||
terminator = ">"
|
||||
case "{":
|
||||
terminator = "}"
|
||||
default:
|
||||
return p.errorf("expected '{' or '<', found %q", tok.value)
|
||||
}
|
||||
for {
|
||||
tok := p.next()
|
||||
if tok.err != nil {
|
||||
return tok.err
|
||||
}
|
||||
if tok.value == terminator {
|
||||
break
|
||||
}
|
||||
switch tok.value {
|
||||
case "key":
|
||||
if err := p.consumeToken(":"); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := p.readAny(key, props.MapKeyProp); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := p.consumeOptionalSeparator(); err != nil {
|
||||
return err
|
||||
}
|
||||
case "value":
|
||||
if err := p.checkForColon(props.MapValProp, dst.Type().Elem()); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := p.readAny(val, props.MapValProp); err != nil {
|
||||
return err
|
||||
}
|
||||
if err := p.consumeOptionalSeparator(); err != nil {
|
||||
return err
|
||||
}
|
||||
default:
|
||||
p.back()
|
||||
return p.errorf(`expected "key", "value", or %q, found %q`, terminator, tok.value)
|
||||
}
|
||||
}
|
||||
|
||||
dst.SetMapIndex(key, val)
|
||||
continue
|
||||
}
|
||||
|
||||
// Check that it's not already set if it's not a repeated field.
|
||||
if !props.Repeated && fieldSet[name] {
|
||||
return p.errorf("non-repeated field %q was repeated", name)
|
||||
}
|
||||
|
||||
if err := p.checkForColon(props, dst.Type()); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
// Parse into the field.
|
||||
fieldSet[name] = true
|
||||
if err := p.readAny(dst, props); err != nil {
|
||||
if _, ok := err.(*RequiredNotSetError); !ok {
|
||||
return err
|
||||
}
|
||||
reqFieldErr = err
|
||||
}
|
||||
if props.Required {
|
||||
reqCount--
|
||||
}
|
||||
|
||||
if err := p.consumeOptionalSeparator(); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if reqCount > 0 {
|
||||
return p.missingRequiredFieldError(sv)
|
||||
}
|
||||
return reqFieldErr
|
||||
}
|
||||
|
||||
// consumeExtName consumes extension name or expanded Any type URL and the
|
||||
// following ']'. It returns the name or URL consumed.
|
||||
func (p *textParser) consumeExtName() (string, error) {
|
||||
tok := p.next()
|
||||
if tok.err != nil {
|
||||
return "", tok.err
|
||||
}
|
||||
|
||||
// If extension name or type url is quoted, it's a single token.
|
||||
if len(tok.value) > 2 && isQuote(tok.value[0]) && tok.value[len(tok.value)-1] == tok.value[0] {
|
||||
name, err := unquoteC(tok.value[1:len(tok.value)-1], rune(tok.value[0]))
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
return name, p.consumeToken("]")
|
||||
}
|
||||
|
||||
// Consume everything up to "]"
|
||||
var parts []string
|
||||
for tok.value != "]" {
|
||||
parts = append(parts, tok.value)
|
||||
tok = p.next()
|
||||
if tok.err != nil {
|
||||
return "", p.errorf("unrecognized type_url or extension name: %s", tok.err)
|
||||
}
|
||||
if p.done && tok.value != "]" {
|
||||
return "", p.errorf("unclosed type_url or extension name")
|
||||
}
|
||||
}
|
||||
return strings.Join(parts, ""), nil
|
||||
}
|
||||
|
||||
// consumeOptionalSeparator consumes an optional semicolon or comma.
|
||||
// It is used in readStruct to provide backward compatibility.
|
||||
func (p *textParser) consumeOptionalSeparator() error {
|
||||
tok := p.next()
|
||||
if tok.err != nil {
|
||||
return tok.err
|
||||
}
|
||||
if tok.value != ";" && tok.value != "," {
|
||||
p.back()
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *textParser) readAny(v reflect.Value, props *Properties) error {
|
||||
tok := p.next()
|
||||
if tok.err != nil {
|
||||
return tok.err
|
||||
}
|
||||
if tok.value == "" {
|
||||
return p.errorf("unexpected EOF")
|
||||
}
|
||||
|
||||
switch fv := v; fv.Kind() {
|
||||
case reflect.Slice:
|
||||
at := v.Type()
|
||||
if at.Elem().Kind() == reflect.Uint8 {
|
||||
// Special case for []byte
|
||||
if tok.value[0] != '"' && tok.value[0] != '\'' {
|
||||
// Deliberately written out here, as the error after
|
||||
// this switch statement would write "invalid []byte: ...",
|
||||
// which is not as user-friendly.
|
||||
return p.errorf("invalid string: %v", tok.value)
|
||||
}
|
||||
bytes := []byte(tok.unquoted)
|
||||
fv.Set(reflect.ValueOf(bytes))
|
||||
return nil
|
||||
}
|
||||
// Repeated field.
|
||||
if tok.value == "[" {
|
||||
// Repeated field with list notation, like [1,2,3].
|
||||
for {
|
||||
fv.Set(reflect.Append(fv, reflect.New(at.Elem()).Elem()))
|
||||
err := p.readAny(fv.Index(fv.Len()-1), props)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
tok := p.next()
|
||||
if tok.err != nil {
|
||||
return tok.err
|
||||
}
|
||||
if tok.value == "]" {
|
||||
break
|
||||
}
|
||||
if tok.value != "," {
|
||||
return p.errorf("Expected ']' or ',' found %q", tok.value)
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
// One value of the repeated field.
|
||||
p.back()
|
||||
fv.Set(reflect.Append(fv, reflect.New(at.Elem()).Elem()))
|
||||
return p.readAny(fv.Index(fv.Len()-1), props)
|
||||
case reflect.Bool:
|
||||
// true/1/t/True or false/f/0/False.
|
||||
switch tok.value {
|
||||
case "true", "1", "t", "True":
|
||||
fv.SetBool(true)
|
||||
return nil
|
||||
case "false", "0", "f", "False":
|
||||
fv.SetBool(false)
|
||||
return nil
|
||||
}
|
||||
case reflect.Float32, reflect.Float64:
|
||||
v := tok.value
|
||||
// Ignore 'f' for compatibility with output generated by C++, but don't
|
||||
// remove 'f' when the value is "-inf" or "inf".
|
||||
if strings.HasSuffix(v, "f") && tok.value != "-inf" && tok.value != "inf" {
|
||||
v = v[:len(v)-1]
|
||||
}
|
||||
if f, err := strconv.ParseFloat(v, fv.Type().Bits()); err == nil {
|
||||
fv.SetFloat(f)
|
||||
return nil
|
||||
}
|
||||
case reflect.Int32:
|
||||
if x, err := strconv.ParseInt(tok.value, 0, 32); err == nil {
|
||||
fv.SetInt(x)
|
||||
return nil
|
||||
}
|
||||
|
||||
if len(props.Enum) == 0 {
|
||||
break
|
||||
}
|
||||
m, ok := enumValueMaps[props.Enum]
|
||||
if !ok {
|
||||
break
|
||||
}
|
||||
x, ok := m[tok.value]
|
||||
if !ok {
|
||||
break
|
||||
}
|
||||
fv.SetInt(int64(x))
|
||||
return nil
|
||||
case reflect.Int64:
|
||||
if x, err := strconv.ParseInt(tok.value, 0, 64); err == nil {
|
||||
fv.SetInt(x)
|
||||
return nil
|
||||
}
|
||||
|
||||
case reflect.Ptr:
|
||||
// A basic field (indirected through pointer), or a repeated message/group
|
||||
p.back()
|
||||
fv.Set(reflect.New(fv.Type().Elem()))
|
||||
return p.readAny(fv.Elem(), props)
|
||||
case reflect.String:
|
||||
if tok.value[0] == '"' || tok.value[0] == '\'' {
|
||||
fv.SetString(tok.unquoted)
|
||||
return nil
|
||||
}
|
||||
case reflect.Struct:
|
||||
var terminator string
|
||||
switch tok.value {
|
||||
case "{":
|
||||
terminator = "}"
|
||||
case "<":
|
||||
terminator = ">"
|
||||
default:
|
||||
return p.errorf("expected '{' or '<', found %q", tok.value)
|
||||
}
|
||||
// TODO: Handle nested messages which implement encoding.TextUnmarshaler.
|
||||
return p.readStruct(fv, terminator)
|
||||
case reflect.Uint32:
|
||||
if x, err := strconv.ParseUint(tok.value, 0, 32); err == nil {
|
||||
fv.SetUint(uint64(x))
|
||||
return nil
|
||||
}
|
||||
case reflect.Uint64:
|
||||
if x, err := strconv.ParseUint(tok.value, 0, 64); err == nil {
|
||||
fv.SetUint(x)
|
||||
return nil
|
||||
}
|
||||
}
|
||||
return p.errorf("invalid %v: %v", v.Type(), tok.value)
|
||||
}
|
||||
|
||||
// UnmarshalText reads a protocol buffer in Text format. UnmarshalText resets pb
|
||||
// before starting to unmarshal, so any existing data in pb is always removed.
|
||||
// If a required field is not set and no other error occurs,
|
||||
// UnmarshalText returns *RequiredNotSetError.
|
||||
func UnmarshalText(s string, pb Message) error {
|
||||
if um, ok := pb.(encoding.TextUnmarshaler); ok {
|
||||
return um.UnmarshalText([]byte(s))
|
||||
}
|
||||
pb.Reset()
|
||||
v := reflect.ValueOf(pb)
|
||||
return newTextParser(s).readStruct(v.Elem(), "")
|
||||
}
|
||||
201
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/LICENSE
generated
vendored
201
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/LICENSE
generated
vendored
@ -1,201 +0,0 @@
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "{}"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright {yyyy} {name of copyright owner}
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
1
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/NOTICE
generated
vendored
1
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/NOTICE
generated
vendored
@ -1 +0,0 @@
|
||||
Copyright 2012 Matt T. Proud (matt.proud@gmail.com)
|
||||
1
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/pbutil/.gitignore
generated
vendored
1
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/pbutil/.gitignore
generated
vendored
@ -1 +0,0 @@
|
||||
cover.dat
|
||||
7
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/pbutil/Makefile
generated
vendored
7
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/pbutil/Makefile
generated
vendored
@ -1,7 +0,0 @@
|
||||
all:
|
||||
|
||||
cover:
|
||||
go test -cover -v -coverprofile=cover.dat ./...
|
||||
go tool cover -func cover.dat
|
||||
|
||||
.PHONY: cover
|
||||
75
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/pbutil/decode.go
generated
vendored
75
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/pbutil/decode.go
generated
vendored
@ -1,75 +0,0 @@
|
||||
// Copyright 2013 Matt T. Proud
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package pbutil
|
||||
|
||||
import (
|
||||
"encoding/binary"
|
||||
"errors"
|
||||
"io"
|
||||
|
||||
"github.com/golang/protobuf/proto"
|
||||
)
|
||||
|
||||
var errInvalidVarint = errors.New("invalid varint32 encountered")
|
||||
|
||||
// ReadDelimited decodes a message from the provided length-delimited stream,
|
||||
// where the length is encoded as 32-bit varint prefix to the message body.
|
||||
// It returns the total number of bytes read and any applicable error. This is
|
||||
// roughly equivalent to the companion Java API's
|
||||
// MessageLite#parseDelimitedFrom. As per the reader contract, this function
|
||||
// calls r.Read repeatedly as required until exactly one message including its
|
||||
// prefix is read and decoded (or an error has occurred). The function never
|
||||
// reads more bytes from the stream than required. The function never returns
|
||||
// an error if a message has been read and decoded correctly, even if the end
|
||||
// of the stream has been reached in doing so. In that case, any subsequent
|
||||
// calls return (0, io.EOF).
|
||||
func ReadDelimited(r io.Reader, m proto.Message) (n int, err error) {
|
||||
// Per AbstractParser#parsePartialDelimitedFrom with
|
||||
// CodedInputStream#readRawVarint32.
|
||||
var headerBuf [binary.MaxVarintLen32]byte
|
||||
var bytesRead, varIntBytes int
|
||||
var messageLength uint64
|
||||
for varIntBytes == 0 { // i.e. no varint has been decoded yet.
|
||||
if bytesRead >= len(headerBuf) {
|
||||
return bytesRead, errInvalidVarint
|
||||
}
|
||||
// We have to read byte by byte here to avoid reading more bytes
|
||||
// than required. Each read byte is appended to what we have
|
||||
// read before.
|
||||
newBytesRead, err := r.Read(headerBuf[bytesRead : bytesRead+1])
|
||||
if newBytesRead == 0 {
|
||||
if err != nil {
|
||||
return bytesRead, err
|
||||
}
|
||||
// A Reader should not return (0, nil), but if it does,
|
||||
// it should be treated as no-op (according to the
|
||||
// Reader contract). So let's go on...
|
||||
continue
|
||||
}
|
||||
bytesRead += newBytesRead
|
||||
// Now present everything read so far to the varint decoder and
|
||||
// see if a varint can be decoded already.
|
||||
messageLength, varIntBytes = proto.DecodeVarint(headerBuf[:bytesRead])
|
||||
}
|
||||
|
||||
messageBuf := make([]byte, messageLength)
|
||||
newBytesRead, err := io.ReadFull(r, messageBuf)
|
||||
bytesRead += newBytesRead
|
||||
if err != nil {
|
||||
return bytesRead, err
|
||||
}
|
||||
|
||||
return bytesRead, proto.Unmarshal(messageBuf, m)
|
||||
}
|
||||
16
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/pbutil/doc.go
generated
vendored
16
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/pbutil/doc.go
generated
vendored
@ -1,16 +0,0 @@
|
||||
// Copyright 2013 Matt T. Proud
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
// Package pbutil provides record length-delimited Protocol Buffer streaming.
|
||||
package pbutil
|
||||
46
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/pbutil/encode.go
generated
vendored
46
watchdog/vendor/github.com/matttproud/golang_protobuf_extensions/pbutil/encode.go
generated
vendored
@ -1,46 +0,0 @@
|
||||
// Copyright 2013 Matt T. Proud
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package pbutil
|
||||
|
||||
import (
|
||||
"encoding/binary"
|
||||
"io"
|
||||
|
||||
"github.com/golang/protobuf/proto"
|
||||
)
|
||||
|
||||
// WriteDelimited encodes and dumps a message to the provided writer prefixed
|
||||
// with a 32-bit varint indicating the length of the encoded message, producing
|
||||
// a length-delimited record stream, which can be used to chain together
|
||||
// encoded messages of the same type together in a file. It returns the total
|
||||
// number of bytes written and any applicable error. This is roughly
|
||||
// equivalent to the companion Java API's MessageLite#writeDelimitedTo.
|
||||
func WriteDelimited(w io.Writer, m proto.Message) (n int, err error) {
|
||||
buffer, err := proto.Marshal(m)
|
||||
if err != nil {
|
||||
return 0, err
|
||||
}
|
||||
|
||||
var buf [binary.MaxVarintLen32]byte
|
||||
encodedLength := binary.PutUvarint(buf[:], uint64(len(buffer)))
|
||||
|
||||
sync, err := w.Write(buf[:encodedLength])
|
||||
if err != nil {
|
||||
return sync, err
|
||||
}
|
||||
|
||||
n, err = w.Write(buffer)
|
||||
return n + sync, err
|
||||
}
|
||||
21
watchdog/vendor/github.com/openfaas/faas-middleware/LICENSE
generated
vendored
21
watchdog/vendor/github.com/openfaas/faas-middleware/LICENSE
generated
vendored
@ -1,21 +0,0 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2019 OpenFaaS
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
@ -1,67 +0,0 @@
|
||||
package limiter
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"net/http"
|
||||
"sync/atomic"
|
||||
)
|
||||
|
||||
type ConcurrencyLimiter struct {
|
||||
backendHTTPHandler http.Handler
|
||||
/*
|
||||
We keep two counters here in order to make it so that we can know when a request has gone to completed
|
||||
in the tests. We could wrap these up in a condvar, so there's no need to spinlock, but that seems overkill
|
||||
for testing.
|
||||
|
||||
This is effectively a very fancy semaphore built for optimistic concurrency only, and with spinlocks. If
|
||||
you want to add timeouts here / pessimistic concurrency, signaling needs to be added and/or a condvar esque
|
||||
sorta thing needs to be done to wake up waiters who are waiting post-spin.
|
||||
|
||||
Otherwise, there's all sorts of futzing in order to make sure that the concurrency limiter handler
|
||||
has completed
|
||||
The math works on overflow:
|
||||
var x, y uint64
|
||||
x = (1 << 64 - 1)
|
||||
y = (1 << 64 - 1)
|
||||
x++
|
||||
fmt.Println(x)
|
||||
fmt.Println(y)
|
||||
fmt.Println(x - y)
|
||||
Prints:
|
||||
0
|
||||
18446744073709551615
|
||||
1
|
||||
*/
|
||||
requestsStarted uint64
|
||||
requestsCompleted uint64
|
||||
|
||||
maxInflightRequests uint64
|
||||
}
|
||||
|
||||
func (cl *ConcurrencyLimiter) ServeHTTP(w http.ResponseWriter, r *http.Request) {
|
||||
requestsStarted := atomic.AddUint64(&cl.requestsStarted, 1)
|
||||
completedRequested := atomic.LoadUint64(&cl.requestsCompleted)
|
||||
if requestsStarted-completedRequested > cl.maxInflightRequests {
|
||||
// This is a failure pathway, and we do not want to block on the write to finish
|
||||
atomic.AddUint64(&cl.requestsCompleted, 1)
|
||||
w.WriteHeader(http.StatusTooManyRequests)
|
||||
fmt.Fprintf(w, "Concurrent request limit exceeded. Max concurrent requests: %d\n", cl.maxInflightRequests)
|
||||
return
|
||||
}
|
||||
cl.backendHTTPHandler.ServeHTTP(w, r)
|
||||
atomic.AddUint64(&cl.requestsCompleted, 1)
|
||||
}
|
||||
|
||||
// NewConcurrencyLimiter creates a handler which limits the active number of active, concurrent
|
||||
// requests. If the concurrency limit is less than, or equal to 0, then it will just return the handler
|
||||
// passed to it.
|
||||
func NewConcurrencyLimiter(handler http.Handler, concurrencyLimit int) http.Handler {
|
||||
if concurrencyLimit <= 0 {
|
||||
return handler
|
||||
}
|
||||
|
||||
return &ConcurrencyLimiter{
|
||||
backendHTTPHandler: handler,
|
||||
maxInflightRequests: uint64(concurrencyLimit),
|
||||
}
|
||||
}
|
||||
201
watchdog/vendor/github.com/prometheus/client_golang/LICENSE
generated
vendored
201
watchdog/vendor/github.com/prometheus/client_golang/LICENSE
generated
vendored
@ -1,201 +0,0 @@
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright [yyyy] [name of copyright owner]
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
23
watchdog/vendor/github.com/prometheus/client_golang/NOTICE
generated
vendored
23
watchdog/vendor/github.com/prometheus/client_golang/NOTICE
generated
vendored
@ -1,23 +0,0 @@
|
||||
Prometheus instrumentation library for Go applications
|
||||
Copyright 2012-2015 The Prometheus Authors
|
||||
|
||||
This product includes software developed at
|
||||
SoundCloud Ltd. (http://soundcloud.com/).
|
||||
|
||||
|
||||
The following components are included in this product:
|
||||
|
||||
perks - a fork of https://github.com/bmizerany/perks
|
||||
https://github.com/beorn7/perks
|
||||
Copyright 2013-2015 Blake Mizerany, Björn Rabenstein
|
||||
See https://github.com/beorn7/perks/blob/master/README.md for license details.
|
||||
|
||||
Go support for Protocol Buffers - Google's data interchange format
|
||||
http://github.com/golang/protobuf/
|
||||
Copyright 2010 The Go Authors
|
||||
See source code for license details.
|
||||
|
||||
Support for streaming Protocol Buffer messages for the Go language (golang).
|
||||
https://github.com/matttproud/golang_protobuf_extensions
|
||||
Copyright 2013 Matt T. Proud
|
||||
Licensed under the Apache License, Version 2.0
|
||||
1
watchdog/vendor/github.com/prometheus/client_golang/prometheus/.gitignore
generated
vendored
1
watchdog/vendor/github.com/prometheus/client_golang/prometheus/.gitignore
generated
vendored
@ -1 +0,0 @@
|
||||
command-line-arguments.test
|
||||
1
watchdog/vendor/github.com/prometheus/client_golang/prometheus/README.md
generated
vendored
1
watchdog/vendor/github.com/prometheus/client_golang/prometheus/README.md
generated
vendored
@ -1 +0,0 @@
|
||||
See [](https://godoc.org/github.com/prometheus/client_golang/prometheus).
|
||||
120
watchdog/vendor/github.com/prometheus/client_golang/prometheus/collector.go
generated
vendored
120
watchdog/vendor/github.com/prometheus/client_golang/prometheus/collector.go
generated
vendored
@ -1,120 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
// Collector is the interface implemented by anything that can be used by
|
||||
// Prometheus to collect metrics. A Collector has to be registered for
|
||||
// collection. See Registerer.Register.
|
||||
//
|
||||
// The stock metrics provided by this package (Gauge, Counter, Summary,
|
||||
// Histogram, Untyped) are also Collectors (which only ever collect one metric,
|
||||
// namely itself). An implementer of Collector may, however, collect multiple
|
||||
// metrics in a coordinated fashion and/or create metrics on the fly. Examples
|
||||
// for collectors already implemented in this library are the metric vectors
|
||||
// (i.e. collection of multiple instances of the same Metric but with different
|
||||
// label values) like GaugeVec or SummaryVec, and the ExpvarCollector.
|
||||
type Collector interface {
|
||||
// Describe sends the super-set of all possible descriptors of metrics
|
||||
// collected by this Collector to the provided channel and returns once
|
||||
// the last descriptor has been sent. The sent descriptors fulfill the
|
||||
// consistency and uniqueness requirements described in the Desc
|
||||
// documentation.
|
||||
//
|
||||
// It is valid if one and the same Collector sends duplicate
|
||||
// descriptors. Those duplicates are simply ignored. However, two
|
||||
// different Collectors must not send duplicate descriptors.
|
||||
//
|
||||
// Sending no descriptor at all marks the Collector as “unchecked”,
|
||||
// i.e. no checks will be performed at registration time, and the
|
||||
// Collector may yield any Metric it sees fit in its Collect method.
|
||||
//
|
||||
// This method idempotently sends the same descriptors throughout the
|
||||
// lifetime of the Collector. It may be called concurrently and
|
||||
// therefore must be implemented in a concurrency safe way.
|
||||
//
|
||||
// If a Collector encounters an error while executing this method, it
|
||||
// must send an invalid descriptor (created with NewInvalidDesc) to
|
||||
// signal the error to the registry.
|
||||
Describe(chan<- *Desc)
|
||||
// Collect is called by the Prometheus registry when collecting
|
||||
// metrics. The implementation sends each collected metric via the
|
||||
// provided channel and returns once the last metric has been sent. The
|
||||
// descriptor of each sent metric is one of those returned by Describe
|
||||
// (unless the Collector is unchecked, see above). Returned metrics that
|
||||
// share the same descriptor must differ in their variable label
|
||||
// values.
|
||||
//
|
||||
// This method may be called concurrently and must therefore be
|
||||
// implemented in a concurrency safe way. Blocking occurs at the expense
|
||||
// of total performance of rendering all registered metrics. Ideally,
|
||||
// Collector implementations support concurrent readers.
|
||||
Collect(chan<- Metric)
|
||||
}
|
||||
|
||||
// DescribeByCollect is a helper to implement the Describe method of a custom
|
||||
// Collector. It collects the metrics from the provided Collector and sends
|
||||
// their descriptors to the provided channel.
|
||||
//
|
||||
// If a Collector collects the same metrics throughout its lifetime, its
|
||||
// Describe method can simply be implemented as:
|
||||
//
|
||||
// func (c customCollector) Describe(ch chan<- *Desc) {
|
||||
// DescribeByCollect(c, ch)
|
||||
// }
|
||||
//
|
||||
// However, this will not work if the metrics collected change dynamically over
|
||||
// the lifetime of the Collector in a way that their combined set of descriptors
|
||||
// changes as well. The shortcut implementation will then violate the contract
|
||||
// of the Describe method. If a Collector sometimes collects no metrics at all
|
||||
// (for example vectors like CounterVec, GaugeVec, etc., which only collect
|
||||
// metrics after a metric with a fully specified label set has been accessed),
|
||||
// it might even get registered as an unchecked Collecter (cf. the Register
|
||||
// method of the Registerer interface). Hence, only use this shortcut
|
||||
// implementation of Describe if you are certain to fulfill the contract.
|
||||
//
|
||||
// The Collector example demonstrates a use of DescribeByCollect.
|
||||
func DescribeByCollect(c Collector, descs chan<- *Desc) {
|
||||
metrics := make(chan Metric)
|
||||
go func() {
|
||||
c.Collect(metrics)
|
||||
close(metrics)
|
||||
}()
|
||||
for m := range metrics {
|
||||
descs <- m.Desc()
|
||||
}
|
||||
}
|
||||
|
||||
// selfCollector implements Collector for a single Metric so that the Metric
|
||||
// collects itself. Add it as an anonymous field to a struct that implements
|
||||
// Metric, and call init with the Metric itself as an argument.
|
||||
type selfCollector struct {
|
||||
self Metric
|
||||
}
|
||||
|
||||
// init provides the selfCollector with a reference to the metric it is supposed
|
||||
// to collect. It is usually called within the factory function to create a
|
||||
// metric. See example.
|
||||
func (c *selfCollector) init(self Metric) {
|
||||
c.self = self
|
||||
}
|
||||
|
||||
// Describe implements Collector.
|
||||
func (c *selfCollector) Describe(ch chan<- *Desc) {
|
||||
ch <- c.self.Desc()
|
||||
}
|
||||
|
||||
// Collect implements Collector.
|
||||
func (c *selfCollector) Collect(ch chan<- Metric) {
|
||||
ch <- c.self
|
||||
}
|
||||
277
watchdog/vendor/github.com/prometheus/client_golang/prometheus/counter.go
generated
vendored
277
watchdog/vendor/github.com/prometheus/client_golang/prometheus/counter.go
generated
vendored
@ -1,277 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"math"
|
||||
"sync/atomic"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
)
|
||||
|
||||
// Counter is a Metric that represents a single numerical value that only ever
|
||||
// goes up. That implies that it cannot be used to count items whose number can
|
||||
// also go down, e.g. the number of currently running goroutines. Those
|
||||
// "counters" are represented by Gauges.
|
||||
//
|
||||
// A Counter is typically used to count requests served, tasks completed, errors
|
||||
// occurred, etc.
|
||||
//
|
||||
// To create Counter instances, use NewCounter.
|
||||
type Counter interface {
|
||||
Metric
|
||||
Collector
|
||||
|
||||
// Inc increments the counter by 1. Use Add to increment it by arbitrary
|
||||
// non-negative values.
|
||||
Inc()
|
||||
// Add adds the given value to the counter. It panics if the value is <
|
||||
// 0.
|
||||
Add(float64)
|
||||
}
|
||||
|
||||
// CounterOpts is an alias for Opts. See there for doc comments.
|
||||
type CounterOpts Opts
|
||||
|
||||
// NewCounter creates a new Counter based on the provided CounterOpts.
|
||||
//
|
||||
// The returned implementation tracks the counter value in two separate
|
||||
// variables, a float64 and a uint64. The latter is used to track calls of the
|
||||
// Inc method and calls of the Add method with a value that can be represented
|
||||
// as a uint64. This allows atomic increments of the counter with optimal
|
||||
// performance. (It is common to have an Inc call in very hot execution paths.)
|
||||
// Both internal tracking values are added up in the Write method. This has to
|
||||
// be taken into account when it comes to precision and overflow behavior.
|
||||
func NewCounter(opts CounterOpts) Counter {
|
||||
desc := NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
nil,
|
||||
opts.ConstLabels,
|
||||
)
|
||||
result := &counter{desc: desc, labelPairs: desc.constLabelPairs}
|
||||
result.init(result) // Init self-collection.
|
||||
return result
|
||||
}
|
||||
|
||||
type counter struct {
|
||||
// valBits contains the bits of the represented float64 value, while
|
||||
// valInt stores values that are exact integers. Both have to go first
|
||||
// in the struct to guarantee alignment for atomic operations.
|
||||
// http://golang.org/pkg/sync/atomic/#pkg-note-BUG
|
||||
valBits uint64
|
||||
valInt uint64
|
||||
|
||||
selfCollector
|
||||
desc *Desc
|
||||
|
||||
labelPairs []*dto.LabelPair
|
||||
}
|
||||
|
||||
func (c *counter) Desc() *Desc {
|
||||
return c.desc
|
||||
}
|
||||
|
||||
func (c *counter) Add(v float64) {
|
||||
if v < 0 {
|
||||
panic(errors.New("counter cannot decrease in value"))
|
||||
}
|
||||
ival := uint64(v)
|
||||
if float64(ival) == v {
|
||||
atomic.AddUint64(&c.valInt, ival)
|
||||
return
|
||||
}
|
||||
|
||||
for {
|
||||
oldBits := atomic.LoadUint64(&c.valBits)
|
||||
newBits := math.Float64bits(math.Float64frombits(oldBits) + v)
|
||||
if atomic.CompareAndSwapUint64(&c.valBits, oldBits, newBits) {
|
||||
return
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (c *counter) Inc() {
|
||||
atomic.AddUint64(&c.valInt, 1)
|
||||
}
|
||||
|
||||
func (c *counter) Write(out *dto.Metric) error {
|
||||
fval := math.Float64frombits(atomic.LoadUint64(&c.valBits))
|
||||
ival := atomic.LoadUint64(&c.valInt)
|
||||
val := fval + float64(ival)
|
||||
|
||||
return populateMetric(CounterValue, val, c.labelPairs, out)
|
||||
}
|
||||
|
||||
// CounterVec is a Collector that bundles a set of Counters that all share the
|
||||
// same Desc, but have different values for their variable labels. This is used
|
||||
// if you want to count the same thing partitioned by various dimensions
|
||||
// (e.g. number of HTTP requests, partitioned by response code and
|
||||
// method). Create instances with NewCounterVec.
|
||||
type CounterVec struct {
|
||||
*metricVec
|
||||
}
|
||||
|
||||
// NewCounterVec creates a new CounterVec based on the provided CounterOpts and
|
||||
// partitioned by the given label names.
|
||||
func NewCounterVec(opts CounterOpts, labelNames []string) *CounterVec {
|
||||
desc := NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
labelNames,
|
||||
opts.ConstLabels,
|
||||
)
|
||||
return &CounterVec{
|
||||
metricVec: newMetricVec(desc, func(lvs ...string) Metric {
|
||||
if len(lvs) != len(desc.variableLabels) {
|
||||
panic(makeInconsistentCardinalityError(desc.fqName, desc.variableLabels, lvs))
|
||||
}
|
||||
result := &counter{desc: desc, labelPairs: makeLabelPairs(desc, lvs)}
|
||||
result.init(result) // Init self-collection.
|
||||
return result
|
||||
}),
|
||||
}
|
||||
}
|
||||
|
||||
// GetMetricWithLabelValues returns the Counter for the given slice of label
|
||||
// values (same order as the VariableLabels in Desc). If that combination of
|
||||
// label values is accessed for the first time, a new Counter is created.
|
||||
//
|
||||
// It is possible to call this method without using the returned Counter to only
|
||||
// create the new Counter but leave it at its starting value 0. See also the
|
||||
// SummaryVec example.
|
||||
//
|
||||
// Keeping the Counter for later use is possible (and should be considered if
|
||||
// performance is critical), but keep in mind that Reset, DeleteLabelValues and
|
||||
// Delete can be used to delete the Counter from the CounterVec. In that case,
|
||||
// the Counter will still exist, but it will not be exported anymore, even if a
|
||||
// Counter with the same label values is created later.
|
||||
//
|
||||
// An error is returned if the number of label values is not the same as the
|
||||
// number of VariableLabels in Desc (minus any curried labels).
|
||||
//
|
||||
// Note that for more than one label value, this method is prone to mistakes
|
||||
// caused by an incorrect order of arguments. Consider GetMetricWith(Labels) as
|
||||
// an alternative to avoid that type of mistake. For higher label numbers, the
|
||||
// latter has a much more readable (albeit more verbose) syntax, but it comes
|
||||
// with a performance overhead (for creating and processing the Labels map).
|
||||
// See also the GaugeVec example.
|
||||
func (v *CounterVec) GetMetricWithLabelValues(lvs ...string) (Counter, error) {
|
||||
metric, err := v.metricVec.getMetricWithLabelValues(lvs...)
|
||||
if metric != nil {
|
||||
return metric.(Counter), err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// GetMetricWith returns the Counter for the given Labels map (the label names
|
||||
// must match those of the VariableLabels in Desc). If that label map is
|
||||
// accessed for the first time, a new Counter is created. Implications of
|
||||
// creating a Counter without using it and keeping the Counter for later use are
|
||||
// the same as for GetMetricWithLabelValues.
|
||||
//
|
||||
// An error is returned if the number and names of the Labels are inconsistent
|
||||
// with those of the VariableLabels in Desc (minus any curried labels).
|
||||
//
|
||||
// This method is used for the same purpose as
|
||||
// GetMetricWithLabelValues(...string). See there for pros and cons of the two
|
||||
// methods.
|
||||
func (v *CounterVec) GetMetricWith(labels Labels) (Counter, error) {
|
||||
metric, err := v.metricVec.getMetricWith(labels)
|
||||
if metric != nil {
|
||||
return metric.(Counter), err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// WithLabelValues works as GetMetricWithLabelValues, but panics where
|
||||
// GetMetricWithLabelValues would have returned an error. Not returning an
|
||||
// error allows shortcuts like
|
||||
// myVec.WithLabelValues("404", "GET").Add(42)
|
||||
func (v *CounterVec) WithLabelValues(lvs ...string) Counter {
|
||||
c, err := v.GetMetricWithLabelValues(lvs...)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return c
|
||||
}
|
||||
|
||||
// With works as GetMetricWith, but panics where GetMetricWithLabels would have
|
||||
// returned an error. Not returning an error allows shortcuts like
|
||||
// myVec.With(prometheus.Labels{"code": "404", "method": "GET"}).Add(42)
|
||||
func (v *CounterVec) With(labels Labels) Counter {
|
||||
c, err := v.GetMetricWith(labels)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return c
|
||||
}
|
||||
|
||||
// CurryWith returns a vector curried with the provided labels, i.e. the
|
||||
// returned vector has those labels pre-set for all labeled operations performed
|
||||
// on it. The cardinality of the curried vector is reduced accordingly. The
|
||||
// order of the remaining labels stays the same (just with the curried labels
|
||||
// taken out of the sequence – which is relevant for the
|
||||
// (GetMetric)WithLabelValues methods). It is possible to curry a curried
|
||||
// vector, but only with labels not yet used for currying before.
|
||||
//
|
||||
// The metrics contained in the CounterVec are shared between the curried and
|
||||
// uncurried vectors. They are just accessed differently. Curried and uncurried
|
||||
// vectors behave identically in terms of collection. Only one must be
|
||||
// registered with a given registry (usually the uncurried version). The Reset
|
||||
// method deletes all metrics, even if called on a curried vector.
|
||||
func (v *CounterVec) CurryWith(labels Labels) (*CounterVec, error) {
|
||||
vec, err := v.curryWith(labels)
|
||||
if vec != nil {
|
||||
return &CounterVec{vec}, err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// MustCurryWith works as CurryWith but panics where CurryWith would have
|
||||
// returned an error.
|
||||
func (v *CounterVec) MustCurryWith(labels Labels) *CounterVec {
|
||||
vec, err := v.CurryWith(labels)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return vec
|
||||
}
|
||||
|
||||
// CounterFunc is a Counter whose value is determined at collect time by calling a
|
||||
// provided function.
|
||||
//
|
||||
// To create CounterFunc instances, use NewCounterFunc.
|
||||
type CounterFunc interface {
|
||||
Metric
|
||||
Collector
|
||||
}
|
||||
|
||||
// NewCounterFunc creates a new CounterFunc based on the provided
|
||||
// CounterOpts. The value reported is determined by calling the given function
|
||||
// from within the Write method. Take into account that metric collection may
|
||||
// happen concurrently. If that results in concurrent calls to Write, like in
|
||||
// the case where a CounterFunc is directly registered with Prometheus, the
|
||||
// provided function must be concurrency-safe. The function should also honor
|
||||
// the contract for a Counter (values only go up, not down), but compliance will
|
||||
// not be checked.
|
||||
func NewCounterFunc(opts CounterOpts, function func() float64) CounterFunc {
|
||||
return newValueFunc(NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
nil,
|
||||
opts.ConstLabels,
|
||||
), CounterValue, function)
|
||||
}
|
||||
184
watchdog/vendor/github.com/prometheus/client_golang/prometheus/desc.go
generated
vendored
184
watchdog/vendor/github.com/prometheus/client_golang/prometheus/desc.go
generated
vendored
@ -1,184 +0,0 @@
|
||||
// Copyright 2016 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
"sort"
|
||||
"strings"
|
||||
|
||||
"github.com/golang/protobuf/proto"
|
||||
"github.com/prometheus/common/model"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
)
|
||||
|
||||
// Desc is the descriptor used by every Prometheus Metric. It is essentially
|
||||
// the immutable meta-data of a Metric. The normal Metric implementations
|
||||
// included in this package manage their Desc under the hood. Users only have to
|
||||
// deal with Desc if they use advanced features like the ExpvarCollector or
|
||||
// custom Collectors and Metrics.
|
||||
//
|
||||
// Descriptors registered with the same registry have to fulfill certain
|
||||
// consistency and uniqueness criteria if they share the same fully-qualified
|
||||
// name: They must have the same help string and the same label names (aka label
|
||||
// dimensions) in each, constLabels and variableLabels, but they must differ in
|
||||
// the values of the constLabels.
|
||||
//
|
||||
// Descriptors that share the same fully-qualified names and the same label
|
||||
// values of their constLabels are considered equal.
|
||||
//
|
||||
// Use NewDesc to create new Desc instances.
|
||||
type Desc struct {
|
||||
// fqName has been built from Namespace, Subsystem, and Name.
|
||||
fqName string
|
||||
// help provides some helpful information about this metric.
|
||||
help string
|
||||
// constLabelPairs contains precalculated DTO label pairs based on
|
||||
// the constant labels.
|
||||
constLabelPairs []*dto.LabelPair
|
||||
// VariableLabels contains names of labels for which the metric
|
||||
// maintains variable values.
|
||||
variableLabels []string
|
||||
// id is a hash of the values of the ConstLabels and fqName. This
|
||||
// must be unique among all registered descriptors and can therefore be
|
||||
// used as an identifier of the descriptor.
|
||||
id uint64
|
||||
// dimHash is a hash of the label names (preset and variable) and the
|
||||
// Help string. Each Desc with the same fqName must have the same
|
||||
// dimHash.
|
||||
dimHash uint64
|
||||
// err is an error that occurred during construction. It is reported on
|
||||
// registration time.
|
||||
err error
|
||||
}
|
||||
|
||||
// NewDesc allocates and initializes a new Desc. Errors are recorded in the Desc
|
||||
// and will be reported on registration time. variableLabels and constLabels can
|
||||
// be nil if no such labels should be set. fqName must not be empty.
|
||||
//
|
||||
// variableLabels only contain the label names. Their label values are variable
|
||||
// and therefore not part of the Desc. (They are managed within the Metric.)
|
||||
//
|
||||
// For constLabels, the label values are constant. Therefore, they are fully
|
||||
// specified in the Desc. See the Collector example for a usage pattern.
|
||||
func NewDesc(fqName, help string, variableLabels []string, constLabels Labels) *Desc {
|
||||
d := &Desc{
|
||||
fqName: fqName,
|
||||
help: help,
|
||||
variableLabels: variableLabels,
|
||||
}
|
||||
if !model.IsValidMetricName(model.LabelValue(fqName)) {
|
||||
d.err = fmt.Errorf("%q is not a valid metric name", fqName)
|
||||
return d
|
||||
}
|
||||
// labelValues contains the label values of const labels (in order of
|
||||
// their sorted label names) plus the fqName (at position 0).
|
||||
labelValues := make([]string, 1, len(constLabels)+1)
|
||||
labelValues[0] = fqName
|
||||
labelNames := make([]string, 0, len(constLabels)+len(variableLabels))
|
||||
labelNameSet := map[string]struct{}{}
|
||||
// First add only the const label names and sort them...
|
||||
for labelName := range constLabels {
|
||||
if !checkLabelName(labelName) {
|
||||
d.err = fmt.Errorf("%q is not a valid label name for metric %q", labelName, fqName)
|
||||
return d
|
||||
}
|
||||
labelNames = append(labelNames, labelName)
|
||||
labelNameSet[labelName] = struct{}{}
|
||||
}
|
||||
sort.Strings(labelNames)
|
||||
// ... so that we can now add const label values in the order of their names.
|
||||
for _, labelName := range labelNames {
|
||||
labelValues = append(labelValues, constLabels[labelName])
|
||||
}
|
||||
// Validate the const label values. They can't have a wrong cardinality, so
|
||||
// use in len(labelValues) as expectedNumberOfValues.
|
||||
if err := validateLabelValues(labelValues, len(labelValues)); err != nil {
|
||||
d.err = err
|
||||
return d
|
||||
}
|
||||
// Now add the variable label names, but prefix them with something that
|
||||
// cannot be in a regular label name. That prevents matching the label
|
||||
// dimension with a different mix between preset and variable labels.
|
||||
for _, labelName := range variableLabels {
|
||||
if !checkLabelName(labelName) {
|
||||
d.err = fmt.Errorf("%q is not a valid label name for metric %q", labelName, fqName)
|
||||
return d
|
||||
}
|
||||
labelNames = append(labelNames, "$"+labelName)
|
||||
labelNameSet[labelName] = struct{}{}
|
||||
}
|
||||
if len(labelNames) != len(labelNameSet) {
|
||||
d.err = errors.New("duplicate label names")
|
||||
return d
|
||||
}
|
||||
|
||||
vh := hashNew()
|
||||
for _, val := range labelValues {
|
||||
vh = hashAdd(vh, val)
|
||||
vh = hashAddByte(vh, separatorByte)
|
||||
}
|
||||
d.id = vh
|
||||
// Sort labelNames so that order doesn't matter for the hash.
|
||||
sort.Strings(labelNames)
|
||||
// Now hash together (in this order) the help string and the sorted
|
||||
// label names.
|
||||
lh := hashNew()
|
||||
lh = hashAdd(lh, help)
|
||||
lh = hashAddByte(lh, separatorByte)
|
||||
for _, labelName := range labelNames {
|
||||
lh = hashAdd(lh, labelName)
|
||||
lh = hashAddByte(lh, separatorByte)
|
||||
}
|
||||
d.dimHash = lh
|
||||
|
||||
d.constLabelPairs = make([]*dto.LabelPair, 0, len(constLabels))
|
||||
for n, v := range constLabels {
|
||||
d.constLabelPairs = append(d.constLabelPairs, &dto.LabelPair{
|
||||
Name: proto.String(n),
|
||||
Value: proto.String(v),
|
||||
})
|
||||
}
|
||||
sort.Sort(labelPairSorter(d.constLabelPairs))
|
||||
return d
|
||||
}
|
||||
|
||||
// NewInvalidDesc returns an invalid descriptor, i.e. a descriptor with the
|
||||
// provided error set. If a collector returning such a descriptor is registered,
|
||||
// registration will fail with the provided error. NewInvalidDesc can be used by
|
||||
// a Collector to signal inability to describe itself.
|
||||
func NewInvalidDesc(err error) *Desc {
|
||||
return &Desc{
|
||||
err: err,
|
||||
}
|
||||
}
|
||||
|
||||
func (d *Desc) String() string {
|
||||
lpStrings := make([]string, 0, len(d.constLabelPairs))
|
||||
for _, lp := range d.constLabelPairs {
|
||||
lpStrings = append(
|
||||
lpStrings,
|
||||
fmt.Sprintf("%s=%q", lp.GetName(), lp.GetValue()),
|
||||
)
|
||||
}
|
||||
return fmt.Sprintf(
|
||||
"Desc{fqName: %q, help: %q, constLabels: {%s}, variableLabels: %v}",
|
||||
d.fqName,
|
||||
d.help,
|
||||
strings.Join(lpStrings, ","),
|
||||
d.variableLabels,
|
||||
)
|
||||
}
|
||||
201
watchdog/vendor/github.com/prometheus/client_golang/prometheus/doc.go
generated
vendored
201
watchdog/vendor/github.com/prometheus/client_golang/prometheus/doc.go
generated
vendored
@ -1,201 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
// Package prometheus is the core instrumentation package. It provides metrics
|
||||
// primitives to instrument code for monitoring. It also offers a registry for
|
||||
// metrics. Sub-packages allow to expose the registered metrics via HTTP
|
||||
// (package promhttp) or push them to a Pushgateway (package push). There is
|
||||
// also a sub-package promauto, which provides metrics constructors with
|
||||
// automatic registration.
|
||||
//
|
||||
// All exported functions and methods are safe to be used concurrently unless
|
||||
// specified otherwise.
|
||||
//
|
||||
// A Basic Example
|
||||
//
|
||||
// As a starting point, a very basic usage example:
|
||||
//
|
||||
// package main
|
||||
//
|
||||
// import (
|
||||
// "log"
|
||||
// "net/http"
|
||||
//
|
||||
// "github.com/prometheus/client_golang/prometheus"
|
||||
// "github.com/prometheus/client_golang/prometheus/promhttp"
|
||||
// )
|
||||
//
|
||||
// var (
|
||||
// cpuTemp = prometheus.NewGauge(prometheus.GaugeOpts{
|
||||
// Name: "cpu_temperature_celsius",
|
||||
// Help: "Current temperature of the CPU.",
|
||||
// })
|
||||
// hdFailures = prometheus.NewCounterVec(
|
||||
// prometheus.CounterOpts{
|
||||
// Name: "hd_errors_total",
|
||||
// Help: "Number of hard-disk errors.",
|
||||
// },
|
||||
// []string{"device"},
|
||||
// )
|
||||
// )
|
||||
//
|
||||
// func init() {
|
||||
// // Metrics have to be registered to be exposed:
|
||||
// prometheus.MustRegister(cpuTemp)
|
||||
// prometheus.MustRegister(hdFailures)
|
||||
// }
|
||||
//
|
||||
// func main() {
|
||||
// cpuTemp.Set(65.3)
|
||||
// hdFailures.With(prometheus.Labels{"device":"/dev/sda"}).Inc()
|
||||
//
|
||||
// // The Handler function provides a default handler to expose metrics
|
||||
// // via an HTTP server. "/metrics" is the usual endpoint for that.
|
||||
// http.Handle("/metrics", promhttp.Handler())
|
||||
// log.Fatal(http.ListenAndServe(":8080", nil))
|
||||
// }
|
||||
//
|
||||
//
|
||||
// This is a complete program that exports two metrics, a Gauge and a Counter,
|
||||
// the latter with a label attached to turn it into a (one-dimensional) vector.
|
||||
//
|
||||
// Metrics
|
||||
//
|
||||
// The number of exported identifiers in this package might appear a bit
|
||||
// overwhelming. However, in addition to the basic plumbing shown in the example
|
||||
// above, you only need to understand the different metric types and their
|
||||
// vector versions for basic usage. Furthermore, if you are not concerned with
|
||||
// fine-grained control of when and how to register metrics with the registry,
|
||||
// have a look at the promauto package, which will effectively allow you to
|
||||
// ignore registration altogether in simple cases.
|
||||
//
|
||||
// Above, you have already touched the Counter and the Gauge. There are two more
|
||||
// advanced metric types: the Summary and Histogram. A more thorough description
|
||||
// of those four metric types can be found in the Prometheus docs:
|
||||
// https://prometheus.io/docs/concepts/metric_types/
|
||||
//
|
||||
// A fifth "type" of metric is Untyped. It behaves like a Gauge, but signals the
|
||||
// Prometheus server not to assume anything about its type.
|
||||
//
|
||||
// In addition to the fundamental metric types Gauge, Counter, Summary,
|
||||
// Histogram, and Untyped, a very important part of the Prometheus data model is
|
||||
// the partitioning of samples along dimensions called labels, which results in
|
||||
// metric vectors. The fundamental types are GaugeVec, CounterVec, SummaryVec,
|
||||
// HistogramVec, and UntypedVec.
|
||||
//
|
||||
// While only the fundamental metric types implement the Metric interface, both
|
||||
// the metrics and their vector versions implement the Collector interface. A
|
||||
// Collector manages the collection of a number of Metrics, but for convenience,
|
||||
// a Metric can also “collect itself”. Note that Gauge, Counter, Summary,
|
||||
// Histogram, and Untyped are interfaces themselves while GaugeVec, CounterVec,
|
||||
// SummaryVec, HistogramVec, and UntypedVec are not.
|
||||
//
|
||||
// To create instances of Metrics and their vector versions, you need a suitable
|
||||
// …Opts struct, i.e. GaugeOpts, CounterOpts, SummaryOpts, HistogramOpts, or
|
||||
// UntypedOpts.
|
||||
//
|
||||
// Custom Collectors and constant Metrics
|
||||
//
|
||||
// While you could create your own implementations of Metric, most likely you
|
||||
// will only ever implement the Collector interface on your own. At a first
|
||||
// glance, a custom Collector seems handy to bundle Metrics for common
|
||||
// registration (with the prime example of the different metric vectors above,
|
||||
// which bundle all the metrics of the same name but with different labels).
|
||||
//
|
||||
// There is a more involved use case, too: If you already have metrics
|
||||
// available, created outside of the Prometheus context, you don't need the
|
||||
// interface of the various Metric types. You essentially want to mirror the
|
||||
// existing numbers into Prometheus Metrics during collection. An own
|
||||
// implementation of the Collector interface is perfect for that. You can create
|
||||
// Metric instances “on the fly” using NewConstMetric, NewConstHistogram, and
|
||||
// NewConstSummary (and their respective Must… versions). That will happen in
|
||||
// the Collect method. The Describe method has to return separate Desc
|
||||
// instances, representative of the “throw-away” metrics to be created later.
|
||||
// NewDesc comes in handy to create those Desc instances. Alternatively, you
|
||||
// could return no Desc at all, which will marke the Collector “unchecked”. No
|
||||
// checks are porformed at registration time, but metric consistency will still
|
||||
// be ensured at scrape time, i.e. any inconsistencies will lead to scrape
|
||||
// errors. Thus, with unchecked Collectors, the responsibility to not collect
|
||||
// metrics that lead to inconsistencies in the total scrape result lies with the
|
||||
// implementer of the Collector. While this is not a desirable state, it is
|
||||
// sometimes necessary. The typical use case is a situatios where the exact
|
||||
// metrics to be returned by a Collector cannot be predicted at registration
|
||||
// time, but the implementer has sufficient knowledge of the whole system to
|
||||
// guarantee metric consistency.
|
||||
//
|
||||
// The Collector example illustrates the use case. You can also look at the
|
||||
// source code of the processCollector (mirroring process metrics), the
|
||||
// goCollector (mirroring Go metrics), or the expvarCollector (mirroring expvar
|
||||
// metrics) as examples that are used in this package itself.
|
||||
//
|
||||
// If you just need to call a function to get a single float value to collect as
|
||||
// a metric, GaugeFunc, CounterFunc, or UntypedFunc might be interesting
|
||||
// shortcuts.
|
||||
//
|
||||
// Advanced Uses of the Registry
|
||||
//
|
||||
// While MustRegister is the by far most common way of registering a Collector,
|
||||
// sometimes you might want to handle the errors the registration might cause.
|
||||
// As suggested by the name, MustRegister panics if an error occurs. With the
|
||||
// Register function, the error is returned and can be handled.
|
||||
//
|
||||
// An error is returned if the registered Collector is incompatible or
|
||||
// inconsistent with already registered metrics. The registry aims for
|
||||
// consistency of the collected metrics according to the Prometheus data model.
|
||||
// Inconsistencies are ideally detected at registration time, not at collect
|
||||
// time. The former will usually be detected at start-up time of a program,
|
||||
// while the latter will only happen at scrape time, possibly not even on the
|
||||
// first scrape if the inconsistency only becomes relevant later. That is the
|
||||
// main reason why a Collector and a Metric have to describe themselves to the
|
||||
// registry.
|
||||
//
|
||||
// So far, everything we did operated on the so-called default registry, as it
|
||||
// can be found in the global DefaultRegisterer variable. With NewRegistry, you
|
||||
// can create a custom registry, or you can even implement the Registerer or
|
||||
// Gatherer interfaces yourself. The methods Register and Unregister work in the
|
||||
// same way on a custom registry as the global functions Register and Unregister
|
||||
// on the default registry.
|
||||
//
|
||||
// There are a number of uses for custom registries: You can use registries with
|
||||
// special properties, see NewPedanticRegistry. You can avoid global state, as
|
||||
// it is imposed by the DefaultRegisterer. You can use multiple registries at
|
||||
// the same time to expose different metrics in different ways. You can use
|
||||
// separate registries for testing purposes.
|
||||
//
|
||||
// Also note that the DefaultRegisterer comes registered with a Collector for Go
|
||||
// runtime metrics (via NewGoCollector) and a Collector for process metrics (via
|
||||
// NewProcessCollector). With a custom registry, you are in control and decide
|
||||
// yourself about the Collectors to register.
|
||||
//
|
||||
// HTTP Exposition
|
||||
//
|
||||
// The Registry implements the Gatherer interface. The caller of the Gather
|
||||
// method can then expose the gathered metrics in some way. Usually, the metrics
|
||||
// are served via HTTP on the /metrics endpoint. That's happening in the example
|
||||
// above. The tools to expose metrics via HTTP are in the promhttp sub-package.
|
||||
// (The top-level functions in the prometheus package are deprecated.)
|
||||
//
|
||||
// Pushing to the Pushgateway
|
||||
//
|
||||
// Function for pushing to the Pushgateway can be found in the push sub-package.
|
||||
//
|
||||
// Graphite Bridge
|
||||
//
|
||||
// Functions and examples to push metrics from a Gatherer to Graphite can be
|
||||
// found in the graphite sub-package.
|
||||
//
|
||||
// Other Means of Exposition
|
||||
//
|
||||
// More ways of exposing metrics can easily be added by following the approaches
|
||||
// of the existing implementations.
|
||||
package prometheus
|
||||
119
watchdog/vendor/github.com/prometheus/client_golang/prometheus/expvar_collector.go
generated
vendored
119
watchdog/vendor/github.com/prometheus/client_golang/prometheus/expvar_collector.go
generated
vendored
@ -1,119 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"expvar"
|
||||
)
|
||||
|
||||
type expvarCollector struct {
|
||||
exports map[string]*Desc
|
||||
}
|
||||
|
||||
// NewExpvarCollector returns a newly allocated expvar Collector that still has
|
||||
// to be registered with a Prometheus registry.
|
||||
//
|
||||
// An expvar Collector collects metrics from the expvar interface. It provides a
|
||||
// quick way to expose numeric values that are already exported via expvar as
|
||||
// Prometheus metrics. Note that the data models of expvar and Prometheus are
|
||||
// fundamentally different, and that the expvar Collector is inherently slower
|
||||
// than native Prometheus metrics. Thus, the expvar Collector is probably great
|
||||
// for experiments and prototying, but you should seriously consider a more
|
||||
// direct implementation of Prometheus metrics for monitoring production
|
||||
// systems.
|
||||
//
|
||||
// The exports map has the following meaning:
|
||||
//
|
||||
// The keys in the map correspond to expvar keys, i.e. for every expvar key you
|
||||
// want to export as Prometheus metric, you need an entry in the exports
|
||||
// map. The descriptor mapped to each key describes how to export the expvar
|
||||
// value. It defines the name and the help string of the Prometheus metric
|
||||
// proxying the expvar value. The type will always be Untyped.
|
||||
//
|
||||
// For descriptors without variable labels, the expvar value must be a number or
|
||||
// a bool. The number is then directly exported as the Prometheus sample
|
||||
// value. (For a bool, 'false' translates to 0 and 'true' to 1). Expvar values
|
||||
// that are not numbers or bools are silently ignored.
|
||||
//
|
||||
// If the descriptor has one variable label, the expvar value must be an expvar
|
||||
// map. The keys in the expvar map become the various values of the one
|
||||
// Prometheus label. The values in the expvar map must be numbers or bools again
|
||||
// as above.
|
||||
//
|
||||
// For descriptors with more than one variable label, the expvar must be a
|
||||
// nested expvar map, i.e. where the values of the topmost map are maps again
|
||||
// etc. until a depth is reached that corresponds to the number of labels. The
|
||||
// leaves of that structure must be numbers or bools as above to serve as the
|
||||
// sample values.
|
||||
//
|
||||
// Anything that does not fit into the scheme above is silently ignored.
|
||||
func NewExpvarCollector(exports map[string]*Desc) Collector {
|
||||
return &expvarCollector{
|
||||
exports: exports,
|
||||
}
|
||||
}
|
||||
|
||||
// Describe implements Collector.
|
||||
func (e *expvarCollector) Describe(ch chan<- *Desc) {
|
||||
for _, desc := range e.exports {
|
||||
ch <- desc
|
||||
}
|
||||
}
|
||||
|
||||
// Collect implements Collector.
|
||||
func (e *expvarCollector) Collect(ch chan<- Metric) {
|
||||
for name, desc := range e.exports {
|
||||
var m Metric
|
||||
expVar := expvar.Get(name)
|
||||
if expVar == nil {
|
||||
continue
|
||||
}
|
||||
var v interface{}
|
||||
labels := make([]string, len(desc.variableLabels))
|
||||
if err := json.Unmarshal([]byte(expVar.String()), &v); err != nil {
|
||||
ch <- NewInvalidMetric(desc, err)
|
||||
continue
|
||||
}
|
||||
var processValue func(v interface{}, i int)
|
||||
processValue = func(v interface{}, i int) {
|
||||
if i >= len(labels) {
|
||||
copiedLabels := append(make([]string, 0, len(labels)), labels...)
|
||||
switch v := v.(type) {
|
||||
case float64:
|
||||
m = MustNewConstMetric(desc, UntypedValue, v, copiedLabels...)
|
||||
case bool:
|
||||
if v {
|
||||
m = MustNewConstMetric(desc, UntypedValue, 1, copiedLabels...)
|
||||
} else {
|
||||
m = MustNewConstMetric(desc, UntypedValue, 0, copiedLabels...)
|
||||
}
|
||||
default:
|
||||
return
|
||||
}
|
||||
ch <- m
|
||||
return
|
||||
}
|
||||
vm, ok := v.(map[string]interface{})
|
||||
if !ok {
|
||||
return
|
||||
}
|
||||
for lv, val := range vm {
|
||||
labels[i] = lv
|
||||
processValue(val, i+1)
|
||||
}
|
||||
}
|
||||
processValue(v, 0)
|
||||
}
|
||||
}
|
||||
42
watchdog/vendor/github.com/prometheus/client_golang/prometheus/fnv.go
generated
vendored
42
watchdog/vendor/github.com/prometheus/client_golang/prometheus/fnv.go
generated
vendored
@ -1,42 +0,0 @@
|
||||
// Copyright 2018 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
// Inline and byte-free variant of hash/fnv's fnv64a.
|
||||
|
||||
const (
|
||||
offset64 = 14695981039346656037
|
||||
prime64 = 1099511628211
|
||||
)
|
||||
|
||||
// hashNew initializies a new fnv64a hash value.
|
||||
func hashNew() uint64 {
|
||||
return offset64
|
||||
}
|
||||
|
||||
// hashAdd adds a string to a fnv64a hash value, returning the updated hash.
|
||||
func hashAdd(h uint64, s string) uint64 {
|
||||
for i := 0; i < len(s); i++ {
|
||||
h ^= uint64(s[i])
|
||||
h *= prime64
|
||||
}
|
||||
return h
|
||||
}
|
||||
|
||||
// hashAddByte adds a byte to a fnv64a hash value, returning the updated hash.
|
||||
func hashAddByte(h uint64, b byte) uint64 {
|
||||
h ^= uint64(b)
|
||||
h *= prime64
|
||||
return h
|
||||
}
|
||||
286
watchdog/vendor/github.com/prometheus/client_golang/prometheus/gauge.go
generated
vendored
286
watchdog/vendor/github.com/prometheus/client_golang/prometheus/gauge.go
generated
vendored
@ -1,286 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"math"
|
||||
"sync/atomic"
|
||||
"time"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
)
|
||||
|
||||
// Gauge is a Metric that represents a single numerical value that can
|
||||
// arbitrarily go up and down.
|
||||
//
|
||||
// A Gauge is typically used for measured values like temperatures or current
|
||||
// memory usage, but also "counts" that can go up and down, like the number of
|
||||
// running goroutines.
|
||||
//
|
||||
// To create Gauge instances, use NewGauge.
|
||||
type Gauge interface {
|
||||
Metric
|
||||
Collector
|
||||
|
||||
// Set sets the Gauge to an arbitrary value.
|
||||
Set(float64)
|
||||
// Inc increments the Gauge by 1. Use Add to increment it by arbitrary
|
||||
// values.
|
||||
Inc()
|
||||
// Dec decrements the Gauge by 1. Use Sub to decrement it by arbitrary
|
||||
// values.
|
||||
Dec()
|
||||
// Add adds the given value to the Gauge. (The value can be negative,
|
||||
// resulting in a decrease of the Gauge.)
|
||||
Add(float64)
|
||||
// Sub subtracts the given value from the Gauge. (The value can be
|
||||
// negative, resulting in an increase of the Gauge.)
|
||||
Sub(float64)
|
||||
|
||||
// SetToCurrentTime sets the Gauge to the current Unix time in seconds.
|
||||
SetToCurrentTime()
|
||||
}
|
||||
|
||||
// GaugeOpts is an alias for Opts. See there for doc comments.
|
||||
type GaugeOpts Opts
|
||||
|
||||
// NewGauge creates a new Gauge based on the provided GaugeOpts.
|
||||
//
|
||||
// The returned implementation is optimized for a fast Set method. If you have a
|
||||
// choice for managing the value of a Gauge via Set vs. Inc/Dec/Add/Sub, pick
|
||||
// the former. For example, the Inc method of the returned Gauge is slower than
|
||||
// the Inc method of a Counter returned by NewCounter. This matches the typical
|
||||
// scenarios for Gauges and Counters, where the former tends to be Set-heavy and
|
||||
// the latter Inc-heavy.
|
||||
func NewGauge(opts GaugeOpts) Gauge {
|
||||
desc := NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
nil,
|
||||
opts.ConstLabels,
|
||||
)
|
||||
result := &gauge{desc: desc, labelPairs: desc.constLabelPairs}
|
||||
result.init(result) // Init self-collection.
|
||||
return result
|
||||
}
|
||||
|
||||
type gauge struct {
|
||||
// valBits contains the bits of the represented float64 value. It has
|
||||
// to go first in the struct to guarantee alignment for atomic
|
||||
// operations. http://golang.org/pkg/sync/atomic/#pkg-note-BUG
|
||||
valBits uint64
|
||||
|
||||
selfCollector
|
||||
|
||||
desc *Desc
|
||||
labelPairs []*dto.LabelPair
|
||||
}
|
||||
|
||||
func (g *gauge) Desc() *Desc {
|
||||
return g.desc
|
||||
}
|
||||
|
||||
func (g *gauge) Set(val float64) {
|
||||
atomic.StoreUint64(&g.valBits, math.Float64bits(val))
|
||||
}
|
||||
|
||||
func (g *gauge) SetToCurrentTime() {
|
||||
g.Set(float64(time.Now().UnixNano()) / 1e9)
|
||||
}
|
||||
|
||||
func (g *gauge) Inc() {
|
||||
g.Add(1)
|
||||
}
|
||||
|
||||
func (g *gauge) Dec() {
|
||||
g.Add(-1)
|
||||
}
|
||||
|
||||
func (g *gauge) Add(val float64) {
|
||||
for {
|
||||
oldBits := atomic.LoadUint64(&g.valBits)
|
||||
newBits := math.Float64bits(math.Float64frombits(oldBits) + val)
|
||||
if atomic.CompareAndSwapUint64(&g.valBits, oldBits, newBits) {
|
||||
return
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (g *gauge) Sub(val float64) {
|
||||
g.Add(val * -1)
|
||||
}
|
||||
|
||||
func (g *gauge) Write(out *dto.Metric) error {
|
||||
val := math.Float64frombits(atomic.LoadUint64(&g.valBits))
|
||||
return populateMetric(GaugeValue, val, g.labelPairs, out)
|
||||
}
|
||||
|
||||
// GaugeVec is a Collector that bundles a set of Gauges that all share the same
|
||||
// Desc, but have different values for their variable labels. This is used if
|
||||
// you want to count the same thing partitioned by various dimensions
|
||||
// (e.g. number of operations queued, partitioned by user and operation
|
||||
// type). Create instances with NewGaugeVec.
|
||||
type GaugeVec struct {
|
||||
*metricVec
|
||||
}
|
||||
|
||||
// NewGaugeVec creates a new GaugeVec based on the provided GaugeOpts and
|
||||
// partitioned by the given label names.
|
||||
func NewGaugeVec(opts GaugeOpts, labelNames []string) *GaugeVec {
|
||||
desc := NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
labelNames,
|
||||
opts.ConstLabels,
|
||||
)
|
||||
return &GaugeVec{
|
||||
metricVec: newMetricVec(desc, func(lvs ...string) Metric {
|
||||
if len(lvs) != len(desc.variableLabels) {
|
||||
panic(makeInconsistentCardinalityError(desc.fqName, desc.variableLabels, lvs))
|
||||
}
|
||||
result := &gauge{desc: desc, labelPairs: makeLabelPairs(desc, lvs)}
|
||||
result.init(result) // Init self-collection.
|
||||
return result
|
||||
}),
|
||||
}
|
||||
}
|
||||
|
||||
// GetMetricWithLabelValues returns the Gauge for the given slice of label
|
||||
// values (same order as the VariableLabels in Desc). If that combination of
|
||||
// label values is accessed for the first time, a new Gauge is created.
|
||||
//
|
||||
// It is possible to call this method without using the returned Gauge to only
|
||||
// create the new Gauge but leave it at its starting value 0. See also the
|
||||
// SummaryVec example.
|
||||
//
|
||||
// Keeping the Gauge for later use is possible (and should be considered if
|
||||
// performance is critical), but keep in mind that Reset, DeleteLabelValues and
|
||||
// Delete can be used to delete the Gauge from the GaugeVec. In that case, the
|
||||
// Gauge will still exist, but it will not be exported anymore, even if a
|
||||
// Gauge with the same label values is created later. See also the CounterVec
|
||||
// example.
|
||||
//
|
||||
// An error is returned if the number of label values is not the same as the
|
||||
// number of VariableLabels in Desc (minus any curried labels).
|
||||
//
|
||||
// Note that for more than one label value, this method is prone to mistakes
|
||||
// caused by an incorrect order of arguments. Consider GetMetricWith(Labels) as
|
||||
// an alternative to avoid that type of mistake. For higher label numbers, the
|
||||
// latter has a much more readable (albeit more verbose) syntax, but it comes
|
||||
// with a performance overhead (for creating and processing the Labels map).
|
||||
func (v *GaugeVec) GetMetricWithLabelValues(lvs ...string) (Gauge, error) {
|
||||
metric, err := v.metricVec.getMetricWithLabelValues(lvs...)
|
||||
if metric != nil {
|
||||
return metric.(Gauge), err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// GetMetricWith returns the Gauge for the given Labels map (the label names
|
||||
// must match those of the VariableLabels in Desc). If that label map is
|
||||
// accessed for the first time, a new Gauge is created. Implications of
|
||||
// creating a Gauge without using it and keeping the Gauge for later use are
|
||||
// the same as for GetMetricWithLabelValues.
|
||||
//
|
||||
// An error is returned if the number and names of the Labels are inconsistent
|
||||
// with those of the VariableLabels in Desc (minus any curried labels).
|
||||
//
|
||||
// This method is used for the same purpose as
|
||||
// GetMetricWithLabelValues(...string). See there for pros and cons of the two
|
||||
// methods.
|
||||
func (v *GaugeVec) GetMetricWith(labels Labels) (Gauge, error) {
|
||||
metric, err := v.metricVec.getMetricWith(labels)
|
||||
if metric != nil {
|
||||
return metric.(Gauge), err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// WithLabelValues works as GetMetricWithLabelValues, but panics where
|
||||
// GetMetricWithLabelValues would have returned an error. Not returning an
|
||||
// error allows shortcuts like
|
||||
// myVec.WithLabelValues("404", "GET").Add(42)
|
||||
func (v *GaugeVec) WithLabelValues(lvs ...string) Gauge {
|
||||
g, err := v.GetMetricWithLabelValues(lvs...)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return g
|
||||
}
|
||||
|
||||
// With works as GetMetricWith, but panics where GetMetricWithLabels would have
|
||||
// returned an error. Not returning an error allows shortcuts like
|
||||
// myVec.With(prometheus.Labels{"code": "404", "method": "GET"}).Add(42)
|
||||
func (v *GaugeVec) With(labels Labels) Gauge {
|
||||
g, err := v.GetMetricWith(labels)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return g
|
||||
}
|
||||
|
||||
// CurryWith returns a vector curried with the provided labels, i.e. the
|
||||
// returned vector has those labels pre-set for all labeled operations performed
|
||||
// on it. The cardinality of the curried vector is reduced accordingly. The
|
||||
// order of the remaining labels stays the same (just with the curried labels
|
||||
// taken out of the sequence – which is relevant for the
|
||||
// (GetMetric)WithLabelValues methods). It is possible to curry a curried
|
||||
// vector, but only with labels not yet used for currying before.
|
||||
//
|
||||
// The metrics contained in the GaugeVec are shared between the curried and
|
||||
// uncurried vectors. They are just accessed differently. Curried and uncurried
|
||||
// vectors behave identically in terms of collection. Only one must be
|
||||
// registered with a given registry (usually the uncurried version). The Reset
|
||||
// method deletes all metrics, even if called on a curried vector.
|
||||
func (v *GaugeVec) CurryWith(labels Labels) (*GaugeVec, error) {
|
||||
vec, err := v.curryWith(labels)
|
||||
if vec != nil {
|
||||
return &GaugeVec{vec}, err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// MustCurryWith works as CurryWith but panics where CurryWith would have
|
||||
// returned an error.
|
||||
func (v *GaugeVec) MustCurryWith(labels Labels) *GaugeVec {
|
||||
vec, err := v.CurryWith(labels)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return vec
|
||||
}
|
||||
|
||||
// GaugeFunc is a Gauge whose value is determined at collect time by calling a
|
||||
// provided function.
|
||||
//
|
||||
// To create GaugeFunc instances, use NewGaugeFunc.
|
||||
type GaugeFunc interface {
|
||||
Metric
|
||||
Collector
|
||||
}
|
||||
|
||||
// NewGaugeFunc creates a new GaugeFunc based on the provided GaugeOpts. The
|
||||
// value reported is determined by calling the given function from within the
|
||||
// Write method. Take into account that metric collection may happen
|
||||
// concurrently. If that results in concurrent calls to Write, like in the case
|
||||
// where a GaugeFunc is directly registered with Prometheus, the provided
|
||||
// function must be concurrency-safe.
|
||||
func NewGaugeFunc(opts GaugeOpts, function func() float64) GaugeFunc {
|
||||
return newValueFunc(NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
nil,
|
||||
opts.ConstLabels,
|
||||
), GaugeValue, function)
|
||||
}
|
||||
301
watchdog/vendor/github.com/prometheus/client_golang/prometheus/go_collector.go
generated
vendored
301
watchdog/vendor/github.com/prometheus/client_golang/prometheus/go_collector.go
generated
vendored
@ -1,301 +0,0 @@
|
||||
// Copyright 2018 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"runtime"
|
||||
"runtime/debug"
|
||||
"time"
|
||||
)
|
||||
|
||||
type goCollector struct {
|
||||
goroutinesDesc *Desc
|
||||
threadsDesc *Desc
|
||||
gcDesc *Desc
|
||||
goInfoDesc *Desc
|
||||
|
||||
// metrics to describe and collect
|
||||
metrics memStatsMetrics
|
||||
}
|
||||
|
||||
// NewGoCollector returns a collector which exports metrics about the current Go
|
||||
// process. This includes memory stats. To collect those, runtime.ReadMemStats
|
||||
// is called. This causes a stop-the-world, which is very short with Go1.9+
|
||||
// (~25µs). However, with older Go versions, the stop-the-world duration depends
|
||||
// on the heap size and can be quite significant (~1.7 ms/GiB as per
|
||||
// https://go-review.googlesource.com/c/go/+/34937).
|
||||
func NewGoCollector() Collector {
|
||||
return &goCollector{
|
||||
goroutinesDesc: NewDesc(
|
||||
"go_goroutines",
|
||||
"Number of goroutines that currently exist.",
|
||||
nil, nil),
|
||||
threadsDesc: NewDesc(
|
||||
"go_threads",
|
||||
"Number of OS threads created.",
|
||||
nil, nil),
|
||||
gcDesc: NewDesc(
|
||||
"go_gc_duration_seconds",
|
||||
"A summary of the GC invocation durations.",
|
||||
nil, nil),
|
||||
goInfoDesc: NewDesc(
|
||||
"go_info",
|
||||
"Information about the Go environment.",
|
||||
nil, Labels{"version": runtime.Version()}),
|
||||
metrics: memStatsMetrics{
|
||||
{
|
||||
desc: NewDesc(
|
||||
memstatNamespace("alloc_bytes"),
|
||||
"Number of bytes allocated and still in use.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.Alloc) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("alloc_bytes_total"),
|
||||
"Total number of bytes allocated, even if freed.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.TotalAlloc) },
|
||||
valType: CounterValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("sys_bytes"),
|
||||
"Number of bytes obtained from system.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.Sys) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("lookups_total"),
|
||||
"Total number of pointer lookups.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.Lookups) },
|
||||
valType: CounterValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("mallocs_total"),
|
||||
"Total number of mallocs.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.Mallocs) },
|
||||
valType: CounterValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("frees_total"),
|
||||
"Total number of frees.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.Frees) },
|
||||
valType: CounterValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("heap_alloc_bytes"),
|
||||
"Number of heap bytes allocated and still in use.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.HeapAlloc) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("heap_sys_bytes"),
|
||||
"Number of heap bytes obtained from system.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.HeapSys) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("heap_idle_bytes"),
|
||||
"Number of heap bytes waiting to be used.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.HeapIdle) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("heap_inuse_bytes"),
|
||||
"Number of heap bytes that are in use.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.HeapInuse) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("heap_released_bytes"),
|
||||
"Number of heap bytes released to OS.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.HeapReleased) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("heap_objects"),
|
||||
"Number of allocated objects.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.HeapObjects) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("stack_inuse_bytes"),
|
||||
"Number of bytes in use by the stack allocator.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.StackInuse) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("stack_sys_bytes"),
|
||||
"Number of bytes obtained from system for stack allocator.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.StackSys) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("mspan_inuse_bytes"),
|
||||
"Number of bytes in use by mspan structures.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.MSpanInuse) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("mspan_sys_bytes"),
|
||||
"Number of bytes used for mspan structures obtained from system.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.MSpanSys) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("mcache_inuse_bytes"),
|
||||
"Number of bytes in use by mcache structures.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.MCacheInuse) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("mcache_sys_bytes"),
|
||||
"Number of bytes used for mcache structures obtained from system.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.MCacheSys) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("buck_hash_sys_bytes"),
|
||||
"Number of bytes used by the profiling bucket hash table.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.BuckHashSys) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("gc_sys_bytes"),
|
||||
"Number of bytes used for garbage collection system metadata.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.GCSys) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("other_sys_bytes"),
|
||||
"Number of bytes used for other system allocations.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.OtherSys) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("next_gc_bytes"),
|
||||
"Number of heap bytes when next garbage collection will take place.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.NextGC) },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("last_gc_time_seconds"),
|
||||
"Number of seconds since 1970 of last garbage collection.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return float64(ms.LastGC) / 1e9 },
|
||||
valType: GaugeValue,
|
||||
}, {
|
||||
desc: NewDesc(
|
||||
memstatNamespace("gc_cpu_fraction"),
|
||||
"The fraction of this program's available CPU time used by the GC since the program started.",
|
||||
nil, nil,
|
||||
),
|
||||
eval: func(ms *runtime.MemStats) float64 { return ms.GCCPUFraction },
|
||||
valType: GaugeValue,
|
||||
},
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
func memstatNamespace(s string) string {
|
||||
return fmt.Sprintf("go_memstats_%s", s)
|
||||
}
|
||||
|
||||
// Describe returns all descriptions of the collector.
|
||||
func (c *goCollector) Describe(ch chan<- *Desc) {
|
||||
ch <- c.goroutinesDesc
|
||||
ch <- c.threadsDesc
|
||||
ch <- c.gcDesc
|
||||
ch <- c.goInfoDesc
|
||||
for _, i := range c.metrics {
|
||||
ch <- i.desc
|
||||
}
|
||||
}
|
||||
|
||||
// Collect returns the current state of all metrics of the collector.
|
||||
func (c *goCollector) Collect(ch chan<- Metric) {
|
||||
ch <- MustNewConstMetric(c.goroutinesDesc, GaugeValue, float64(runtime.NumGoroutine()))
|
||||
n, _ := runtime.ThreadCreateProfile(nil)
|
||||
ch <- MustNewConstMetric(c.threadsDesc, GaugeValue, float64(n))
|
||||
|
||||
var stats debug.GCStats
|
||||
stats.PauseQuantiles = make([]time.Duration, 5)
|
||||
debug.ReadGCStats(&stats)
|
||||
|
||||
quantiles := make(map[float64]float64)
|
||||
for idx, pq := range stats.PauseQuantiles[1:] {
|
||||
quantiles[float64(idx+1)/float64(len(stats.PauseQuantiles)-1)] = pq.Seconds()
|
||||
}
|
||||
quantiles[0.0] = stats.PauseQuantiles[0].Seconds()
|
||||
ch <- MustNewConstSummary(c.gcDesc, uint64(stats.NumGC), stats.PauseTotal.Seconds(), quantiles)
|
||||
|
||||
ch <- MustNewConstMetric(c.goInfoDesc, GaugeValue, 1)
|
||||
|
||||
ms := &runtime.MemStats{}
|
||||
runtime.ReadMemStats(ms)
|
||||
for _, i := range c.metrics {
|
||||
ch <- MustNewConstMetric(i.desc, i.valType, i.eval(ms))
|
||||
}
|
||||
}
|
||||
|
||||
// memStatsMetrics provide description, value, and value type for memstat metrics.
|
||||
type memStatsMetrics []struct {
|
||||
desc *Desc
|
||||
eval func(*runtime.MemStats) float64
|
||||
valType ValueType
|
||||
}
|
||||
614
watchdog/vendor/github.com/prometheus/client_golang/prometheus/histogram.go
generated
vendored
614
watchdog/vendor/github.com/prometheus/client_golang/prometheus/histogram.go
generated
vendored
@ -1,614 +0,0 @@
|
||||
// Copyright 2015 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"math"
|
||||
"runtime"
|
||||
"sort"
|
||||
"sync"
|
||||
"sync/atomic"
|
||||
|
||||
"github.com/golang/protobuf/proto"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
)
|
||||
|
||||
// A Histogram counts individual observations from an event or sample stream in
|
||||
// configurable buckets. Similar to a summary, it also provides a sum of
|
||||
// observations and an observation count.
|
||||
//
|
||||
// On the Prometheus server, quantiles can be calculated from a Histogram using
|
||||
// the histogram_quantile function in the query language.
|
||||
//
|
||||
// Note that Histograms, in contrast to Summaries, can be aggregated with the
|
||||
// Prometheus query language (see the documentation for detailed
|
||||
// procedures). However, Histograms require the user to pre-define suitable
|
||||
// buckets, and they are in general less accurate. The Observe method of a
|
||||
// Histogram has a very low performance overhead in comparison with the Observe
|
||||
// method of a Summary.
|
||||
//
|
||||
// To create Histogram instances, use NewHistogram.
|
||||
type Histogram interface {
|
||||
Metric
|
||||
Collector
|
||||
|
||||
// Observe adds a single observation to the histogram.
|
||||
Observe(float64)
|
||||
}
|
||||
|
||||
// bucketLabel is used for the label that defines the upper bound of a
|
||||
// bucket of a histogram ("le" -> "less or equal").
|
||||
const bucketLabel = "le"
|
||||
|
||||
// DefBuckets are the default Histogram buckets. The default buckets are
|
||||
// tailored to broadly measure the response time (in seconds) of a network
|
||||
// service. Most likely, however, you will be required to define buckets
|
||||
// customized to your use case.
|
||||
var (
|
||||
DefBuckets = []float64{.005, .01, .025, .05, .1, .25, .5, 1, 2.5, 5, 10}
|
||||
|
||||
errBucketLabelNotAllowed = fmt.Errorf(
|
||||
"%q is not allowed as label name in histograms", bucketLabel,
|
||||
)
|
||||
)
|
||||
|
||||
// LinearBuckets creates 'count' buckets, each 'width' wide, where the lowest
|
||||
// bucket has an upper bound of 'start'. The final +Inf bucket is not counted
|
||||
// and not included in the returned slice. The returned slice is meant to be
|
||||
// used for the Buckets field of HistogramOpts.
|
||||
//
|
||||
// The function panics if 'count' is zero or negative.
|
||||
func LinearBuckets(start, width float64, count int) []float64 {
|
||||
if count < 1 {
|
||||
panic("LinearBuckets needs a positive count")
|
||||
}
|
||||
buckets := make([]float64, count)
|
||||
for i := range buckets {
|
||||
buckets[i] = start
|
||||
start += width
|
||||
}
|
||||
return buckets
|
||||
}
|
||||
|
||||
// ExponentialBuckets creates 'count' buckets, where the lowest bucket has an
|
||||
// upper bound of 'start' and each following bucket's upper bound is 'factor'
|
||||
// times the previous bucket's upper bound. The final +Inf bucket is not counted
|
||||
// and not included in the returned slice. The returned slice is meant to be
|
||||
// used for the Buckets field of HistogramOpts.
|
||||
//
|
||||
// The function panics if 'count' is 0 or negative, if 'start' is 0 or negative,
|
||||
// or if 'factor' is less than or equal 1.
|
||||
func ExponentialBuckets(start, factor float64, count int) []float64 {
|
||||
if count < 1 {
|
||||
panic("ExponentialBuckets needs a positive count")
|
||||
}
|
||||
if start <= 0 {
|
||||
panic("ExponentialBuckets needs a positive start value")
|
||||
}
|
||||
if factor <= 1 {
|
||||
panic("ExponentialBuckets needs a factor greater than 1")
|
||||
}
|
||||
buckets := make([]float64, count)
|
||||
for i := range buckets {
|
||||
buckets[i] = start
|
||||
start *= factor
|
||||
}
|
||||
return buckets
|
||||
}
|
||||
|
||||
// HistogramOpts bundles the options for creating a Histogram metric. It is
|
||||
// mandatory to set Name to a non-empty string. All other fields are optional
|
||||
// and can safely be left at their zero value, although it is strongly
|
||||
// encouraged to set a Help string.
|
||||
type HistogramOpts struct {
|
||||
// Namespace, Subsystem, and Name are components of the fully-qualified
|
||||
// name of the Histogram (created by joining these components with
|
||||
// "_"). Only Name is mandatory, the others merely help structuring the
|
||||
// name. Note that the fully-qualified name of the Histogram must be a
|
||||
// valid Prometheus metric name.
|
||||
Namespace string
|
||||
Subsystem string
|
||||
Name string
|
||||
|
||||
// Help provides information about this Histogram.
|
||||
//
|
||||
// Metrics with the same fully-qualified name must have the same Help
|
||||
// string.
|
||||
Help string
|
||||
|
||||
// ConstLabels are used to attach fixed labels to this metric. Metrics
|
||||
// with the same fully-qualified name must have the same label names in
|
||||
// their ConstLabels.
|
||||
//
|
||||
// ConstLabels are only used rarely. In particular, do not use them to
|
||||
// attach the same labels to all your metrics. Those use cases are
|
||||
// better covered by target labels set by the scraping Prometheus
|
||||
// server, or by one specific metric (e.g. a build_info or a
|
||||
// machine_role metric). See also
|
||||
// https://prometheus.io/docs/instrumenting/writing_exporters/#target-labels,-not-static-scraped-labels
|
||||
ConstLabels Labels
|
||||
|
||||
// Buckets defines the buckets into which observations are counted. Each
|
||||
// element in the slice is the upper inclusive bound of a bucket. The
|
||||
// values must be sorted in strictly increasing order. There is no need
|
||||
// to add a highest bucket with +Inf bound, it will be added
|
||||
// implicitly. The default value is DefBuckets.
|
||||
Buckets []float64
|
||||
}
|
||||
|
||||
// NewHistogram creates a new Histogram based on the provided HistogramOpts. It
|
||||
// panics if the buckets in HistogramOpts are not in strictly increasing order.
|
||||
func NewHistogram(opts HistogramOpts) Histogram {
|
||||
return newHistogram(
|
||||
NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
nil,
|
||||
opts.ConstLabels,
|
||||
),
|
||||
opts,
|
||||
)
|
||||
}
|
||||
|
||||
func newHistogram(desc *Desc, opts HistogramOpts, labelValues ...string) Histogram {
|
||||
if len(desc.variableLabels) != len(labelValues) {
|
||||
panic(makeInconsistentCardinalityError(desc.fqName, desc.variableLabels, labelValues))
|
||||
}
|
||||
|
||||
for _, n := range desc.variableLabels {
|
||||
if n == bucketLabel {
|
||||
panic(errBucketLabelNotAllowed)
|
||||
}
|
||||
}
|
||||
for _, lp := range desc.constLabelPairs {
|
||||
if lp.GetName() == bucketLabel {
|
||||
panic(errBucketLabelNotAllowed)
|
||||
}
|
||||
}
|
||||
|
||||
if len(opts.Buckets) == 0 {
|
||||
opts.Buckets = DefBuckets
|
||||
}
|
||||
|
||||
h := &histogram{
|
||||
desc: desc,
|
||||
upperBounds: opts.Buckets,
|
||||
labelPairs: makeLabelPairs(desc, labelValues),
|
||||
counts: [2]*histogramCounts{&histogramCounts{}, &histogramCounts{}},
|
||||
}
|
||||
for i, upperBound := range h.upperBounds {
|
||||
if i < len(h.upperBounds)-1 {
|
||||
if upperBound >= h.upperBounds[i+1] {
|
||||
panic(fmt.Errorf(
|
||||
"histogram buckets must be in increasing order: %f >= %f",
|
||||
upperBound, h.upperBounds[i+1],
|
||||
))
|
||||
}
|
||||
} else {
|
||||
if math.IsInf(upperBound, +1) {
|
||||
// The +Inf bucket is implicit. Remove it here.
|
||||
h.upperBounds = h.upperBounds[:i]
|
||||
}
|
||||
}
|
||||
}
|
||||
// Finally we know the final length of h.upperBounds and can make counts
|
||||
// for both states:
|
||||
h.counts[0].buckets = make([]uint64, len(h.upperBounds))
|
||||
h.counts[1].buckets = make([]uint64, len(h.upperBounds))
|
||||
|
||||
h.init(h) // Init self-collection.
|
||||
return h
|
||||
}
|
||||
|
||||
type histogramCounts struct {
|
||||
// sumBits contains the bits of the float64 representing the sum of all
|
||||
// observations. sumBits and count have to go first in the struct to
|
||||
// guarantee alignment for atomic operations.
|
||||
// http://golang.org/pkg/sync/atomic/#pkg-note-BUG
|
||||
sumBits uint64
|
||||
count uint64
|
||||
buckets []uint64
|
||||
}
|
||||
|
||||
type histogram struct {
|
||||
// countAndHotIdx is a complicated one. For lock-free yet atomic
|
||||
// observations, we need to save the total count of observations again,
|
||||
// combined with the index of the currently-hot counts struct, so that
|
||||
// we can perform the operation on both values atomically. The least
|
||||
// significant bit defines the hot counts struct. The remaining 63 bits
|
||||
// represent the total count of observations. This happens under the
|
||||
// assumption that the 63bit count will never overflow. Rationale: An
|
||||
// observations takes about 30ns. Let's assume it could happen in
|
||||
// 10ns. Overflowing the counter will then take at least (2^63)*10ns,
|
||||
// which is about 3000 years.
|
||||
//
|
||||
// This has to be first in the struct for 64bit alignment. See
|
||||
// http://golang.org/pkg/sync/atomic/#pkg-note-BUG
|
||||
countAndHotIdx uint64
|
||||
|
||||
selfCollector
|
||||
desc *Desc
|
||||
writeMtx sync.Mutex // Only used in the Write method.
|
||||
|
||||
upperBounds []float64
|
||||
|
||||
// Two counts, one is "hot" for lock-free observations, the other is
|
||||
// "cold" for writing out a dto.Metric. It has to be an array of
|
||||
// pointers to guarantee 64bit alignment of the histogramCounts, see
|
||||
// http://golang.org/pkg/sync/atomic/#pkg-note-BUG.
|
||||
counts [2]*histogramCounts
|
||||
hotIdx int // Index of currently-hot counts. Only used within Write.
|
||||
|
||||
labelPairs []*dto.LabelPair
|
||||
}
|
||||
|
||||
func (h *histogram) Desc() *Desc {
|
||||
return h.desc
|
||||
}
|
||||
|
||||
func (h *histogram) Observe(v float64) {
|
||||
// TODO(beorn7): For small numbers of buckets (<30), a linear search is
|
||||
// slightly faster than the binary search. If we really care, we could
|
||||
// switch from one search strategy to the other depending on the number
|
||||
// of buckets.
|
||||
//
|
||||
// Microbenchmarks (BenchmarkHistogramNoLabels):
|
||||
// 11 buckets: 38.3 ns/op linear - binary 48.7 ns/op
|
||||
// 100 buckets: 78.1 ns/op linear - binary 54.9 ns/op
|
||||
// 300 buckets: 154 ns/op linear - binary 61.6 ns/op
|
||||
i := sort.SearchFloat64s(h.upperBounds, v)
|
||||
|
||||
// We increment h.countAndHotIdx by 2 so that the counter in the upper
|
||||
// 63 bits gets incremented by 1. At the same time, we get the new value
|
||||
// back, which we can use to find the currently-hot counts.
|
||||
n := atomic.AddUint64(&h.countAndHotIdx, 2)
|
||||
hotCounts := h.counts[n%2]
|
||||
|
||||
if i < len(h.upperBounds) {
|
||||
atomic.AddUint64(&hotCounts.buckets[i], 1)
|
||||
}
|
||||
for {
|
||||
oldBits := atomic.LoadUint64(&hotCounts.sumBits)
|
||||
newBits := math.Float64bits(math.Float64frombits(oldBits) + v)
|
||||
if atomic.CompareAndSwapUint64(&hotCounts.sumBits, oldBits, newBits) {
|
||||
break
|
||||
}
|
||||
}
|
||||
// Increment count last as we take it as a signal that the observation
|
||||
// is complete.
|
||||
atomic.AddUint64(&hotCounts.count, 1)
|
||||
}
|
||||
|
||||
func (h *histogram) Write(out *dto.Metric) error {
|
||||
var (
|
||||
his = &dto.Histogram{}
|
||||
buckets = make([]*dto.Bucket, len(h.upperBounds))
|
||||
hotCounts, coldCounts *histogramCounts
|
||||
count uint64
|
||||
)
|
||||
|
||||
// For simplicity, we mutex the rest of this method. It is not in the
|
||||
// hot path, i.e. Observe is called much more often than Write. The
|
||||
// complication of making Write lock-free isn't worth it.
|
||||
h.writeMtx.Lock()
|
||||
defer h.writeMtx.Unlock()
|
||||
|
||||
// This is a bit arcane, which is why the following spells out this if
|
||||
// clause in English:
|
||||
//
|
||||
// If the currently-hot counts struct is #0, we atomically increment
|
||||
// h.countAndHotIdx by 1 so that from now on Observe will use the counts
|
||||
// struct #1. Furthermore, the atomic increment gives us the new value,
|
||||
// which, in its most significant 63 bits, tells us the count of
|
||||
// observations done so far up to and including currently ongoing
|
||||
// observations still using the counts struct just changed from hot to
|
||||
// cold. To have a normal uint64 for the count, we bitshift by 1 and
|
||||
// save the result in count. We also set h.hotIdx to 1 for the next
|
||||
// Write call, and we will refer to counts #1 as hotCounts and to counts
|
||||
// #0 as coldCounts.
|
||||
//
|
||||
// If the currently-hot counts struct is #1, we do the corresponding
|
||||
// things the other way round. We have to _decrement_ h.countAndHotIdx
|
||||
// (which is a bit arcane in itself, as we have to express -1 with an
|
||||
// unsigned int...).
|
||||
if h.hotIdx == 0 {
|
||||
count = atomic.AddUint64(&h.countAndHotIdx, 1) >> 1
|
||||
h.hotIdx = 1
|
||||
hotCounts = h.counts[1]
|
||||
coldCounts = h.counts[0]
|
||||
} else {
|
||||
count = atomic.AddUint64(&h.countAndHotIdx, ^uint64(0)) >> 1 // Decrement.
|
||||
h.hotIdx = 0
|
||||
hotCounts = h.counts[0]
|
||||
coldCounts = h.counts[1]
|
||||
}
|
||||
|
||||
// Now we have to wait for the now-declared-cold counts to actually cool
|
||||
// down, i.e. wait for all observations still using it to finish. That's
|
||||
// the case once the count in the cold counts struct is the same as the
|
||||
// one atomically retrieved from the upper 63bits of h.countAndHotIdx.
|
||||
for {
|
||||
if count == atomic.LoadUint64(&coldCounts.count) {
|
||||
break
|
||||
}
|
||||
runtime.Gosched() // Let observations get work done.
|
||||
}
|
||||
|
||||
his.SampleCount = proto.Uint64(count)
|
||||
his.SampleSum = proto.Float64(math.Float64frombits(atomic.LoadUint64(&coldCounts.sumBits)))
|
||||
var cumCount uint64
|
||||
for i, upperBound := range h.upperBounds {
|
||||
cumCount += atomic.LoadUint64(&coldCounts.buckets[i])
|
||||
buckets[i] = &dto.Bucket{
|
||||
CumulativeCount: proto.Uint64(cumCount),
|
||||
UpperBound: proto.Float64(upperBound),
|
||||
}
|
||||
}
|
||||
|
||||
his.Bucket = buckets
|
||||
out.Histogram = his
|
||||
out.Label = h.labelPairs
|
||||
|
||||
// Finally add all the cold counts to the new hot counts and reset the cold counts.
|
||||
atomic.AddUint64(&hotCounts.count, count)
|
||||
atomic.StoreUint64(&coldCounts.count, 0)
|
||||
for {
|
||||
oldBits := atomic.LoadUint64(&hotCounts.sumBits)
|
||||
newBits := math.Float64bits(math.Float64frombits(oldBits) + his.GetSampleSum())
|
||||
if atomic.CompareAndSwapUint64(&hotCounts.sumBits, oldBits, newBits) {
|
||||
atomic.StoreUint64(&coldCounts.sumBits, 0)
|
||||
break
|
||||
}
|
||||
}
|
||||
for i := range h.upperBounds {
|
||||
atomic.AddUint64(&hotCounts.buckets[i], atomic.LoadUint64(&coldCounts.buckets[i]))
|
||||
atomic.StoreUint64(&coldCounts.buckets[i], 0)
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// HistogramVec is a Collector that bundles a set of Histograms that all share the
|
||||
// same Desc, but have different values for their variable labels. This is used
|
||||
// if you want to count the same thing partitioned by various dimensions
|
||||
// (e.g. HTTP request latencies, partitioned by status code and method). Create
|
||||
// instances with NewHistogramVec.
|
||||
type HistogramVec struct {
|
||||
*metricVec
|
||||
}
|
||||
|
||||
// NewHistogramVec creates a new HistogramVec based on the provided HistogramOpts and
|
||||
// partitioned by the given label names.
|
||||
func NewHistogramVec(opts HistogramOpts, labelNames []string) *HistogramVec {
|
||||
desc := NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
labelNames,
|
||||
opts.ConstLabels,
|
||||
)
|
||||
return &HistogramVec{
|
||||
metricVec: newMetricVec(desc, func(lvs ...string) Metric {
|
||||
return newHistogram(desc, opts, lvs...)
|
||||
}),
|
||||
}
|
||||
}
|
||||
|
||||
// GetMetricWithLabelValues returns the Histogram for the given slice of label
|
||||
// values (same order as the VariableLabels in Desc). If that combination of
|
||||
// label values is accessed for the first time, a new Histogram is created.
|
||||
//
|
||||
// It is possible to call this method without using the returned Histogram to only
|
||||
// create the new Histogram but leave it at its starting value, a Histogram without
|
||||
// any observations.
|
||||
//
|
||||
// Keeping the Histogram for later use is possible (and should be considered if
|
||||
// performance is critical), but keep in mind that Reset, DeleteLabelValues and
|
||||
// Delete can be used to delete the Histogram from the HistogramVec. In that case, the
|
||||
// Histogram will still exist, but it will not be exported anymore, even if a
|
||||
// Histogram with the same label values is created later. See also the CounterVec
|
||||
// example.
|
||||
//
|
||||
// An error is returned if the number of label values is not the same as the
|
||||
// number of VariableLabels in Desc (minus any curried labels).
|
||||
//
|
||||
// Note that for more than one label value, this method is prone to mistakes
|
||||
// caused by an incorrect order of arguments. Consider GetMetricWith(Labels) as
|
||||
// an alternative to avoid that type of mistake. For higher label numbers, the
|
||||
// latter has a much more readable (albeit more verbose) syntax, but it comes
|
||||
// with a performance overhead (for creating and processing the Labels map).
|
||||
// See also the GaugeVec example.
|
||||
func (v *HistogramVec) GetMetricWithLabelValues(lvs ...string) (Observer, error) {
|
||||
metric, err := v.metricVec.getMetricWithLabelValues(lvs...)
|
||||
if metric != nil {
|
||||
return metric.(Observer), err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// GetMetricWith returns the Histogram for the given Labels map (the label names
|
||||
// must match those of the VariableLabels in Desc). If that label map is
|
||||
// accessed for the first time, a new Histogram is created. Implications of
|
||||
// creating a Histogram without using it and keeping the Histogram for later use
|
||||
// are the same as for GetMetricWithLabelValues.
|
||||
//
|
||||
// An error is returned if the number and names of the Labels are inconsistent
|
||||
// with those of the VariableLabels in Desc (minus any curried labels).
|
||||
//
|
||||
// This method is used for the same purpose as
|
||||
// GetMetricWithLabelValues(...string). See there for pros and cons of the two
|
||||
// methods.
|
||||
func (v *HistogramVec) GetMetricWith(labels Labels) (Observer, error) {
|
||||
metric, err := v.metricVec.getMetricWith(labels)
|
||||
if metric != nil {
|
||||
return metric.(Observer), err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// WithLabelValues works as GetMetricWithLabelValues, but panics where
|
||||
// GetMetricWithLabelValues would have returned an error. Not returning an
|
||||
// error allows shortcuts like
|
||||
// myVec.WithLabelValues("404", "GET").Observe(42.21)
|
||||
func (v *HistogramVec) WithLabelValues(lvs ...string) Observer {
|
||||
h, err := v.GetMetricWithLabelValues(lvs...)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return h
|
||||
}
|
||||
|
||||
// With works as GetMetricWith but panics where GetMetricWithLabels would have
|
||||
// returned an error. Not returning an error allows shortcuts like
|
||||
// myVec.With(prometheus.Labels{"code": "404", "method": "GET"}).Observe(42.21)
|
||||
func (v *HistogramVec) With(labels Labels) Observer {
|
||||
h, err := v.GetMetricWith(labels)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return h
|
||||
}
|
||||
|
||||
// CurryWith returns a vector curried with the provided labels, i.e. the
|
||||
// returned vector has those labels pre-set for all labeled operations performed
|
||||
// on it. The cardinality of the curried vector is reduced accordingly. The
|
||||
// order of the remaining labels stays the same (just with the curried labels
|
||||
// taken out of the sequence – which is relevant for the
|
||||
// (GetMetric)WithLabelValues methods). It is possible to curry a curried
|
||||
// vector, but only with labels not yet used for currying before.
|
||||
//
|
||||
// The metrics contained in the HistogramVec are shared between the curried and
|
||||
// uncurried vectors. They are just accessed differently. Curried and uncurried
|
||||
// vectors behave identically in terms of collection. Only one must be
|
||||
// registered with a given registry (usually the uncurried version). The Reset
|
||||
// method deletes all metrics, even if called on a curried vector.
|
||||
func (v *HistogramVec) CurryWith(labels Labels) (ObserverVec, error) {
|
||||
vec, err := v.curryWith(labels)
|
||||
if vec != nil {
|
||||
return &HistogramVec{vec}, err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// MustCurryWith works as CurryWith but panics where CurryWith would have
|
||||
// returned an error.
|
||||
func (v *HistogramVec) MustCurryWith(labels Labels) ObserverVec {
|
||||
vec, err := v.CurryWith(labels)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return vec
|
||||
}
|
||||
|
||||
type constHistogram struct {
|
||||
desc *Desc
|
||||
count uint64
|
||||
sum float64
|
||||
buckets map[float64]uint64
|
||||
labelPairs []*dto.LabelPair
|
||||
}
|
||||
|
||||
func (h *constHistogram) Desc() *Desc {
|
||||
return h.desc
|
||||
}
|
||||
|
||||
func (h *constHistogram) Write(out *dto.Metric) error {
|
||||
his := &dto.Histogram{}
|
||||
buckets := make([]*dto.Bucket, 0, len(h.buckets))
|
||||
|
||||
his.SampleCount = proto.Uint64(h.count)
|
||||
his.SampleSum = proto.Float64(h.sum)
|
||||
|
||||
for upperBound, count := range h.buckets {
|
||||
buckets = append(buckets, &dto.Bucket{
|
||||
CumulativeCount: proto.Uint64(count),
|
||||
UpperBound: proto.Float64(upperBound),
|
||||
})
|
||||
}
|
||||
|
||||
if len(buckets) > 0 {
|
||||
sort.Sort(buckSort(buckets))
|
||||
}
|
||||
his.Bucket = buckets
|
||||
|
||||
out.Histogram = his
|
||||
out.Label = h.labelPairs
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
// NewConstHistogram returns a metric representing a Prometheus histogram with
|
||||
// fixed values for the count, sum, and bucket counts. As those parameters
|
||||
// cannot be changed, the returned value does not implement the Histogram
|
||||
// interface (but only the Metric interface). Users of this package will not
|
||||
// have much use for it in regular operations. However, when implementing custom
|
||||
// Collectors, it is useful as a throw-away metric that is generated on the fly
|
||||
// to send it to Prometheus in the Collect method.
|
||||
//
|
||||
// buckets is a map of upper bounds to cumulative counts, excluding the +Inf
|
||||
// bucket.
|
||||
//
|
||||
// NewConstHistogram returns an error if the length of labelValues is not
|
||||
// consistent with the variable labels in Desc or if Desc is invalid.
|
||||
func NewConstHistogram(
|
||||
desc *Desc,
|
||||
count uint64,
|
||||
sum float64,
|
||||
buckets map[float64]uint64,
|
||||
labelValues ...string,
|
||||
) (Metric, error) {
|
||||
if desc.err != nil {
|
||||
return nil, desc.err
|
||||
}
|
||||
if err := validateLabelValues(labelValues, len(desc.variableLabels)); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return &constHistogram{
|
||||
desc: desc,
|
||||
count: count,
|
||||
sum: sum,
|
||||
buckets: buckets,
|
||||
labelPairs: makeLabelPairs(desc, labelValues),
|
||||
}, nil
|
||||
}
|
||||
|
||||
// MustNewConstHistogram is a version of NewConstHistogram that panics where
|
||||
// NewConstMetric would have returned an error.
|
||||
func MustNewConstHistogram(
|
||||
desc *Desc,
|
||||
count uint64,
|
||||
sum float64,
|
||||
buckets map[float64]uint64,
|
||||
labelValues ...string,
|
||||
) Metric {
|
||||
m, err := NewConstHistogram(desc, count, sum, buckets, labelValues...)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return m
|
||||
}
|
||||
|
||||
type buckSort []*dto.Bucket
|
||||
|
||||
func (s buckSort) Len() int {
|
||||
return len(s)
|
||||
}
|
||||
|
||||
func (s buckSort) Swap(i, j int) {
|
||||
s[i], s[j] = s[j], s[i]
|
||||
}
|
||||
|
||||
func (s buckSort) Less(i, j int) bool {
|
||||
return s[i].GetUpperBound() < s[j].GetUpperBound()
|
||||
}
|
||||
504
watchdog/vendor/github.com/prometheus/client_golang/prometheus/http.go
generated
vendored
504
watchdog/vendor/github.com/prometheus/client_golang/prometheus/http.go
generated
vendored
@ -1,504 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"compress/gzip"
|
||||
"io"
|
||||
"net"
|
||||
"net/http"
|
||||
"strconv"
|
||||
"strings"
|
||||
"sync"
|
||||
"time"
|
||||
|
||||
"github.com/prometheus/common/expfmt"
|
||||
)
|
||||
|
||||
// TODO(beorn7): Remove this whole file. It is a partial mirror of
|
||||
// promhttp/http.go (to avoid circular import chains) where everything HTTP
|
||||
// related should live. The functions here are just for avoiding
|
||||
// breakage. Everything is deprecated.
|
||||
|
||||
const (
|
||||
contentTypeHeader = "Content-Type"
|
||||
contentLengthHeader = "Content-Length"
|
||||
contentEncodingHeader = "Content-Encoding"
|
||||
acceptEncodingHeader = "Accept-Encoding"
|
||||
)
|
||||
|
||||
var gzipPool = sync.Pool{
|
||||
New: func() interface{} {
|
||||
return gzip.NewWriter(nil)
|
||||
},
|
||||
}
|
||||
|
||||
// Handler returns an HTTP handler for the DefaultGatherer. It is
|
||||
// already instrumented with InstrumentHandler (using "prometheus" as handler
|
||||
// name).
|
||||
//
|
||||
// Deprecated: Please note the issues described in the doc comment of
|
||||
// InstrumentHandler. You might want to consider using promhttp.Handler instead.
|
||||
func Handler() http.Handler {
|
||||
return InstrumentHandler("prometheus", UninstrumentedHandler())
|
||||
}
|
||||
|
||||
// UninstrumentedHandler returns an HTTP handler for the DefaultGatherer.
|
||||
//
|
||||
// Deprecated: Use promhttp.HandlerFor(DefaultGatherer, promhttp.HandlerOpts{})
|
||||
// instead. See there for further documentation.
|
||||
func UninstrumentedHandler() http.Handler {
|
||||
return http.HandlerFunc(func(rsp http.ResponseWriter, req *http.Request) {
|
||||
mfs, err := DefaultGatherer.Gather()
|
||||
if err != nil {
|
||||
httpError(rsp, err)
|
||||
return
|
||||
}
|
||||
|
||||
contentType := expfmt.Negotiate(req.Header)
|
||||
header := rsp.Header()
|
||||
header.Set(contentTypeHeader, string(contentType))
|
||||
|
||||
w := io.Writer(rsp)
|
||||
if gzipAccepted(req.Header) {
|
||||
header.Set(contentEncodingHeader, "gzip")
|
||||
gz := gzipPool.Get().(*gzip.Writer)
|
||||
defer gzipPool.Put(gz)
|
||||
|
||||
gz.Reset(w)
|
||||
defer gz.Close()
|
||||
|
||||
w = gz
|
||||
}
|
||||
|
||||
enc := expfmt.NewEncoder(w, contentType)
|
||||
|
||||
for _, mf := range mfs {
|
||||
if err := enc.Encode(mf); err != nil {
|
||||
httpError(rsp, err)
|
||||
return
|
||||
}
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
var instLabels = []string{"method", "code"}
|
||||
|
||||
type nower interface {
|
||||
Now() time.Time
|
||||
}
|
||||
|
||||
type nowFunc func() time.Time
|
||||
|
||||
func (n nowFunc) Now() time.Time {
|
||||
return n()
|
||||
}
|
||||
|
||||
var now nower = nowFunc(func() time.Time {
|
||||
return time.Now()
|
||||
})
|
||||
|
||||
// InstrumentHandler wraps the given HTTP handler for instrumentation. It
|
||||
// registers four metric collectors (if not already done) and reports HTTP
|
||||
// metrics to the (newly or already) registered collectors: http_requests_total
|
||||
// (CounterVec), http_request_duration_microseconds (Summary),
|
||||
// http_request_size_bytes (Summary), http_response_size_bytes (Summary). Each
|
||||
// has a constant label named "handler" with the provided handlerName as
|
||||
// value. http_requests_total is a metric vector partitioned by HTTP method
|
||||
// (label name "method") and HTTP status code (label name "code").
|
||||
//
|
||||
// Deprecated: InstrumentHandler has several issues. Use the tooling provided in
|
||||
// package promhttp instead. The issues are the following: (1) It uses Summaries
|
||||
// rather than Histograms. Summaries are not useful if aggregation across
|
||||
// multiple instances is required. (2) It uses microseconds as unit, which is
|
||||
// deprecated and should be replaced by seconds. (3) The size of the request is
|
||||
// calculated in a separate goroutine. Since this calculator requires access to
|
||||
// the request header, it creates a race with any writes to the header performed
|
||||
// during request handling. httputil.ReverseProxy is a prominent example for a
|
||||
// handler performing such writes. (4) It has additional issues with HTTP/2, cf.
|
||||
// https://github.com/prometheus/client_golang/issues/272.
|
||||
func InstrumentHandler(handlerName string, handler http.Handler) http.HandlerFunc {
|
||||
return InstrumentHandlerFunc(handlerName, handler.ServeHTTP)
|
||||
}
|
||||
|
||||
// InstrumentHandlerFunc wraps the given function for instrumentation. It
|
||||
// otherwise works in the same way as InstrumentHandler (and shares the same
|
||||
// issues).
|
||||
//
|
||||
// Deprecated: InstrumentHandlerFunc is deprecated for the same reasons as
|
||||
// InstrumentHandler is. Use the tooling provided in package promhttp instead.
|
||||
func InstrumentHandlerFunc(handlerName string, handlerFunc func(http.ResponseWriter, *http.Request)) http.HandlerFunc {
|
||||
return InstrumentHandlerFuncWithOpts(
|
||||
SummaryOpts{
|
||||
Subsystem: "http",
|
||||
ConstLabels: Labels{"handler": handlerName},
|
||||
Objectives: map[float64]float64{0.5: 0.05, 0.9: 0.01, 0.99: 0.001},
|
||||
},
|
||||
handlerFunc,
|
||||
)
|
||||
}
|
||||
|
||||
// InstrumentHandlerWithOpts works like InstrumentHandler (and shares the same
|
||||
// issues) but provides more flexibility (at the cost of a more complex call
|
||||
// syntax). As InstrumentHandler, this function registers four metric
|
||||
// collectors, but it uses the provided SummaryOpts to create them. However, the
|
||||
// fields "Name" and "Help" in the SummaryOpts are ignored. "Name" is replaced
|
||||
// by "requests_total", "request_duration_microseconds", "request_size_bytes",
|
||||
// and "response_size_bytes", respectively. "Help" is replaced by an appropriate
|
||||
// help string. The names of the variable labels of the http_requests_total
|
||||
// CounterVec are "method" (get, post, etc.), and "code" (HTTP status code).
|
||||
//
|
||||
// If InstrumentHandlerWithOpts is called as follows, it mimics exactly the
|
||||
// behavior of InstrumentHandler:
|
||||
//
|
||||
// prometheus.InstrumentHandlerWithOpts(
|
||||
// prometheus.SummaryOpts{
|
||||
// Subsystem: "http",
|
||||
// ConstLabels: prometheus.Labels{"handler": handlerName},
|
||||
// },
|
||||
// handler,
|
||||
// )
|
||||
//
|
||||
// Technical detail: "requests_total" is a CounterVec, not a SummaryVec, so it
|
||||
// cannot use SummaryOpts. Instead, a CounterOpts struct is created internally,
|
||||
// and all its fields are set to the equally named fields in the provided
|
||||
// SummaryOpts.
|
||||
//
|
||||
// Deprecated: InstrumentHandlerWithOpts is deprecated for the same reasons as
|
||||
// InstrumentHandler is. Use the tooling provided in package promhttp instead.
|
||||
func InstrumentHandlerWithOpts(opts SummaryOpts, handler http.Handler) http.HandlerFunc {
|
||||
return InstrumentHandlerFuncWithOpts(opts, handler.ServeHTTP)
|
||||
}
|
||||
|
||||
// InstrumentHandlerFuncWithOpts works like InstrumentHandlerFunc (and shares
|
||||
// the same issues) but provides more flexibility (at the cost of a more complex
|
||||
// call syntax). See InstrumentHandlerWithOpts for details how the provided
|
||||
// SummaryOpts are used.
|
||||
//
|
||||
// Deprecated: InstrumentHandlerFuncWithOpts is deprecated for the same reasons
|
||||
// as InstrumentHandler is. Use the tooling provided in package promhttp instead.
|
||||
func InstrumentHandlerFuncWithOpts(opts SummaryOpts, handlerFunc func(http.ResponseWriter, *http.Request)) http.HandlerFunc {
|
||||
reqCnt := NewCounterVec(
|
||||
CounterOpts{
|
||||
Namespace: opts.Namespace,
|
||||
Subsystem: opts.Subsystem,
|
||||
Name: "requests_total",
|
||||
Help: "Total number of HTTP requests made.",
|
||||
ConstLabels: opts.ConstLabels,
|
||||
},
|
||||
instLabels,
|
||||
)
|
||||
if err := Register(reqCnt); err != nil {
|
||||
if are, ok := err.(AlreadyRegisteredError); ok {
|
||||
reqCnt = are.ExistingCollector.(*CounterVec)
|
||||
} else {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
|
||||
opts.Name = "request_duration_microseconds"
|
||||
opts.Help = "The HTTP request latencies in microseconds."
|
||||
reqDur := NewSummary(opts)
|
||||
if err := Register(reqDur); err != nil {
|
||||
if are, ok := err.(AlreadyRegisteredError); ok {
|
||||
reqDur = are.ExistingCollector.(Summary)
|
||||
} else {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
|
||||
opts.Name = "request_size_bytes"
|
||||
opts.Help = "The HTTP request sizes in bytes."
|
||||
reqSz := NewSummary(opts)
|
||||
if err := Register(reqSz); err != nil {
|
||||
if are, ok := err.(AlreadyRegisteredError); ok {
|
||||
reqSz = are.ExistingCollector.(Summary)
|
||||
} else {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
|
||||
opts.Name = "response_size_bytes"
|
||||
opts.Help = "The HTTP response sizes in bytes."
|
||||
resSz := NewSummary(opts)
|
||||
if err := Register(resSz); err != nil {
|
||||
if are, ok := err.(AlreadyRegisteredError); ok {
|
||||
resSz = are.ExistingCollector.(Summary)
|
||||
} else {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
|
||||
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
now := time.Now()
|
||||
|
||||
delegate := &responseWriterDelegator{ResponseWriter: w}
|
||||
out := computeApproximateRequestSize(r)
|
||||
|
||||
_, cn := w.(http.CloseNotifier)
|
||||
_, fl := w.(http.Flusher)
|
||||
_, hj := w.(http.Hijacker)
|
||||
_, rf := w.(io.ReaderFrom)
|
||||
var rw http.ResponseWriter
|
||||
if cn && fl && hj && rf {
|
||||
rw = &fancyResponseWriterDelegator{delegate}
|
||||
} else {
|
||||
rw = delegate
|
||||
}
|
||||
handlerFunc(rw, r)
|
||||
|
||||
elapsed := float64(time.Since(now)) / float64(time.Microsecond)
|
||||
|
||||
method := sanitizeMethod(r.Method)
|
||||
code := sanitizeCode(delegate.status)
|
||||
reqCnt.WithLabelValues(method, code).Inc()
|
||||
reqDur.Observe(elapsed)
|
||||
resSz.Observe(float64(delegate.written))
|
||||
reqSz.Observe(float64(<-out))
|
||||
})
|
||||
}
|
||||
|
||||
func computeApproximateRequestSize(r *http.Request) <-chan int {
|
||||
// Get URL length in current goroutine for avoiding a race condition.
|
||||
// HandlerFunc that runs in parallel may modify the URL.
|
||||
s := 0
|
||||
if r.URL != nil {
|
||||
s += len(r.URL.String())
|
||||
}
|
||||
|
||||
out := make(chan int, 1)
|
||||
|
||||
go func() {
|
||||
s += len(r.Method)
|
||||
s += len(r.Proto)
|
||||
for name, values := range r.Header {
|
||||
s += len(name)
|
||||
for _, value := range values {
|
||||
s += len(value)
|
||||
}
|
||||
}
|
||||
s += len(r.Host)
|
||||
|
||||
// N.B. r.Form and r.MultipartForm are assumed to be included in r.URL.
|
||||
|
||||
if r.ContentLength != -1 {
|
||||
s += int(r.ContentLength)
|
||||
}
|
||||
out <- s
|
||||
close(out)
|
||||
}()
|
||||
|
||||
return out
|
||||
}
|
||||
|
||||
type responseWriterDelegator struct {
|
||||
http.ResponseWriter
|
||||
|
||||
status int
|
||||
written int64
|
||||
wroteHeader bool
|
||||
}
|
||||
|
||||
func (r *responseWriterDelegator) WriteHeader(code int) {
|
||||
r.status = code
|
||||
r.wroteHeader = true
|
||||
r.ResponseWriter.WriteHeader(code)
|
||||
}
|
||||
|
||||
func (r *responseWriterDelegator) Write(b []byte) (int, error) {
|
||||
if !r.wroteHeader {
|
||||
r.WriteHeader(http.StatusOK)
|
||||
}
|
||||
n, err := r.ResponseWriter.Write(b)
|
||||
r.written += int64(n)
|
||||
return n, err
|
||||
}
|
||||
|
||||
type fancyResponseWriterDelegator struct {
|
||||
*responseWriterDelegator
|
||||
}
|
||||
|
||||
func (f *fancyResponseWriterDelegator) CloseNotify() <-chan bool {
|
||||
return f.ResponseWriter.(http.CloseNotifier).CloseNotify()
|
||||
}
|
||||
|
||||
func (f *fancyResponseWriterDelegator) Flush() {
|
||||
f.ResponseWriter.(http.Flusher).Flush()
|
||||
}
|
||||
|
||||
func (f *fancyResponseWriterDelegator) Hijack() (net.Conn, *bufio.ReadWriter, error) {
|
||||
return f.ResponseWriter.(http.Hijacker).Hijack()
|
||||
}
|
||||
|
||||
func (f *fancyResponseWriterDelegator) ReadFrom(r io.Reader) (int64, error) {
|
||||
if !f.wroteHeader {
|
||||
f.WriteHeader(http.StatusOK)
|
||||
}
|
||||
n, err := f.ResponseWriter.(io.ReaderFrom).ReadFrom(r)
|
||||
f.written += n
|
||||
return n, err
|
||||
}
|
||||
|
||||
func sanitizeMethod(m string) string {
|
||||
switch m {
|
||||
case "GET", "get":
|
||||
return "get"
|
||||
case "PUT", "put":
|
||||
return "put"
|
||||
case "HEAD", "head":
|
||||
return "head"
|
||||
case "POST", "post":
|
||||
return "post"
|
||||
case "DELETE", "delete":
|
||||
return "delete"
|
||||
case "CONNECT", "connect":
|
||||
return "connect"
|
||||
case "OPTIONS", "options":
|
||||
return "options"
|
||||
case "NOTIFY", "notify":
|
||||
return "notify"
|
||||
default:
|
||||
return strings.ToLower(m)
|
||||
}
|
||||
}
|
||||
|
||||
func sanitizeCode(s int) string {
|
||||
switch s {
|
||||
case 100:
|
||||
return "100"
|
||||
case 101:
|
||||
return "101"
|
||||
|
||||
case 200:
|
||||
return "200"
|
||||
case 201:
|
||||
return "201"
|
||||
case 202:
|
||||
return "202"
|
||||
case 203:
|
||||
return "203"
|
||||
case 204:
|
||||
return "204"
|
||||
case 205:
|
||||
return "205"
|
||||
case 206:
|
||||
return "206"
|
||||
|
||||
case 300:
|
||||
return "300"
|
||||
case 301:
|
||||
return "301"
|
||||
case 302:
|
||||
return "302"
|
||||
case 304:
|
||||
return "304"
|
||||
case 305:
|
||||
return "305"
|
||||
case 307:
|
||||
return "307"
|
||||
|
||||
case 400:
|
||||
return "400"
|
||||
case 401:
|
||||
return "401"
|
||||
case 402:
|
||||
return "402"
|
||||
case 403:
|
||||
return "403"
|
||||
case 404:
|
||||
return "404"
|
||||
case 405:
|
||||
return "405"
|
||||
case 406:
|
||||
return "406"
|
||||
case 407:
|
||||
return "407"
|
||||
case 408:
|
||||
return "408"
|
||||
case 409:
|
||||
return "409"
|
||||
case 410:
|
||||
return "410"
|
||||
case 411:
|
||||
return "411"
|
||||
case 412:
|
||||
return "412"
|
||||
case 413:
|
||||
return "413"
|
||||
case 414:
|
||||
return "414"
|
||||
case 415:
|
||||
return "415"
|
||||
case 416:
|
||||
return "416"
|
||||
case 417:
|
||||
return "417"
|
||||
case 418:
|
||||
return "418"
|
||||
|
||||
case 500:
|
||||
return "500"
|
||||
case 501:
|
||||
return "501"
|
||||
case 502:
|
||||
return "502"
|
||||
case 503:
|
||||
return "503"
|
||||
case 504:
|
||||
return "504"
|
||||
case 505:
|
||||
return "505"
|
||||
|
||||
case 428:
|
||||
return "428"
|
||||
case 429:
|
||||
return "429"
|
||||
case 431:
|
||||
return "431"
|
||||
case 511:
|
||||
return "511"
|
||||
|
||||
default:
|
||||
return strconv.Itoa(s)
|
||||
}
|
||||
}
|
||||
|
||||
// gzipAccepted returns whether the client will accept gzip-encoded content.
|
||||
func gzipAccepted(header http.Header) bool {
|
||||
a := header.Get(acceptEncodingHeader)
|
||||
parts := strings.Split(a, ",")
|
||||
for _, part := range parts {
|
||||
part = strings.TrimSpace(part)
|
||||
if part == "gzip" || strings.HasPrefix(part, "gzip;") {
|
||||
return true
|
||||
}
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
// httpError removes any content-encoding header and then calls http.Error with
|
||||
// the provided error and http.StatusInternalServerErrer. Error contents is
|
||||
// supposed to be uncompressed plain text. However, same as with a plain
|
||||
// http.Error, any header settings will be void if the header has already been
|
||||
// sent. The error message will still be written to the writer, but it will
|
||||
// probably be of limited use.
|
||||
func httpError(rsp http.ResponseWriter, err error) {
|
||||
rsp.Header().Del(contentEncodingHeader)
|
||||
http.Error(
|
||||
rsp,
|
||||
"An error has occurred while serving metrics:\n\n"+err.Error(),
|
||||
http.StatusInternalServerError,
|
||||
)
|
||||
}
|
||||
85
watchdog/vendor/github.com/prometheus/client_golang/prometheus/internal/metric.go
generated
vendored
85
watchdog/vendor/github.com/prometheus/client_golang/prometheus/internal/metric.go
generated
vendored
@ -1,85 +0,0 @@
|
||||
// Copyright 2018 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package internal
|
||||
|
||||
import (
|
||||
"sort"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
)
|
||||
|
||||
// metricSorter is a sortable slice of *dto.Metric.
|
||||
type metricSorter []*dto.Metric
|
||||
|
||||
func (s metricSorter) Len() int {
|
||||
return len(s)
|
||||
}
|
||||
|
||||
func (s metricSorter) Swap(i, j int) {
|
||||
s[i], s[j] = s[j], s[i]
|
||||
}
|
||||
|
||||
func (s metricSorter) Less(i, j int) bool {
|
||||
if len(s[i].Label) != len(s[j].Label) {
|
||||
// This should not happen. The metrics are
|
||||
// inconsistent. However, we have to deal with the fact, as
|
||||
// people might use custom collectors or metric family injection
|
||||
// to create inconsistent metrics. So let's simply compare the
|
||||
// number of labels in this case. That will still yield
|
||||
// reproducible sorting.
|
||||
return len(s[i].Label) < len(s[j].Label)
|
||||
}
|
||||
for n, lp := range s[i].Label {
|
||||
vi := lp.GetValue()
|
||||
vj := s[j].Label[n].GetValue()
|
||||
if vi != vj {
|
||||
return vi < vj
|
||||
}
|
||||
}
|
||||
|
||||
// We should never arrive here. Multiple metrics with the same
|
||||
// label set in the same scrape will lead to undefined ingestion
|
||||
// behavior. However, as above, we have to provide stable sorting
|
||||
// here, even for inconsistent metrics. So sort equal metrics
|
||||
// by their timestamp, with missing timestamps (implying "now")
|
||||
// coming last.
|
||||
if s[i].TimestampMs == nil {
|
||||
return false
|
||||
}
|
||||
if s[j].TimestampMs == nil {
|
||||
return true
|
||||
}
|
||||
return s[i].GetTimestampMs() < s[j].GetTimestampMs()
|
||||
}
|
||||
|
||||
// NormalizeMetricFamilies returns a MetricFamily slice with empty
|
||||
// MetricFamilies pruned and the remaining MetricFamilies sorted by name within
|
||||
// the slice, with the contained Metrics sorted within each MetricFamily.
|
||||
func NormalizeMetricFamilies(metricFamiliesByName map[string]*dto.MetricFamily) []*dto.MetricFamily {
|
||||
for _, mf := range metricFamiliesByName {
|
||||
sort.Sort(metricSorter(mf.Metric))
|
||||
}
|
||||
names := make([]string, 0, len(metricFamiliesByName))
|
||||
for name, mf := range metricFamiliesByName {
|
||||
if len(mf.Metric) > 0 {
|
||||
names = append(names, name)
|
||||
}
|
||||
}
|
||||
sort.Strings(names)
|
||||
result := make([]*dto.MetricFamily, 0, len(names))
|
||||
for _, name := range names {
|
||||
result = append(result, metricFamiliesByName[name])
|
||||
}
|
||||
return result
|
||||
}
|
||||
87
watchdog/vendor/github.com/prometheus/client_golang/prometheus/labels.go
generated
vendored
87
watchdog/vendor/github.com/prometheus/client_golang/prometheus/labels.go
generated
vendored
@ -1,87 +0,0 @@
|
||||
// Copyright 2018 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
"strings"
|
||||
"unicode/utf8"
|
||||
|
||||
"github.com/prometheus/common/model"
|
||||
)
|
||||
|
||||
// Labels represents a collection of label name -> value mappings. This type is
|
||||
// commonly used with the With(Labels) and GetMetricWith(Labels) methods of
|
||||
// metric vector Collectors, e.g.:
|
||||
// myVec.With(Labels{"code": "404", "method": "GET"}).Add(42)
|
||||
//
|
||||
// The other use-case is the specification of constant label pairs in Opts or to
|
||||
// create a Desc.
|
||||
type Labels map[string]string
|
||||
|
||||
// reservedLabelPrefix is a prefix which is not legal in user-supplied
|
||||
// label names.
|
||||
const reservedLabelPrefix = "__"
|
||||
|
||||
var errInconsistentCardinality = errors.New("inconsistent label cardinality")
|
||||
|
||||
func makeInconsistentCardinalityError(fqName string, labels, labelValues []string) error {
|
||||
return fmt.Errorf(
|
||||
"%s: %q has %d variable labels named %q but %d values %q were provided",
|
||||
errInconsistentCardinality, fqName,
|
||||
len(labels), labels,
|
||||
len(labelValues), labelValues,
|
||||
)
|
||||
}
|
||||
|
||||
func validateValuesInLabels(labels Labels, expectedNumberOfValues int) error {
|
||||
if len(labels) != expectedNumberOfValues {
|
||||
return fmt.Errorf(
|
||||
"%s: expected %d label values but got %d in %#v",
|
||||
errInconsistentCardinality, expectedNumberOfValues,
|
||||
len(labels), labels,
|
||||
)
|
||||
}
|
||||
|
||||
for name, val := range labels {
|
||||
if !utf8.ValidString(val) {
|
||||
return fmt.Errorf("label %s: value %q is not valid UTF-8", name, val)
|
||||
}
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func validateLabelValues(vals []string, expectedNumberOfValues int) error {
|
||||
if len(vals) != expectedNumberOfValues {
|
||||
return fmt.Errorf(
|
||||
"%s: expected %d label values but got %d in %#v",
|
||||
errInconsistentCardinality, expectedNumberOfValues,
|
||||
len(vals), vals,
|
||||
)
|
||||
}
|
||||
|
||||
for _, val := range vals {
|
||||
if !utf8.ValidString(val) {
|
||||
return fmt.Errorf("label value %q is not valid UTF-8", val)
|
||||
}
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func checkLabelName(l string) bool {
|
||||
return model.LabelName(l).IsValid() && !strings.HasPrefix(l, reservedLabelPrefix)
|
||||
}
|
||||
174
watchdog/vendor/github.com/prometheus/client_golang/prometheus/metric.go
generated
vendored
174
watchdog/vendor/github.com/prometheus/client_golang/prometheus/metric.go
generated
vendored
@ -1,174 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
"github.com/golang/protobuf/proto"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
)
|
||||
|
||||
const separatorByte byte = 255
|
||||
|
||||
// A Metric models a single sample value with its meta data being exported to
|
||||
// Prometheus. Implementations of Metric in this package are Gauge, Counter,
|
||||
// Histogram, Summary, and Untyped.
|
||||
type Metric interface {
|
||||
// Desc returns the descriptor for the Metric. This method idempotently
|
||||
// returns the same descriptor throughout the lifetime of the
|
||||
// Metric. The returned descriptor is immutable by contract. A Metric
|
||||
// unable to describe itself must return an invalid descriptor (created
|
||||
// with NewInvalidDesc).
|
||||
Desc() *Desc
|
||||
// Write encodes the Metric into a "Metric" Protocol Buffer data
|
||||
// transmission object.
|
||||
//
|
||||
// Metric implementations must observe concurrency safety as reads of
|
||||
// this metric may occur at any time, and any blocking occurs at the
|
||||
// expense of total performance of rendering all registered
|
||||
// metrics. Ideally, Metric implementations should support concurrent
|
||||
// readers.
|
||||
//
|
||||
// While populating dto.Metric, it is the responsibility of the
|
||||
// implementation to ensure validity of the Metric protobuf (like valid
|
||||
// UTF-8 strings or syntactically valid metric and label names). It is
|
||||
// recommended to sort labels lexicographically. Callers of Write should
|
||||
// still make sure of sorting if they depend on it.
|
||||
Write(*dto.Metric) error
|
||||
// TODO(beorn7): The original rationale of passing in a pre-allocated
|
||||
// dto.Metric protobuf to save allocations has disappeared. The
|
||||
// signature of this method should be changed to "Write() (*dto.Metric,
|
||||
// error)".
|
||||
}
|
||||
|
||||
// Opts bundles the options for creating most Metric types. Each metric
|
||||
// implementation XXX has its own XXXOpts type, but in most cases, it is just be
|
||||
// an alias of this type (which might change when the requirement arises.)
|
||||
//
|
||||
// It is mandatory to set Name to a non-empty string. All other fields are
|
||||
// optional and can safely be left at their zero value, although it is strongly
|
||||
// encouraged to set a Help string.
|
||||
type Opts struct {
|
||||
// Namespace, Subsystem, and Name are components of the fully-qualified
|
||||
// name of the Metric (created by joining these components with
|
||||
// "_"). Only Name is mandatory, the others merely help structuring the
|
||||
// name. Note that the fully-qualified name of the metric must be a
|
||||
// valid Prometheus metric name.
|
||||
Namespace string
|
||||
Subsystem string
|
||||
Name string
|
||||
|
||||
// Help provides information about this metric.
|
||||
//
|
||||
// Metrics with the same fully-qualified name must have the same Help
|
||||
// string.
|
||||
Help string
|
||||
|
||||
// ConstLabels are used to attach fixed labels to this metric. Metrics
|
||||
// with the same fully-qualified name must have the same label names in
|
||||
// their ConstLabels.
|
||||
//
|
||||
// ConstLabels are only used rarely. In particular, do not use them to
|
||||
// attach the same labels to all your metrics. Those use cases are
|
||||
// better covered by target labels set by the scraping Prometheus
|
||||
// server, or by one specific metric (e.g. a build_info or a
|
||||
// machine_role metric). See also
|
||||
// https://prometheus.io/docs/instrumenting/writing_exporters/#target-labels,-not-static-scraped-labels
|
||||
ConstLabels Labels
|
||||
}
|
||||
|
||||
// BuildFQName joins the given three name components by "_". Empty name
|
||||
// components are ignored. If the name parameter itself is empty, an empty
|
||||
// string is returned, no matter what. Metric implementations included in this
|
||||
// library use this function internally to generate the fully-qualified metric
|
||||
// name from the name component in their Opts. Users of the library will only
|
||||
// need this function if they implement their own Metric or instantiate a Desc
|
||||
// (with NewDesc) directly.
|
||||
func BuildFQName(namespace, subsystem, name string) string {
|
||||
if name == "" {
|
||||
return ""
|
||||
}
|
||||
switch {
|
||||
case namespace != "" && subsystem != "":
|
||||
return strings.Join([]string{namespace, subsystem, name}, "_")
|
||||
case namespace != "":
|
||||
return strings.Join([]string{namespace, name}, "_")
|
||||
case subsystem != "":
|
||||
return strings.Join([]string{subsystem, name}, "_")
|
||||
}
|
||||
return name
|
||||
}
|
||||
|
||||
// labelPairSorter implements sort.Interface. It is used to sort a slice of
|
||||
// dto.LabelPair pointers.
|
||||
type labelPairSorter []*dto.LabelPair
|
||||
|
||||
func (s labelPairSorter) Len() int {
|
||||
return len(s)
|
||||
}
|
||||
|
||||
func (s labelPairSorter) Swap(i, j int) {
|
||||
s[i], s[j] = s[j], s[i]
|
||||
}
|
||||
|
||||
func (s labelPairSorter) Less(i, j int) bool {
|
||||
return s[i].GetName() < s[j].GetName()
|
||||
}
|
||||
|
||||
type invalidMetric struct {
|
||||
desc *Desc
|
||||
err error
|
||||
}
|
||||
|
||||
// NewInvalidMetric returns a metric whose Write method always returns the
|
||||
// provided error. It is useful if a Collector finds itself unable to collect
|
||||
// a metric and wishes to report an error to the registry.
|
||||
func NewInvalidMetric(desc *Desc, err error) Metric {
|
||||
return &invalidMetric{desc, err}
|
||||
}
|
||||
|
||||
func (m *invalidMetric) Desc() *Desc { return m.desc }
|
||||
|
||||
func (m *invalidMetric) Write(*dto.Metric) error { return m.err }
|
||||
|
||||
type timestampedMetric struct {
|
||||
Metric
|
||||
t time.Time
|
||||
}
|
||||
|
||||
func (m timestampedMetric) Write(pb *dto.Metric) error {
|
||||
e := m.Metric.Write(pb)
|
||||
pb.TimestampMs = proto.Int64(m.t.Unix()*1000 + int64(m.t.Nanosecond()/1000000))
|
||||
return e
|
||||
}
|
||||
|
||||
// NewMetricWithTimestamp returns a new Metric wrapping the provided Metric in a
|
||||
// way that it has an explicit timestamp set to the provided Time. This is only
|
||||
// useful in rare cases as the timestamp of a Prometheus metric should usually
|
||||
// be set by the Prometheus server during scraping. Exceptions include mirroring
|
||||
// metrics with given timestamps from other metric
|
||||
// sources.
|
||||
//
|
||||
// NewMetricWithTimestamp works best with MustNewConstMetric,
|
||||
// MustNewConstHistogram, and MustNewConstSummary, see example.
|
||||
//
|
||||
// Currently, the exposition formats used by Prometheus are limited to
|
||||
// millisecond resolution. Thus, the provided time will be rounded down to the
|
||||
// next full millisecond value.
|
||||
func NewMetricWithTimestamp(t time.Time, m Metric) Metric {
|
||||
return timestampedMetric{Metric: m, t: t}
|
||||
}
|
||||
52
watchdog/vendor/github.com/prometheus/client_golang/prometheus/observer.go
generated
vendored
52
watchdog/vendor/github.com/prometheus/client_golang/prometheus/observer.go
generated
vendored
@ -1,52 +0,0 @@
|
||||
// Copyright 2017 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
// Observer is the interface that wraps the Observe method, which is used by
|
||||
// Histogram and Summary to add observations.
|
||||
type Observer interface {
|
||||
Observe(float64)
|
||||
}
|
||||
|
||||
// The ObserverFunc type is an adapter to allow the use of ordinary
|
||||
// functions as Observers. If f is a function with the appropriate
|
||||
// signature, ObserverFunc(f) is an Observer that calls f.
|
||||
//
|
||||
// This adapter is usually used in connection with the Timer type, and there are
|
||||
// two general use cases:
|
||||
//
|
||||
// The most common one is to use a Gauge as the Observer for a Timer.
|
||||
// See the "Gauge" Timer example.
|
||||
//
|
||||
// The more advanced use case is to create a function that dynamically decides
|
||||
// which Observer to use for observing the duration. See the "Complex" Timer
|
||||
// example.
|
||||
type ObserverFunc func(float64)
|
||||
|
||||
// Observe calls f(value). It implements Observer.
|
||||
func (f ObserverFunc) Observe(value float64) {
|
||||
f(value)
|
||||
}
|
||||
|
||||
// ObserverVec is an interface implemented by `HistogramVec` and `SummaryVec`.
|
||||
type ObserverVec interface {
|
||||
GetMetricWith(Labels) (Observer, error)
|
||||
GetMetricWithLabelValues(lvs ...string) (Observer, error)
|
||||
With(Labels) Observer
|
||||
WithLabelValues(...string) Observer
|
||||
CurryWith(Labels) (ObserverVec, error)
|
||||
MustCurryWith(Labels) ObserverVec
|
||||
|
||||
Collector
|
||||
}
|
||||
204
watchdog/vendor/github.com/prometheus/client_golang/prometheus/process_collector.go
generated
vendored
204
watchdog/vendor/github.com/prometheus/client_golang/prometheus/process_collector.go
generated
vendored
@ -1,204 +0,0 @@
|
||||
// Copyright 2015 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"os"
|
||||
|
||||
"github.com/prometheus/procfs"
|
||||
)
|
||||
|
||||
type processCollector struct {
|
||||
collectFn func(chan<- Metric)
|
||||
pidFn func() (int, error)
|
||||
reportErrors bool
|
||||
cpuTotal *Desc
|
||||
openFDs, maxFDs *Desc
|
||||
vsize, maxVsize *Desc
|
||||
rss *Desc
|
||||
startTime *Desc
|
||||
}
|
||||
|
||||
// ProcessCollectorOpts defines the behavior of a process metrics collector
|
||||
// created with NewProcessCollector.
|
||||
type ProcessCollectorOpts struct {
|
||||
// PidFn returns the PID of the process the collector collects metrics
|
||||
// for. It is called upon each collection. By default, the PID of the
|
||||
// current process is used, as determined on construction time by
|
||||
// calling os.Getpid().
|
||||
PidFn func() (int, error)
|
||||
// If non-empty, each of the collected metrics is prefixed by the
|
||||
// provided string and an underscore ("_").
|
||||
Namespace string
|
||||
// If true, any error encountered during collection is reported as an
|
||||
// invalid metric (see NewInvalidMetric). Otherwise, errors are ignored
|
||||
// and the collected metrics will be incomplete. (Possibly, no metrics
|
||||
// will be collected at all.) While that's usually not desired, it is
|
||||
// appropriate for the common "mix-in" of process metrics, where process
|
||||
// metrics are nice to have, but failing to collect them should not
|
||||
// disrupt the collection of the remaining metrics.
|
||||
ReportErrors bool
|
||||
}
|
||||
|
||||
// NewProcessCollector returns a collector which exports the current state of
|
||||
// process metrics including CPU, memory and file descriptor usage as well as
|
||||
// the process start time. The detailed behavior is defined by the provided
|
||||
// ProcessCollectorOpts. The zero value of ProcessCollectorOpts creates a
|
||||
// collector for the current process with an empty namespace string and no error
|
||||
// reporting.
|
||||
//
|
||||
// Currently, the collector depends on a Linux-style proc filesystem and
|
||||
// therefore only exports metrics for Linux.
|
||||
//
|
||||
// Note: An older version of this function had the following signature:
|
||||
//
|
||||
// NewProcessCollector(pid int, namespace string) Collector
|
||||
//
|
||||
// Most commonly, it was called as
|
||||
//
|
||||
// NewProcessCollector(os.Getpid(), "")
|
||||
//
|
||||
// The following call of the current version is equivalent to the above:
|
||||
//
|
||||
// NewProcessCollector(ProcessCollectorOpts{})
|
||||
func NewProcessCollector(opts ProcessCollectorOpts) Collector {
|
||||
ns := ""
|
||||
if len(opts.Namespace) > 0 {
|
||||
ns = opts.Namespace + "_"
|
||||
}
|
||||
|
||||
c := &processCollector{
|
||||
reportErrors: opts.ReportErrors,
|
||||
cpuTotal: NewDesc(
|
||||
ns+"process_cpu_seconds_total",
|
||||
"Total user and system CPU time spent in seconds.",
|
||||
nil, nil,
|
||||
),
|
||||
openFDs: NewDesc(
|
||||
ns+"process_open_fds",
|
||||
"Number of open file descriptors.",
|
||||
nil, nil,
|
||||
),
|
||||
maxFDs: NewDesc(
|
||||
ns+"process_max_fds",
|
||||
"Maximum number of open file descriptors.",
|
||||
nil, nil,
|
||||
),
|
||||
vsize: NewDesc(
|
||||
ns+"process_virtual_memory_bytes",
|
||||
"Virtual memory size in bytes.",
|
||||
nil, nil,
|
||||
),
|
||||
maxVsize: NewDesc(
|
||||
ns+"process_virtual_memory_max_bytes",
|
||||
"Maximum amount of virtual memory available in bytes.",
|
||||
nil, nil,
|
||||
),
|
||||
rss: NewDesc(
|
||||
ns+"process_resident_memory_bytes",
|
||||
"Resident memory size in bytes.",
|
||||
nil, nil,
|
||||
),
|
||||
startTime: NewDesc(
|
||||
ns+"process_start_time_seconds",
|
||||
"Start time of the process since unix epoch in seconds.",
|
||||
nil, nil,
|
||||
),
|
||||
}
|
||||
|
||||
if opts.PidFn == nil {
|
||||
pid := os.Getpid()
|
||||
c.pidFn = func() (int, error) { return pid, nil }
|
||||
} else {
|
||||
c.pidFn = opts.PidFn
|
||||
}
|
||||
|
||||
// Set up process metric collection if supported by the runtime.
|
||||
if _, err := procfs.NewStat(); err == nil {
|
||||
c.collectFn = c.processCollect
|
||||
} else {
|
||||
c.collectFn = func(ch chan<- Metric) {
|
||||
c.reportError(ch, nil, errors.New("process metrics not supported on this platform"))
|
||||
}
|
||||
}
|
||||
|
||||
return c
|
||||
}
|
||||
|
||||
// Describe returns all descriptions of the collector.
|
||||
func (c *processCollector) Describe(ch chan<- *Desc) {
|
||||
ch <- c.cpuTotal
|
||||
ch <- c.openFDs
|
||||
ch <- c.maxFDs
|
||||
ch <- c.vsize
|
||||
ch <- c.maxVsize
|
||||
ch <- c.rss
|
||||
ch <- c.startTime
|
||||
}
|
||||
|
||||
// Collect returns the current state of all metrics of the collector.
|
||||
func (c *processCollector) Collect(ch chan<- Metric) {
|
||||
c.collectFn(ch)
|
||||
}
|
||||
|
||||
func (c *processCollector) processCollect(ch chan<- Metric) {
|
||||
pid, err := c.pidFn()
|
||||
if err != nil {
|
||||
c.reportError(ch, nil, err)
|
||||
return
|
||||
}
|
||||
|
||||
p, err := procfs.NewProc(pid)
|
||||
if err != nil {
|
||||
c.reportError(ch, nil, err)
|
||||
return
|
||||
}
|
||||
|
||||
if stat, err := p.NewStat(); err == nil {
|
||||
ch <- MustNewConstMetric(c.cpuTotal, CounterValue, stat.CPUTime())
|
||||
ch <- MustNewConstMetric(c.vsize, GaugeValue, float64(stat.VirtualMemory()))
|
||||
ch <- MustNewConstMetric(c.rss, GaugeValue, float64(stat.ResidentMemory()))
|
||||
if startTime, err := stat.StartTime(); err == nil {
|
||||
ch <- MustNewConstMetric(c.startTime, GaugeValue, startTime)
|
||||
} else {
|
||||
c.reportError(ch, c.startTime, err)
|
||||
}
|
||||
} else {
|
||||
c.reportError(ch, nil, err)
|
||||
}
|
||||
|
||||
if fds, err := p.FileDescriptorsLen(); err == nil {
|
||||
ch <- MustNewConstMetric(c.openFDs, GaugeValue, float64(fds))
|
||||
} else {
|
||||
c.reportError(ch, c.openFDs, err)
|
||||
}
|
||||
|
||||
if limits, err := p.NewLimits(); err == nil {
|
||||
ch <- MustNewConstMetric(c.maxFDs, GaugeValue, float64(limits.OpenFiles))
|
||||
ch <- MustNewConstMetric(c.maxVsize, GaugeValue, float64(limits.AddressSpace))
|
||||
} else {
|
||||
c.reportError(ch, nil, err)
|
||||
}
|
||||
}
|
||||
|
||||
func (c *processCollector) reportError(ch chan<- Metric, desc *Desc, err error) {
|
||||
if !c.reportErrors {
|
||||
return
|
||||
}
|
||||
if desc == nil {
|
||||
desc = NewInvalidDesc(err)
|
||||
}
|
||||
ch <- NewInvalidMetric(desc, err)
|
||||
}
|
||||
223
watchdog/vendor/github.com/prometheus/client_golang/prometheus/promauto/auto.go
generated
vendored
223
watchdog/vendor/github.com/prometheus/client_golang/prometheus/promauto/auto.go
generated
vendored
@ -1,223 +0,0 @@
|
||||
// Copyright 2018 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
// Package promauto provides constructors for the usual Prometheus metrics that
|
||||
// return them already registered with the global registry
|
||||
// (prometheus.DefaultRegisterer). This allows very compact code, avoiding any
|
||||
// references to the registry altogether, but all the constructors in this
|
||||
// package will panic if the registration fails.
|
||||
//
|
||||
// The following example is a complete program to create a histogram of normally
|
||||
// distributed random numbers from the math/rand package:
|
||||
//
|
||||
// package main
|
||||
//
|
||||
// import (
|
||||
// "math/rand"
|
||||
// "net/http"
|
||||
//
|
||||
// "github.com/prometheus/client_golang/prometheus"
|
||||
// "github.com/prometheus/client_golang/prometheus/promauto"
|
||||
// "github.com/prometheus/client_golang/prometheus/promhttp"
|
||||
// )
|
||||
//
|
||||
// var histogram = promauto.NewHistogram(prometheus.HistogramOpts{
|
||||
// Name: "random_numbers",
|
||||
// Help: "A histogram of normally distributed random numbers.",
|
||||
// Buckets: prometheus.LinearBuckets(-3, .1, 61),
|
||||
// })
|
||||
//
|
||||
// func Random() {
|
||||
// for {
|
||||
// histogram.Observe(rand.NormFloat64())
|
||||
// }
|
||||
// }
|
||||
//
|
||||
// func main() {
|
||||
// go Random()
|
||||
// http.Handle("/metrics", promhttp.Handler())
|
||||
// http.ListenAndServe(":1971", nil)
|
||||
// }
|
||||
//
|
||||
// Prometheus's version of a minimal hello-world program:
|
||||
//
|
||||
// package main
|
||||
//
|
||||
// import (
|
||||
// "fmt"
|
||||
// "net/http"
|
||||
//
|
||||
// "github.com/prometheus/client_golang/prometheus"
|
||||
// "github.com/prometheus/client_golang/prometheus/promauto"
|
||||
// "github.com/prometheus/client_golang/prometheus/promhttp"
|
||||
// )
|
||||
//
|
||||
// func main() {
|
||||
// http.Handle("/", promhttp.InstrumentHandlerCounter(
|
||||
// promauto.NewCounterVec(
|
||||
// prometheus.CounterOpts{
|
||||
// Name: "hello_requests_total",
|
||||
// Help: "Total number of hello-world requests by HTTP code.",
|
||||
// },
|
||||
// []string{"code"},
|
||||
// ),
|
||||
// http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
// fmt.Fprint(w, "Hello, world!")
|
||||
// }),
|
||||
// ))
|
||||
// http.Handle("/metrics", promhttp.Handler())
|
||||
// http.ListenAndServe(":1971", nil)
|
||||
// }
|
||||
//
|
||||
// This appears very handy. So why are these constructors locked away in a
|
||||
// separate package? There are two caveats:
|
||||
//
|
||||
// First, in more complex programs, global state is often quite problematic.
|
||||
// That's the reason why the metrics constructors in the prometheus package do
|
||||
// not interact with the global prometheus.DefaultRegisterer on their own. You
|
||||
// are free to use the Register or MustRegister functions to register them with
|
||||
// the global prometheus.DefaultRegisterer, but you could as well choose a local
|
||||
// Registerer (usually created with prometheus.NewRegistry, but there are other
|
||||
// scenarios, e.g. testing).
|
||||
//
|
||||
// The second issue is that registration may fail, e.g. if a metric inconsistent
|
||||
// with the newly to be registered one is already registered. But how to signal
|
||||
// and handle a panic in the automatic registration with the default registry?
|
||||
// The only way is panicking. While panicking on invalid input provided by the
|
||||
// programmer is certainly fine, things are a bit more subtle in this case: You
|
||||
// might just add another package to the program, and that package (in its init
|
||||
// function) happens to register a metric with the same name as your code. Now,
|
||||
// all of a sudden, either your code or the code of the newly imported package
|
||||
// panics, depending on initialization order, without any opportunity to handle
|
||||
// the case gracefully. Even worse is a scenario where registration happens
|
||||
// later during the runtime (e.g. upon loading some kind of plugin), where the
|
||||
// panic could be triggered long after the code has been deployed to
|
||||
// production. A possibility to panic should be explicitly called out by the
|
||||
// Must… idiom, cf. prometheus.MustRegister. But adding a separate set of
|
||||
// constructors in the prometheus package called MustRegisterNewCounterVec or
|
||||
// similar would be quite unwieldy. Adding an extra MustRegister method to each
|
||||
// metric, returning the registered metric, would result in nice code for those
|
||||
// using the method, but would pollute every single metric interface for
|
||||
// everybody avoiding the global registry.
|
||||
//
|
||||
// To address both issues, the problematic auto-registering and possibly
|
||||
// panicking constructors are all in this package with a clear warning
|
||||
// ahead. And whoever cares about avoiding global state and possibly panicking
|
||||
// function calls can simply ignore the existence of the promauto package
|
||||
// altogether.
|
||||
//
|
||||
// A final note: There is a similar case in the net/http package of the standard
|
||||
// library. It has DefaultServeMux as a global instance of ServeMux, and the
|
||||
// Handle function acts on it, panicking if a handler for the same pattern has
|
||||
// already been registered. However, one might argue that the whole HTTP routing
|
||||
// is usually set up closely together in the same package or file, while
|
||||
// Prometheus metrics tend to be spread widely over the codebase, increasing the
|
||||
// chance of surprising registration failures. Furthermore, the use of global
|
||||
// state in net/http has been criticized widely, and some avoid it altogether.
|
||||
package promauto
|
||||
|
||||
import "github.com/prometheus/client_golang/prometheus"
|
||||
|
||||
// NewCounter works like the function of the same name in the prometheus package
|
||||
// but it automatically registers the Counter with the
|
||||
// prometheus.DefaultRegisterer. If the registration fails, NewCounter panics.
|
||||
func NewCounter(opts prometheus.CounterOpts) prometheus.Counter {
|
||||
c := prometheus.NewCounter(opts)
|
||||
prometheus.MustRegister(c)
|
||||
return c
|
||||
}
|
||||
|
||||
// NewCounterVec works like the function of the same name in the prometheus
|
||||
// package but it automatically registers the CounterVec with the
|
||||
// prometheus.DefaultRegisterer. If the registration fails, NewCounterVec
|
||||
// panics.
|
||||
func NewCounterVec(opts prometheus.CounterOpts, labelNames []string) *prometheus.CounterVec {
|
||||
c := prometheus.NewCounterVec(opts, labelNames)
|
||||
prometheus.MustRegister(c)
|
||||
return c
|
||||
}
|
||||
|
||||
// NewCounterFunc works like the function of the same name in the prometheus
|
||||
// package but it automatically registers the CounterFunc with the
|
||||
// prometheus.DefaultRegisterer. If the registration fails, NewCounterFunc
|
||||
// panics.
|
||||
func NewCounterFunc(opts prometheus.CounterOpts, function func() float64) prometheus.CounterFunc {
|
||||
g := prometheus.NewCounterFunc(opts, function)
|
||||
prometheus.MustRegister(g)
|
||||
return g
|
||||
}
|
||||
|
||||
// NewGauge works like the function of the same name in the prometheus package
|
||||
// but it automatically registers the Gauge with the
|
||||
// prometheus.DefaultRegisterer. If the registration fails, NewGauge panics.
|
||||
func NewGauge(opts prometheus.GaugeOpts) prometheus.Gauge {
|
||||
g := prometheus.NewGauge(opts)
|
||||
prometheus.MustRegister(g)
|
||||
return g
|
||||
}
|
||||
|
||||
// NewGaugeVec works like the function of the same name in the prometheus
|
||||
// package but it automatically registers the GaugeVec with the
|
||||
// prometheus.DefaultRegisterer. If the registration fails, NewGaugeVec panics.
|
||||
func NewGaugeVec(opts prometheus.GaugeOpts, labelNames []string) *prometheus.GaugeVec {
|
||||
g := prometheus.NewGaugeVec(opts, labelNames)
|
||||
prometheus.MustRegister(g)
|
||||
return g
|
||||
}
|
||||
|
||||
// NewGaugeFunc works like the function of the same name in the prometheus
|
||||
// package but it automatically registers the GaugeFunc with the
|
||||
// prometheus.DefaultRegisterer. If the registration fails, NewGaugeFunc panics.
|
||||
func NewGaugeFunc(opts prometheus.GaugeOpts, function func() float64) prometheus.GaugeFunc {
|
||||
g := prometheus.NewGaugeFunc(opts, function)
|
||||
prometheus.MustRegister(g)
|
||||
return g
|
||||
}
|
||||
|
||||
// NewSummary works like the function of the same name in the prometheus package
|
||||
// but it automatically registers the Summary with the
|
||||
// prometheus.DefaultRegisterer. If the registration fails, NewSummary panics.
|
||||
func NewSummary(opts prometheus.SummaryOpts) prometheus.Summary {
|
||||
s := prometheus.NewSummary(opts)
|
||||
prometheus.MustRegister(s)
|
||||
return s
|
||||
}
|
||||
|
||||
// NewSummaryVec works like the function of the same name in the prometheus
|
||||
// package but it automatically registers the SummaryVec with the
|
||||
// prometheus.DefaultRegisterer. If the registration fails, NewSummaryVec
|
||||
// panics.
|
||||
func NewSummaryVec(opts prometheus.SummaryOpts, labelNames []string) *prometheus.SummaryVec {
|
||||
s := prometheus.NewSummaryVec(opts, labelNames)
|
||||
prometheus.MustRegister(s)
|
||||
return s
|
||||
}
|
||||
|
||||
// NewHistogram works like the function of the same name in the prometheus
|
||||
// package but it automatically registers the Histogram with the
|
||||
// prometheus.DefaultRegisterer. If the registration fails, NewHistogram panics.
|
||||
func NewHistogram(opts prometheus.HistogramOpts) prometheus.Histogram {
|
||||
h := prometheus.NewHistogram(opts)
|
||||
prometheus.MustRegister(h)
|
||||
return h
|
||||
}
|
||||
|
||||
// NewHistogramVec works like the function of the same name in the prometheus
|
||||
// package but it automatically registers the HistogramVec with the
|
||||
// prometheus.DefaultRegisterer. If the registration fails, NewHistogramVec
|
||||
// panics.
|
||||
func NewHistogramVec(opts prometheus.HistogramOpts, labelNames []string) *prometheus.HistogramVec {
|
||||
h := prometheus.NewHistogramVec(opts, labelNames)
|
||||
prometheus.MustRegister(h)
|
||||
return h
|
||||
}
|
||||
199
watchdog/vendor/github.com/prometheus/client_golang/prometheus/promhttp/delegator.go
generated
vendored
199
watchdog/vendor/github.com/prometheus/client_golang/prometheus/promhttp/delegator.go
generated
vendored
@ -1,199 +0,0 @@
|
||||
// Copyright 2017 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package promhttp
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"io"
|
||||
"net"
|
||||
"net/http"
|
||||
)
|
||||
|
||||
const (
|
||||
closeNotifier = 1 << iota
|
||||
flusher
|
||||
hijacker
|
||||
readerFrom
|
||||
pusher
|
||||
)
|
||||
|
||||
type delegator interface {
|
||||
http.ResponseWriter
|
||||
|
||||
Status() int
|
||||
Written() int64
|
||||
}
|
||||
|
||||
type responseWriterDelegator struct {
|
||||
http.ResponseWriter
|
||||
|
||||
handler, method string
|
||||
status int
|
||||
written int64
|
||||
wroteHeader bool
|
||||
observeWriteHeader func(int)
|
||||
}
|
||||
|
||||
func (r *responseWriterDelegator) Status() int {
|
||||
return r.status
|
||||
}
|
||||
|
||||
func (r *responseWriterDelegator) Written() int64 {
|
||||
return r.written
|
||||
}
|
||||
|
||||
func (r *responseWriterDelegator) WriteHeader(code int) {
|
||||
r.status = code
|
||||
r.wroteHeader = true
|
||||
r.ResponseWriter.WriteHeader(code)
|
||||
if r.observeWriteHeader != nil {
|
||||
r.observeWriteHeader(code)
|
||||
}
|
||||
}
|
||||
|
||||
func (r *responseWriterDelegator) Write(b []byte) (int, error) {
|
||||
if !r.wroteHeader {
|
||||
r.WriteHeader(http.StatusOK)
|
||||
}
|
||||
n, err := r.ResponseWriter.Write(b)
|
||||
r.written += int64(n)
|
||||
return n, err
|
||||
}
|
||||
|
||||
type closeNotifierDelegator struct{ *responseWriterDelegator }
|
||||
type flusherDelegator struct{ *responseWriterDelegator }
|
||||
type hijackerDelegator struct{ *responseWriterDelegator }
|
||||
type readerFromDelegator struct{ *responseWriterDelegator }
|
||||
|
||||
func (d closeNotifierDelegator) CloseNotify() <-chan bool {
|
||||
return d.ResponseWriter.(http.CloseNotifier).CloseNotify()
|
||||
}
|
||||
func (d flusherDelegator) Flush() {
|
||||
d.ResponseWriter.(http.Flusher).Flush()
|
||||
}
|
||||
func (d hijackerDelegator) Hijack() (net.Conn, *bufio.ReadWriter, error) {
|
||||
return d.ResponseWriter.(http.Hijacker).Hijack()
|
||||
}
|
||||
func (d readerFromDelegator) ReadFrom(re io.Reader) (int64, error) {
|
||||
if !d.wroteHeader {
|
||||
d.WriteHeader(http.StatusOK)
|
||||
}
|
||||
n, err := d.ResponseWriter.(io.ReaderFrom).ReadFrom(re)
|
||||
d.written += n
|
||||
return n, err
|
||||
}
|
||||
|
||||
var pickDelegator = make([]func(*responseWriterDelegator) delegator, 32)
|
||||
|
||||
func init() {
|
||||
// TODO(beorn7): Code generation would help here.
|
||||
pickDelegator[0] = func(d *responseWriterDelegator) delegator { // 0
|
||||
return d
|
||||
}
|
||||
pickDelegator[closeNotifier] = func(d *responseWriterDelegator) delegator { // 1
|
||||
return closeNotifierDelegator{d}
|
||||
}
|
||||
pickDelegator[flusher] = func(d *responseWriterDelegator) delegator { // 2
|
||||
return flusherDelegator{d}
|
||||
}
|
||||
pickDelegator[flusher+closeNotifier] = func(d *responseWriterDelegator) delegator { // 3
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Flusher
|
||||
http.CloseNotifier
|
||||
}{d, flusherDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[hijacker] = func(d *responseWriterDelegator) delegator { // 4
|
||||
return hijackerDelegator{d}
|
||||
}
|
||||
pickDelegator[hijacker+closeNotifier] = func(d *responseWriterDelegator) delegator { // 5
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Hijacker
|
||||
http.CloseNotifier
|
||||
}{d, hijackerDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[hijacker+flusher] = func(d *responseWriterDelegator) delegator { // 6
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Hijacker
|
||||
http.Flusher
|
||||
}{d, hijackerDelegator{d}, flusherDelegator{d}}
|
||||
}
|
||||
pickDelegator[hijacker+flusher+closeNotifier] = func(d *responseWriterDelegator) delegator { // 7
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Hijacker
|
||||
http.Flusher
|
||||
http.CloseNotifier
|
||||
}{d, hijackerDelegator{d}, flusherDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[readerFrom] = func(d *responseWriterDelegator) delegator { // 8
|
||||
return readerFromDelegator{d}
|
||||
}
|
||||
pickDelegator[readerFrom+closeNotifier] = func(d *responseWriterDelegator) delegator { // 9
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
io.ReaderFrom
|
||||
http.CloseNotifier
|
||||
}{d, readerFromDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[readerFrom+flusher] = func(d *responseWriterDelegator) delegator { // 10
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
io.ReaderFrom
|
||||
http.Flusher
|
||||
}{d, readerFromDelegator{d}, flusherDelegator{d}}
|
||||
}
|
||||
pickDelegator[readerFrom+flusher+closeNotifier] = func(d *responseWriterDelegator) delegator { // 11
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
io.ReaderFrom
|
||||
http.Flusher
|
||||
http.CloseNotifier
|
||||
}{d, readerFromDelegator{d}, flusherDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[readerFrom+hijacker] = func(d *responseWriterDelegator) delegator { // 12
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
io.ReaderFrom
|
||||
http.Hijacker
|
||||
}{d, readerFromDelegator{d}, hijackerDelegator{d}}
|
||||
}
|
||||
pickDelegator[readerFrom+hijacker+closeNotifier] = func(d *responseWriterDelegator) delegator { // 13
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
io.ReaderFrom
|
||||
http.Hijacker
|
||||
http.CloseNotifier
|
||||
}{d, readerFromDelegator{d}, hijackerDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[readerFrom+hijacker+flusher] = func(d *responseWriterDelegator) delegator { // 14
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
io.ReaderFrom
|
||||
http.Hijacker
|
||||
http.Flusher
|
||||
}{d, readerFromDelegator{d}, hijackerDelegator{d}, flusherDelegator{d}}
|
||||
}
|
||||
pickDelegator[readerFrom+hijacker+flusher+closeNotifier] = func(d *responseWriterDelegator) delegator { // 15
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
io.ReaderFrom
|
||||
http.Hijacker
|
||||
http.Flusher
|
||||
http.CloseNotifier
|
||||
}{d, readerFromDelegator{d}, hijackerDelegator{d}, flusherDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
}
|
||||
181
watchdog/vendor/github.com/prometheus/client_golang/prometheus/promhttp/delegator_1_8.go
generated
vendored
181
watchdog/vendor/github.com/prometheus/client_golang/prometheus/promhttp/delegator_1_8.go
generated
vendored
@ -1,181 +0,0 @@
|
||||
// Copyright 2017 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
// +build go1.8
|
||||
|
||||
package promhttp
|
||||
|
||||
import (
|
||||
"io"
|
||||
"net/http"
|
||||
)
|
||||
|
||||
type pusherDelegator struct{ *responseWriterDelegator }
|
||||
|
||||
func (d pusherDelegator) Push(target string, opts *http.PushOptions) error {
|
||||
return d.ResponseWriter.(http.Pusher).Push(target, opts)
|
||||
}
|
||||
|
||||
func init() {
|
||||
pickDelegator[pusher] = func(d *responseWriterDelegator) delegator { // 16
|
||||
return pusherDelegator{d}
|
||||
}
|
||||
pickDelegator[pusher+closeNotifier] = func(d *responseWriterDelegator) delegator { // 17
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
http.CloseNotifier
|
||||
}{d, pusherDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+flusher] = func(d *responseWriterDelegator) delegator { // 18
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
http.Flusher
|
||||
}{d, pusherDelegator{d}, flusherDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+flusher+closeNotifier] = func(d *responseWriterDelegator) delegator { // 19
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
http.Flusher
|
||||
http.CloseNotifier
|
||||
}{d, pusherDelegator{d}, flusherDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+hijacker] = func(d *responseWriterDelegator) delegator { // 20
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
http.Hijacker
|
||||
}{d, pusherDelegator{d}, hijackerDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+hijacker+closeNotifier] = func(d *responseWriterDelegator) delegator { // 21
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
http.Hijacker
|
||||
http.CloseNotifier
|
||||
}{d, pusherDelegator{d}, hijackerDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+hijacker+flusher] = func(d *responseWriterDelegator) delegator { // 22
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
http.Hijacker
|
||||
http.Flusher
|
||||
}{d, pusherDelegator{d}, hijackerDelegator{d}, flusherDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+hijacker+flusher+closeNotifier] = func(d *responseWriterDelegator) delegator { //23
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
http.Hijacker
|
||||
http.Flusher
|
||||
http.CloseNotifier
|
||||
}{d, pusherDelegator{d}, hijackerDelegator{d}, flusherDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+readerFrom] = func(d *responseWriterDelegator) delegator { // 24
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
io.ReaderFrom
|
||||
}{d, pusherDelegator{d}, readerFromDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+readerFrom+closeNotifier] = func(d *responseWriterDelegator) delegator { // 25
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
io.ReaderFrom
|
||||
http.CloseNotifier
|
||||
}{d, pusherDelegator{d}, readerFromDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+readerFrom+flusher] = func(d *responseWriterDelegator) delegator { // 26
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
io.ReaderFrom
|
||||
http.Flusher
|
||||
}{d, pusherDelegator{d}, readerFromDelegator{d}, flusherDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+readerFrom+flusher+closeNotifier] = func(d *responseWriterDelegator) delegator { // 27
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
io.ReaderFrom
|
||||
http.Flusher
|
||||
http.CloseNotifier
|
||||
}{d, pusherDelegator{d}, readerFromDelegator{d}, flusherDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+readerFrom+hijacker] = func(d *responseWriterDelegator) delegator { // 28
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
io.ReaderFrom
|
||||
http.Hijacker
|
||||
}{d, pusherDelegator{d}, readerFromDelegator{d}, hijackerDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+readerFrom+hijacker+closeNotifier] = func(d *responseWriterDelegator) delegator { // 29
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
io.ReaderFrom
|
||||
http.Hijacker
|
||||
http.CloseNotifier
|
||||
}{d, pusherDelegator{d}, readerFromDelegator{d}, hijackerDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+readerFrom+hijacker+flusher] = func(d *responseWriterDelegator) delegator { // 30
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
io.ReaderFrom
|
||||
http.Hijacker
|
||||
http.Flusher
|
||||
}{d, pusherDelegator{d}, readerFromDelegator{d}, hijackerDelegator{d}, flusherDelegator{d}}
|
||||
}
|
||||
pickDelegator[pusher+readerFrom+hijacker+flusher+closeNotifier] = func(d *responseWriterDelegator) delegator { // 31
|
||||
return struct {
|
||||
*responseWriterDelegator
|
||||
http.Pusher
|
||||
io.ReaderFrom
|
||||
http.Hijacker
|
||||
http.Flusher
|
||||
http.CloseNotifier
|
||||
}{d, pusherDelegator{d}, readerFromDelegator{d}, hijackerDelegator{d}, flusherDelegator{d}, closeNotifierDelegator{d}}
|
||||
}
|
||||
}
|
||||
|
||||
func newDelegator(w http.ResponseWriter, observeWriteHeaderFunc func(int)) delegator {
|
||||
d := &responseWriterDelegator{
|
||||
ResponseWriter: w,
|
||||
observeWriteHeader: observeWriteHeaderFunc,
|
||||
}
|
||||
|
||||
id := 0
|
||||
if _, ok := w.(http.CloseNotifier); ok {
|
||||
id += closeNotifier
|
||||
}
|
||||
if _, ok := w.(http.Flusher); ok {
|
||||
id += flusher
|
||||
}
|
||||
if _, ok := w.(http.Hijacker); ok {
|
||||
id += hijacker
|
||||
}
|
||||
if _, ok := w.(io.ReaderFrom); ok {
|
||||
id += readerFrom
|
||||
}
|
||||
if _, ok := w.(http.Pusher); ok {
|
||||
id += pusher
|
||||
}
|
||||
|
||||
return pickDelegator[id](d)
|
||||
}
|
||||
@ -1,44 +0,0 @@
|
||||
// Copyright 2017 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
// +build !go1.8
|
||||
|
||||
package promhttp
|
||||
|
||||
import (
|
||||
"io"
|
||||
"net/http"
|
||||
)
|
||||
|
||||
func newDelegator(w http.ResponseWriter, observeWriteHeaderFunc func(int)) delegator {
|
||||
d := &responseWriterDelegator{
|
||||
ResponseWriter: w,
|
||||
observeWriteHeader: observeWriteHeaderFunc,
|
||||
}
|
||||
|
||||
id := 0
|
||||
if _, ok := w.(http.CloseNotifier); ok {
|
||||
id += closeNotifier
|
||||
}
|
||||
if _, ok := w.(http.Flusher); ok {
|
||||
id += flusher
|
||||
}
|
||||
if _, ok := w.(http.Hijacker); ok {
|
||||
id += hijacker
|
||||
}
|
||||
if _, ok := w.(io.ReaderFrom); ok {
|
||||
id += readerFrom
|
||||
}
|
||||
|
||||
return pickDelegator[id](d)
|
||||
}
|
||||
311
watchdog/vendor/github.com/prometheus/client_golang/prometheus/promhttp/http.go
generated
vendored
311
watchdog/vendor/github.com/prometheus/client_golang/prometheus/promhttp/http.go
generated
vendored
@ -1,311 +0,0 @@
|
||||
// Copyright 2016 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
// Package promhttp provides tooling around HTTP servers and clients.
|
||||
//
|
||||
// First, the package allows the creation of http.Handler instances to expose
|
||||
// Prometheus metrics via HTTP. promhttp.Handler acts on the
|
||||
// prometheus.DefaultGatherer. With HandlerFor, you can create a handler for a
|
||||
// custom registry or anything that implements the Gatherer interface. It also
|
||||
// allows the creation of handlers that act differently on errors or allow to
|
||||
// log errors.
|
||||
//
|
||||
// Second, the package provides tooling to instrument instances of http.Handler
|
||||
// via middleware. Middleware wrappers follow the naming scheme
|
||||
// InstrumentHandlerX, where X describes the intended use of the middleware.
|
||||
// See each function's doc comment for specific details.
|
||||
//
|
||||
// Finally, the package allows for an http.RoundTripper to be instrumented via
|
||||
// middleware. Middleware wrappers follow the naming scheme
|
||||
// InstrumentRoundTripperX, where X describes the intended use of the
|
||||
// middleware. See each function's doc comment for specific details.
|
||||
package promhttp
|
||||
|
||||
import (
|
||||
"compress/gzip"
|
||||
"fmt"
|
||||
"io"
|
||||
"net/http"
|
||||
"strings"
|
||||
"sync"
|
||||
"time"
|
||||
|
||||
"github.com/prometheus/common/expfmt"
|
||||
|
||||
"github.com/prometheus/client_golang/prometheus"
|
||||
)
|
||||
|
||||
const (
|
||||
contentTypeHeader = "Content-Type"
|
||||
contentLengthHeader = "Content-Length"
|
||||
contentEncodingHeader = "Content-Encoding"
|
||||
acceptEncodingHeader = "Accept-Encoding"
|
||||
)
|
||||
|
||||
var gzipPool = sync.Pool{
|
||||
New: func() interface{} {
|
||||
return gzip.NewWriter(nil)
|
||||
},
|
||||
}
|
||||
|
||||
// Handler returns an http.Handler for the prometheus.DefaultGatherer, using
|
||||
// default HandlerOpts, i.e. it reports the first error as an HTTP error, it has
|
||||
// no error logging, and it applies compression if requested by the client.
|
||||
//
|
||||
// The returned http.Handler is already instrumented using the
|
||||
// InstrumentMetricHandler function and the prometheus.DefaultRegisterer. If you
|
||||
// create multiple http.Handlers by separate calls of the Handler function, the
|
||||
// metrics used for instrumentation will be shared between them, providing
|
||||
// global scrape counts.
|
||||
//
|
||||
// This function is meant to cover the bulk of basic use cases. If you are doing
|
||||
// anything that requires more customization (including using a non-default
|
||||
// Gatherer, different instrumentation, and non-default HandlerOpts), use the
|
||||
// HandlerFor function. See there for details.
|
||||
func Handler() http.Handler {
|
||||
return InstrumentMetricHandler(
|
||||
prometheus.DefaultRegisterer, HandlerFor(prometheus.DefaultGatherer, HandlerOpts{}),
|
||||
)
|
||||
}
|
||||
|
||||
// HandlerFor returns an uninstrumented http.Handler for the provided
|
||||
// Gatherer. The behavior of the Handler is defined by the provided
|
||||
// HandlerOpts. Thus, HandlerFor is useful to create http.Handlers for custom
|
||||
// Gatherers, with non-default HandlerOpts, and/or with custom (or no)
|
||||
// instrumentation. Use the InstrumentMetricHandler function to apply the same
|
||||
// kind of instrumentation as it is used by the Handler function.
|
||||
func HandlerFor(reg prometheus.Gatherer, opts HandlerOpts) http.Handler {
|
||||
var inFlightSem chan struct{}
|
||||
if opts.MaxRequestsInFlight > 0 {
|
||||
inFlightSem = make(chan struct{}, opts.MaxRequestsInFlight)
|
||||
}
|
||||
|
||||
h := http.HandlerFunc(func(rsp http.ResponseWriter, req *http.Request) {
|
||||
if inFlightSem != nil {
|
||||
select {
|
||||
case inFlightSem <- struct{}{}: // All good, carry on.
|
||||
defer func() { <-inFlightSem }()
|
||||
default:
|
||||
http.Error(rsp, fmt.Sprintf(
|
||||
"Limit of concurrent requests reached (%d), try again later.", opts.MaxRequestsInFlight,
|
||||
), http.StatusServiceUnavailable)
|
||||
return
|
||||
}
|
||||
}
|
||||
mfs, err := reg.Gather()
|
||||
if err != nil {
|
||||
if opts.ErrorLog != nil {
|
||||
opts.ErrorLog.Println("error gathering metrics:", err)
|
||||
}
|
||||
switch opts.ErrorHandling {
|
||||
case PanicOnError:
|
||||
panic(err)
|
||||
case ContinueOnError:
|
||||
if len(mfs) == 0 {
|
||||
// Still report the error if no metrics have been gathered.
|
||||
httpError(rsp, err)
|
||||
return
|
||||
}
|
||||
case HTTPErrorOnError:
|
||||
httpError(rsp, err)
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
contentType := expfmt.Negotiate(req.Header)
|
||||
header := rsp.Header()
|
||||
header.Set(contentTypeHeader, string(contentType))
|
||||
|
||||
w := io.Writer(rsp)
|
||||
if !opts.DisableCompression && gzipAccepted(req.Header) {
|
||||
header.Set(contentEncodingHeader, "gzip")
|
||||
gz := gzipPool.Get().(*gzip.Writer)
|
||||
defer gzipPool.Put(gz)
|
||||
|
||||
gz.Reset(w)
|
||||
defer gz.Close()
|
||||
|
||||
w = gz
|
||||
}
|
||||
|
||||
enc := expfmt.NewEncoder(w, contentType)
|
||||
|
||||
var lastErr error
|
||||
for _, mf := range mfs {
|
||||
if err := enc.Encode(mf); err != nil {
|
||||
lastErr = err
|
||||
if opts.ErrorLog != nil {
|
||||
opts.ErrorLog.Println("error encoding and sending metric family:", err)
|
||||
}
|
||||
switch opts.ErrorHandling {
|
||||
case PanicOnError:
|
||||
panic(err)
|
||||
case ContinueOnError:
|
||||
// Handled later.
|
||||
case HTTPErrorOnError:
|
||||
httpError(rsp, err)
|
||||
return
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if lastErr != nil {
|
||||
httpError(rsp, lastErr)
|
||||
}
|
||||
})
|
||||
|
||||
if opts.Timeout <= 0 {
|
||||
return h
|
||||
}
|
||||
return http.TimeoutHandler(h, opts.Timeout, fmt.Sprintf(
|
||||
"Exceeded configured timeout of %v.\n",
|
||||
opts.Timeout,
|
||||
))
|
||||
}
|
||||
|
||||
// InstrumentMetricHandler is usually used with an http.Handler returned by the
|
||||
// HandlerFor function. It instruments the provided http.Handler with two
|
||||
// metrics: A counter vector "promhttp_metric_handler_requests_total" to count
|
||||
// scrapes partitioned by HTTP status code, and a gauge
|
||||
// "promhttp_metric_handler_requests_in_flight" to track the number of
|
||||
// simultaneous scrapes. This function idempotently registers collectors for
|
||||
// both metrics with the provided Registerer. It panics if the registration
|
||||
// fails. The provided metrics are useful to see how many scrapes hit the
|
||||
// monitored target (which could be from different Prometheus servers or other
|
||||
// scrapers), and how often they overlap (which would result in more than one
|
||||
// scrape in flight at the same time). Note that the scrapes-in-flight gauge
|
||||
// will contain the scrape by which it is exposed, while the scrape counter will
|
||||
// only get incremented after the scrape is complete (as only then the status
|
||||
// code is known). For tracking scrape durations, use the
|
||||
// "scrape_duration_seconds" gauge created by the Prometheus server upon each
|
||||
// scrape.
|
||||
func InstrumentMetricHandler(reg prometheus.Registerer, handler http.Handler) http.Handler {
|
||||
cnt := prometheus.NewCounterVec(
|
||||
prometheus.CounterOpts{
|
||||
Name: "promhttp_metric_handler_requests_total",
|
||||
Help: "Total number of scrapes by HTTP status code.",
|
||||
},
|
||||
[]string{"code"},
|
||||
)
|
||||
// Initialize the most likely HTTP status codes.
|
||||
cnt.WithLabelValues("200")
|
||||
cnt.WithLabelValues("500")
|
||||
cnt.WithLabelValues("503")
|
||||
if err := reg.Register(cnt); err != nil {
|
||||
if are, ok := err.(prometheus.AlreadyRegisteredError); ok {
|
||||
cnt = are.ExistingCollector.(*prometheus.CounterVec)
|
||||
} else {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
|
||||
gge := prometheus.NewGauge(prometheus.GaugeOpts{
|
||||
Name: "promhttp_metric_handler_requests_in_flight",
|
||||
Help: "Current number of scrapes being served.",
|
||||
})
|
||||
if err := reg.Register(gge); err != nil {
|
||||
if are, ok := err.(prometheus.AlreadyRegisteredError); ok {
|
||||
gge = are.ExistingCollector.(prometheus.Gauge)
|
||||
} else {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
|
||||
return InstrumentHandlerCounter(cnt, InstrumentHandlerInFlight(gge, handler))
|
||||
}
|
||||
|
||||
// HandlerErrorHandling defines how a Handler serving metrics will handle
|
||||
// errors.
|
||||
type HandlerErrorHandling int
|
||||
|
||||
// These constants cause handlers serving metrics to behave as described if
|
||||
// errors are encountered.
|
||||
const (
|
||||
// Serve an HTTP status code 500 upon the first error
|
||||
// encountered. Report the error message in the body.
|
||||
HTTPErrorOnError HandlerErrorHandling = iota
|
||||
// Ignore errors and try to serve as many metrics as possible. However,
|
||||
// if no metrics can be served, serve an HTTP status code 500 and the
|
||||
// last error message in the body. Only use this in deliberate "best
|
||||
// effort" metrics collection scenarios. It is recommended to at least
|
||||
// log errors (by providing an ErrorLog in HandlerOpts) to not mask
|
||||
// errors completely.
|
||||
ContinueOnError
|
||||
// Panic upon the first error encountered (useful for "crash only" apps).
|
||||
PanicOnError
|
||||
)
|
||||
|
||||
// Logger is the minimal interface HandlerOpts needs for logging. Note that
|
||||
// log.Logger from the standard library implements this interface, and it is
|
||||
// easy to implement by custom loggers, if they don't do so already anyway.
|
||||
type Logger interface {
|
||||
Println(v ...interface{})
|
||||
}
|
||||
|
||||
// HandlerOpts specifies options how to serve metrics via an http.Handler. The
|
||||
// zero value of HandlerOpts is a reasonable default.
|
||||
type HandlerOpts struct {
|
||||
// ErrorLog specifies an optional logger for errors collecting and
|
||||
// serving metrics. If nil, errors are not logged at all.
|
||||
ErrorLog Logger
|
||||
// ErrorHandling defines how errors are handled. Note that errors are
|
||||
// logged regardless of the configured ErrorHandling provided ErrorLog
|
||||
// is not nil.
|
||||
ErrorHandling HandlerErrorHandling
|
||||
// If DisableCompression is true, the handler will never compress the
|
||||
// response, even if requested by the client.
|
||||
DisableCompression bool
|
||||
// The number of concurrent HTTP requests is limited to
|
||||
// MaxRequestsInFlight. Additional requests are responded to with 503
|
||||
// Service Unavailable and a suitable message in the body. If
|
||||
// MaxRequestsInFlight is 0 or negative, no limit is applied.
|
||||
MaxRequestsInFlight int
|
||||
// If handling a request takes longer than Timeout, it is responded to
|
||||
// with 503 ServiceUnavailable and a suitable Message. No timeout is
|
||||
// applied if Timeout is 0 or negative. Note that with the current
|
||||
// implementation, reaching the timeout simply ends the HTTP requests as
|
||||
// described above (and even that only if sending of the body hasn't
|
||||
// started yet), while the bulk work of gathering all the metrics keeps
|
||||
// running in the background (with the eventual result to be thrown
|
||||
// away). Until the implementation is improved, it is recommended to
|
||||
// implement a separate timeout in potentially slow Collectors.
|
||||
Timeout time.Duration
|
||||
}
|
||||
|
||||
// gzipAccepted returns whether the client will accept gzip-encoded content.
|
||||
func gzipAccepted(header http.Header) bool {
|
||||
a := header.Get(acceptEncodingHeader)
|
||||
parts := strings.Split(a, ",")
|
||||
for _, part := range parts {
|
||||
part = strings.TrimSpace(part)
|
||||
if part == "gzip" || strings.HasPrefix(part, "gzip;") {
|
||||
return true
|
||||
}
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
// httpError removes any content-encoding header and then calls http.Error with
|
||||
// the provided error and http.StatusInternalServerErrer. Error contents is
|
||||
// supposed to be uncompressed plain text. However, same as with a plain
|
||||
// http.Error, any header settings will be void if the header has already been
|
||||
// sent. The error message will still be written to the writer, but it will
|
||||
// probably be of limited use.
|
||||
func httpError(rsp http.ResponseWriter, err error) {
|
||||
rsp.Header().Del(contentEncodingHeader)
|
||||
http.Error(
|
||||
rsp,
|
||||
"An error has occurred while serving metrics:\n\n"+err.Error(),
|
||||
http.StatusInternalServerError,
|
||||
)
|
||||
}
|
||||
@ -1,97 +0,0 @@
|
||||
// Copyright 2017 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package promhttp
|
||||
|
||||
import (
|
||||
"net/http"
|
||||
"time"
|
||||
|
||||
"github.com/prometheus/client_golang/prometheus"
|
||||
)
|
||||
|
||||
// The RoundTripperFunc type is an adapter to allow the use of ordinary
|
||||
// functions as RoundTrippers. If f is a function with the appropriate
|
||||
// signature, RountTripperFunc(f) is a RoundTripper that calls f.
|
||||
type RoundTripperFunc func(req *http.Request) (*http.Response, error)
|
||||
|
||||
// RoundTrip implements the RoundTripper interface.
|
||||
func (rt RoundTripperFunc) RoundTrip(r *http.Request) (*http.Response, error) {
|
||||
return rt(r)
|
||||
}
|
||||
|
||||
// InstrumentRoundTripperInFlight is a middleware that wraps the provided
|
||||
// http.RoundTripper. It sets the provided prometheus.Gauge to the number of
|
||||
// requests currently handled by the wrapped http.RoundTripper.
|
||||
//
|
||||
// See the example for ExampleInstrumentRoundTripperDuration for example usage.
|
||||
func InstrumentRoundTripperInFlight(gauge prometheus.Gauge, next http.RoundTripper) RoundTripperFunc {
|
||||
return RoundTripperFunc(func(r *http.Request) (*http.Response, error) {
|
||||
gauge.Inc()
|
||||
defer gauge.Dec()
|
||||
return next.RoundTrip(r)
|
||||
})
|
||||
}
|
||||
|
||||
// InstrumentRoundTripperCounter is a middleware that wraps the provided
|
||||
// http.RoundTripper to observe the request result with the provided CounterVec.
|
||||
// The CounterVec must have zero, one, or two non-const non-curried labels. For
|
||||
// those, the only allowed label names are "code" and "method". The function
|
||||
// panics otherwise. Partitioning of the CounterVec happens by HTTP status code
|
||||
// and/or HTTP method if the respective instance label names are present in the
|
||||
// CounterVec. For unpartitioned counting, use a CounterVec with zero labels.
|
||||
//
|
||||
// If the wrapped RoundTripper panics or returns a non-nil error, the Counter
|
||||
// is not incremented.
|
||||
//
|
||||
// See the example for ExampleInstrumentRoundTripperDuration for example usage.
|
||||
func InstrumentRoundTripperCounter(counter *prometheus.CounterVec, next http.RoundTripper) RoundTripperFunc {
|
||||
code, method := checkLabels(counter)
|
||||
|
||||
return RoundTripperFunc(func(r *http.Request) (*http.Response, error) {
|
||||
resp, err := next.RoundTrip(r)
|
||||
if err == nil {
|
||||
counter.With(labels(code, method, r.Method, resp.StatusCode)).Inc()
|
||||
}
|
||||
return resp, err
|
||||
})
|
||||
}
|
||||
|
||||
// InstrumentRoundTripperDuration is a middleware that wraps the provided
|
||||
// http.RoundTripper to observe the request duration with the provided
|
||||
// ObserverVec. The ObserverVec must have zero, one, or two non-const
|
||||
// non-curried labels. For those, the only allowed label names are "code" and
|
||||
// "method". The function panics otherwise. The Observe method of the Observer
|
||||
// in the ObserverVec is called with the request duration in
|
||||
// seconds. Partitioning happens by HTTP status code and/or HTTP method if the
|
||||
// respective instance label names are present in the ObserverVec. For
|
||||
// unpartitioned observations, use an ObserverVec with zero labels. Note that
|
||||
// partitioning of Histograms is expensive and should be used judiciously.
|
||||
//
|
||||
// If the wrapped RoundTripper panics or returns a non-nil error, no values are
|
||||
// reported.
|
||||
//
|
||||
// Note that this method is only guaranteed to never observe negative durations
|
||||
// if used with Go1.9+.
|
||||
func InstrumentRoundTripperDuration(obs prometheus.ObserverVec, next http.RoundTripper) RoundTripperFunc {
|
||||
code, method := checkLabels(obs)
|
||||
|
||||
return RoundTripperFunc(func(r *http.Request) (*http.Response, error) {
|
||||
start := time.Now()
|
||||
resp, err := next.RoundTrip(r)
|
||||
if err == nil {
|
||||
obs.With(labels(code, method, r.Method, resp.StatusCode)).Observe(time.Since(start).Seconds())
|
||||
}
|
||||
return resp, err
|
||||
})
|
||||
}
|
||||
@ -1,144 +0,0 @@
|
||||
// Copyright 2017 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
// +build go1.8
|
||||
|
||||
package promhttp
|
||||
|
||||
import (
|
||||
"context"
|
||||
"crypto/tls"
|
||||
"net/http"
|
||||
"net/http/httptrace"
|
||||
"time"
|
||||
)
|
||||
|
||||
// InstrumentTrace is used to offer flexibility in instrumenting the available
|
||||
// httptrace.ClientTrace hook functions. Each function is passed a float64
|
||||
// representing the time in seconds since the start of the http request. A user
|
||||
// may choose to use separately buckets Histograms, or implement custom
|
||||
// instance labels on a per function basis.
|
||||
type InstrumentTrace struct {
|
||||
GotConn func(float64)
|
||||
PutIdleConn func(float64)
|
||||
GotFirstResponseByte func(float64)
|
||||
Got100Continue func(float64)
|
||||
DNSStart func(float64)
|
||||
DNSDone func(float64)
|
||||
ConnectStart func(float64)
|
||||
ConnectDone func(float64)
|
||||
TLSHandshakeStart func(float64)
|
||||
TLSHandshakeDone func(float64)
|
||||
WroteHeaders func(float64)
|
||||
Wait100Continue func(float64)
|
||||
WroteRequest func(float64)
|
||||
}
|
||||
|
||||
// InstrumentRoundTripperTrace is a middleware that wraps the provided
|
||||
// RoundTripper and reports times to hook functions provided in the
|
||||
// InstrumentTrace struct. Hook functions that are not present in the provided
|
||||
// InstrumentTrace struct are ignored. Times reported to the hook functions are
|
||||
// time since the start of the request. Only with Go1.9+, those times are
|
||||
// guaranteed to never be negative. (Earlier Go versions are not using a
|
||||
// monotonic clock.) Note that partitioning of Histograms is expensive and
|
||||
// should be used judiciously.
|
||||
//
|
||||
// For hook functions that receive an error as an argument, no observations are
|
||||
// made in the event of a non-nil error value.
|
||||
//
|
||||
// See the example for ExampleInstrumentRoundTripperDuration for example usage.
|
||||
func InstrumentRoundTripperTrace(it *InstrumentTrace, next http.RoundTripper) RoundTripperFunc {
|
||||
return RoundTripperFunc(func(r *http.Request) (*http.Response, error) {
|
||||
start := time.Now()
|
||||
|
||||
trace := &httptrace.ClientTrace{
|
||||
GotConn: func(_ httptrace.GotConnInfo) {
|
||||
if it.GotConn != nil {
|
||||
it.GotConn(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
PutIdleConn: func(err error) {
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
if it.PutIdleConn != nil {
|
||||
it.PutIdleConn(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
DNSStart: func(_ httptrace.DNSStartInfo) {
|
||||
if it.DNSStart != nil {
|
||||
it.DNSStart(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
DNSDone: func(_ httptrace.DNSDoneInfo) {
|
||||
if it.DNSDone != nil {
|
||||
it.DNSDone(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
ConnectStart: func(_, _ string) {
|
||||
if it.ConnectStart != nil {
|
||||
it.ConnectStart(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
ConnectDone: func(_, _ string, err error) {
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
if it.ConnectDone != nil {
|
||||
it.ConnectDone(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
GotFirstResponseByte: func() {
|
||||
if it.GotFirstResponseByte != nil {
|
||||
it.GotFirstResponseByte(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
Got100Continue: func() {
|
||||
if it.Got100Continue != nil {
|
||||
it.Got100Continue(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
TLSHandshakeStart: func() {
|
||||
if it.TLSHandshakeStart != nil {
|
||||
it.TLSHandshakeStart(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
TLSHandshakeDone: func(_ tls.ConnectionState, err error) {
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
if it.TLSHandshakeDone != nil {
|
||||
it.TLSHandshakeDone(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
WroteHeaders: func() {
|
||||
if it.WroteHeaders != nil {
|
||||
it.WroteHeaders(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
Wait100Continue: func() {
|
||||
if it.Wait100Continue != nil {
|
||||
it.Wait100Continue(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
WroteRequest: func(_ httptrace.WroteRequestInfo) {
|
||||
if it.WroteRequest != nil {
|
||||
it.WroteRequest(time.Since(start).Seconds())
|
||||
}
|
||||
},
|
||||
}
|
||||
r = r.WithContext(httptrace.WithClientTrace(context.Background(), trace))
|
||||
|
||||
return next.RoundTrip(r)
|
||||
})
|
||||
}
|
||||
447
watchdog/vendor/github.com/prometheus/client_golang/prometheus/promhttp/instrument_server.go
generated
vendored
447
watchdog/vendor/github.com/prometheus/client_golang/prometheus/promhttp/instrument_server.go
generated
vendored
@ -1,447 +0,0 @@
|
||||
// Copyright 2017 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package promhttp
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"net/http"
|
||||
"strconv"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
|
||||
"github.com/prometheus/client_golang/prometheus"
|
||||
)
|
||||
|
||||
// magicString is used for the hacky label test in checkLabels. Remove once fixed.
|
||||
const magicString = "zZgWfBxLqvG8kc8IMv3POi2Bb0tZI3vAnBx+gBaFi9FyPzB/CzKUer1yufDa"
|
||||
|
||||
// InstrumentHandlerInFlight is a middleware that wraps the provided
|
||||
// http.Handler. It sets the provided prometheus.Gauge to the number of
|
||||
// requests currently handled by the wrapped http.Handler.
|
||||
//
|
||||
// See the example for InstrumentHandlerDuration for example usage.
|
||||
func InstrumentHandlerInFlight(g prometheus.Gauge, next http.Handler) http.Handler {
|
||||
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
g.Inc()
|
||||
defer g.Dec()
|
||||
next.ServeHTTP(w, r)
|
||||
})
|
||||
}
|
||||
|
||||
// InstrumentHandlerDuration is a middleware that wraps the provided
|
||||
// http.Handler to observe the request duration with the provided ObserverVec.
|
||||
// The ObserverVec must have zero, one, or two non-const non-curried labels. For
|
||||
// those, the only allowed label names are "code" and "method". The function
|
||||
// panics otherwise. The Observe method of the Observer in the ObserverVec is
|
||||
// called with the request duration in seconds. Partitioning happens by HTTP
|
||||
// status code and/or HTTP method if the respective instance label names are
|
||||
// present in the ObserverVec. For unpartitioned observations, use an
|
||||
// ObserverVec with zero labels. Note that partitioning of Histograms is
|
||||
// expensive and should be used judiciously.
|
||||
//
|
||||
// If the wrapped Handler does not set a status code, a status code of 200 is assumed.
|
||||
//
|
||||
// If the wrapped Handler panics, no values are reported.
|
||||
//
|
||||
// Note that this method is only guaranteed to never observe negative durations
|
||||
// if used with Go1.9+.
|
||||
func InstrumentHandlerDuration(obs prometheus.ObserverVec, next http.Handler) http.HandlerFunc {
|
||||
code, method := checkLabels(obs)
|
||||
|
||||
if code {
|
||||
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
now := time.Now()
|
||||
d := newDelegator(w, nil)
|
||||
next.ServeHTTP(d, r)
|
||||
|
||||
obs.With(labels(code, method, r.Method, d.Status())).Observe(time.Since(now).Seconds())
|
||||
})
|
||||
}
|
||||
|
||||
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
now := time.Now()
|
||||
next.ServeHTTP(w, r)
|
||||
obs.With(labels(code, method, r.Method, 0)).Observe(time.Since(now).Seconds())
|
||||
})
|
||||
}
|
||||
|
||||
// InstrumentHandlerCounter is a middleware that wraps the provided http.Handler
|
||||
// to observe the request result with the provided CounterVec. The CounterVec
|
||||
// must have zero, one, or two non-const non-curried labels. For those, the only
|
||||
// allowed label names are "code" and "method". The function panics
|
||||
// otherwise. Partitioning of the CounterVec happens by HTTP status code and/or
|
||||
// HTTP method if the respective instance label names are present in the
|
||||
// CounterVec. For unpartitioned counting, use a CounterVec with zero labels.
|
||||
//
|
||||
// If the wrapped Handler does not set a status code, a status code of 200 is assumed.
|
||||
//
|
||||
// If the wrapped Handler panics, the Counter is not incremented.
|
||||
//
|
||||
// See the example for InstrumentHandlerDuration for example usage.
|
||||
func InstrumentHandlerCounter(counter *prometheus.CounterVec, next http.Handler) http.HandlerFunc {
|
||||
code, method := checkLabels(counter)
|
||||
|
||||
if code {
|
||||
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
d := newDelegator(w, nil)
|
||||
next.ServeHTTP(d, r)
|
||||
counter.With(labels(code, method, r.Method, d.Status())).Inc()
|
||||
})
|
||||
}
|
||||
|
||||
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
next.ServeHTTP(w, r)
|
||||
counter.With(labels(code, method, r.Method, 0)).Inc()
|
||||
})
|
||||
}
|
||||
|
||||
// InstrumentHandlerTimeToWriteHeader is a middleware that wraps the provided
|
||||
// http.Handler to observe with the provided ObserverVec the request duration
|
||||
// until the response headers are written. The ObserverVec must have zero, one,
|
||||
// or two non-const non-curried labels. For those, the only allowed label names
|
||||
// are "code" and "method". The function panics otherwise. The Observe method of
|
||||
// the Observer in the ObserverVec is called with the request duration in
|
||||
// seconds. Partitioning happens by HTTP status code and/or HTTP method if the
|
||||
// respective instance label names are present in the ObserverVec. For
|
||||
// unpartitioned observations, use an ObserverVec with zero labels. Note that
|
||||
// partitioning of Histograms is expensive and should be used judiciously.
|
||||
//
|
||||
// If the wrapped Handler panics before calling WriteHeader, no value is
|
||||
// reported.
|
||||
//
|
||||
// Note that this method is only guaranteed to never observe negative durations
|
||||
// if used with Go1.9+.
|
||||
//
|
||||
// See the example for InstrumentHandlerDuration for example usage.
|
||||
func InstrumentHandlerTimeToWriteHeader(obs prometheus.ObserverVec, next http.Handler) http.HandlerFunc {
|
||||
code, method := checkLabels(obs)
|
||||
|
||||
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
now := time.Now()
|
||||
d := newDelegator(w, func(status int) {
|
||||
obs.With(labels(code, method, r.Method, status)).Observe(time.Since(now).Seconds())
|
||||
})
|
||||
next.ServeHTTP(d, r)
|
||||
})
|
||||
}
|
||||
|
||||
// InstrumentHandlerRequestSize is a middleware that wraps the provided
|
||||
// http.Handler to observe the request size with the provided ObserverVec. The
|
||||
// ObserverVec must have zero, one, or two non-const non-curried labels. For
|
||||
// those, the only allowed label names are "code" and "method". The function
|
||||
// panics otherwise. The Observe method of the Observer in the ObserverVec is
|
||||
// called with the request size in bytes. Partitioning happens by HTTP status
|
||||
// code and/or HTTP method if the respective instance label names are present in
|
||||
// the ObserverVec. For unpartitioned observations, use an ObserverVec with zero
|
||||
// labels. Note that partitioning of Histograms is expensive and should be used
|
||||
// judiciously.
|
||||
//
|
||||
// If the wrapped Handler does not set a status code, a status code of 200 is assumed.
|
||||
//
|
||||
// If the wrapped Handler panics, no values are reported.
|
||||
//
|
||||
// See the example for InstrumentHandlerDuration for example usage.
|
||||
func InstrumentHandlerRequestSize(obs prometheus.ObserverVec, next http.Handler) http.HandlerFunc {
|
||||
code, method := checkLabels(obs)
|
||||
|
||||
if code {
|
||||
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
d := newDelegator(w, nil)
|
||||
next.ServeHTTP(d, r)
|
||||
size := computeApproximateRequestSize(r)
|
||||
obs.With(labels(code, method, r.Method, d.Status())).Observe(float64(size))
|
||||
})
|
||||
}
|
||||
|
||||
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
next.ServeHTTP(w, r)
|
||||
size := computeApproximateRequestSize(r)
|
||||
obs.With(labels(code, method, r.Method, 0)).Observe(float64(size))
|
||||
})
|
||||
}
|
||||
|
||||
// InstrumentHandlerResponseSize is a middleware that wraps the provided
|
||||
// http.Handler to observe the response size with the provided ObserverVec. The
|
||||
// ObserverVec must have zero, one, or two non-const non-curried labels. For
|
||||
// those, the only allowed label names are "code" and "method". The function
|
||||
// panics otherwise. The Observe method of the Observer in the ObserverVec is
|
||||
// called with the response size in bytes. Partitioning happens by HTTP status
|
||||
// code and/or HTTP method if the respective instance label names are present in
|
||||
// the ObserverVec. For unpartitioned observations, use an ObserverVec with zero
|
||||
// labels. Note that partitioning of Histograms is expensive and should be used
|
||||
// judiciously.
|
||||
//
|
||||
// If the wrapped Handler does not set a status code, a status code of 200 is assumed.
|
||||
//
|
||||
// If the wrapped Handler panics, no values are reported.
|
||||
//
|
||||
// See the example for InstrumentHandlerDuration for example usage.
|
||||
func InstrumentHandlerResponseSize(obs prometheus.ObserverVec, next http.Handler) http.Handler {
|
||||
code, method := checkLabels(obs)
|
||||
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||
d := newDelegator(w, nil)
|
||||
next.ServeHTTP(d, r)
|
||||
obs.With(labels(code, method, r.Method, d.Status())).Observe(float64(d.Written()))
|
||||
})
|
||||
}
|
||||
|
||||
func checkLabels(c prometheus.Collector) (code bool, method bool) {
|
||||
// TODO(beorn7): Remove this hacky way to check for instance labels
|
||||
// once Descriptors can have their dimensionality queried.
|
||||
var (
|
||||
desc *prometheus.Desc
|
||||
m prometheus.Metric
|
||||
pm dto.Metric
|
||||
lvs []string
|
||||
)
|
||||
|
||||
// Get the Desc from the Collector.
|
||||
descc := make(chan *prometheus.Desc, 1)
|
||||
c.Describe(descc)
|
||||
|
||||
select {
|
||||
case desc = <-descc:
|
||||
default:
|
||||
panic("no description provided by collector")
|
||||
}
|
||||
select {
|
||||
case <-descc:
|
||||
panic("more than one description provided by collector")
|
||||
default:
|
||||
}
|
||||
|
||||
close(descc)
|
||||
|
||||
// Create a ConstMetric with the Desc. Since we don't know how many
|
||||
// variable labels there are, try for as long as it needs.
|
||||
for err := errors.New("dummy"); err != nil; lvs = append(lvs, magicString) {
|
||||
m, err = prometheus.NewConstMetric(desc, prometheus.UntypedValue, 0, lvs...)
|
||||
}
|
||||
|
||||
// Write out the metric into a proto message and look at the labels.
|
||||
// If the value is not the magicString, it is a constLabel, which doesn't interest us.
|
||||
// If the label is curried, it doesn't interest us.
|
||||
// In all other cases, only "code" or "method" is allowed.
|
||||
if err := m.Write(&pm); err != nil {
|
||||
panic("error checking metric for labels")
|
||||
}
|
||||
for _, label := range pm.Label {
|
||||
name, value := label.GetName(), label.GetValue()
|
||||
if value != magicString || isLabelCurried(c, name) {
|
||||
continue
|
||||
}
|
||||
switch name {
|
||||
case "code":
|
||||
code = true
|
||||
case "method":
|
||||
method = true
|
||||
default:
|
||||
panic("metric partitioned with non-supported labels")
|
||||
}
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
func isLabelCurried(c prometheus.Collector, label string) bool {
|
||||
// This is even hackier than the label test above.
|
||||
// We essentially try to curry again and see if it works.
|
||||
// But for that, we need to type-convert to the two
|
||||
// types we use here, ObserverVec or *CounterVec.
|
||||
switch v := c.(type) {
|
||||
case *prometheus.CounterVec:
|
||||
if _, err := v.CurryWith(prometheus.Labels{label: "dummy"}); err == nil {
|
||||
return false
|
||||
}
|
||||
case prometheus.ObserverVec:
|
||||
if _, err := v.CurryWith(prometheus.Labels{label: "dummy"}); err == nil {
|
||||
return false
|
||||
}
|
||||
default:
|
||||
panic("unsupported metric vec type")
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
// emptyLabels is a one-time allocation for non-partitioned metrics to avoid
|
||||
// unnecessary allocations on each request.
|
||||
var emptyLabels = prometheus.Labels{}
|
||||
|
||||
func labels(code, method bool, reqMethod string, status int) prometheus.Labels {
|
||||
if !(code || method) {
|
||||
return emptyLabels
|
||||
}
|
||||
labels := prometheus.Labels{}
|
||||
|
||||
if code {
|
||||
labels["code"] = sanitizeCode(status)
|
||||
}
|
||||
if method {
|
||||
labels["method"] = sanitizeMethod(reqMethod)
|
||||
}
|
||||
|
||||
return labels
|
||||
}
|
||||
|
||||
func computeApproximateRequestSize(r *http.Request) int {
|
||||
s := 0
|
||||
if r.URL != nil {
|
||||
s += len(r.URL.String())
|
||||
}
|
||||
|
||||
s += len(r.Method)
|
||||
s += len(r.Proto)
|
||||
for name, values := range r.Header {
|
||||
s += len(name)
|
||||
for _, value := range values {
|
||||
s += len(value)
|
||||
}
|
||||
}
|
||||
s += len(r.Host)
|
||||
|
||||
// N.B. r.Form and r.MultipartForm are assumed to be included in r.URL.
|
||||
|
||||
if r.ContentLength != -1 {
|
||||
s += int(r.ContentLength)
|
||||
}
|
||||
return s
|
||||
}
|
||||
|
||||
func sanitizeMethod(m string) string {
|
||||
switch m {
|
||||
case "GET", "get":
|
||||
return "get"
|
||||
case "PUT", "put":
|
||||
return "put"
|
||||
case "HEAD", "head":
|
||||
return "head"
|
||||
case "POST", "post":
|
||||
return "post"
|
||||
case "DELETE", "delete":
|
||||
return "delete"
|
||||
case "CONNECT", "connect":
|
||||
return "connect"
|
||||
case "OPTIONS", "options":
|
||||
return "options"
|
||||
case "NOTIFY", "notify":
|
||||
return "notify"
|
||||
default:
|
||||
return strings.ToLower(m)
|
||||
}
|
||||
}
|
||||
|
||||
// If the wrapped http.Handler has not set a status code, i.e. the value is
|
||||
// currently 0, santizeCode will return 200, for consistency with behavior in
|
||||
// the stdlib.
|
||||
func sanitizeCode(s int) string {
|
||||
switch s {
|
||||
case 100:
|
||||
return "100"
|
||||
case 101:
|
||||
return "101"
|
||||
|
||||
case 200, 0:
|
||||
return "200"
|
||||
case 201:
|
||||
return "201"
|
||||
case 202:
|
||||
return "202"
|
||||
case 203:
|
||||
return "203"
|
||||
case 204:
|
||||
return "204"
|
||||
case 205:
|
||||
return "205"
|
||||
case 206:
|
||||
return "206"
|
||||
|
||||
case 300:
|
||||
return "300"
|
||||
case 301:
|
||||
return "301"
|
||||
case 302:
|
||||
return "302"
|
||||
case 304:
|
||||
return "304"
|
||||
case 305:
|
||||
return "305"
|
||||
case 307:
|
||||
return "307"
|
||||
|
||||
case 400:
|
||||
return "400"
|
||||
case 401:
|
||||
return "401"
|
||||
case 402:
|
||||
return "402"
|
||||
case 403:
|
||||
return "403"
|
||||
case 404:
|
||||
return "404"
|
||||
case 405:
|
||||
return "405"
|
||||
case 406:
|
||||
return "406"
|
||||
case 407:
|
||||
return "407"
|
||||
case 408:
|
||||
return "408"
|
||||
case 409:
|
||||
return "409"
|
||||
case 410:
|
||||
return "410"
|
||||
case 411:
|
||||
return "411"
|
||||
case 412:
|
||||
return "412"
|
||||
case 413:
|
||||
return "413"
|
||||
case 414:
|
||||
return "414"
|
||||
case 415:
|
||||
return "415"
|
||||
case 416:
|
||||
return "416"
|
||||
case 417:
|
||||
return "417"
|
||||
case 418:
|
||||
return "418"
|
||||
|
||||
case 500:
|
||||
return "500"
|
||||
case 501:
|
||||
return "501"
|
||||
case 502:
|
||||
return "502"
|
||||
case 503:
|
||||
return "503"
|
||||
case 504:
|
||||
return "504"
|
||||
case 505:
|
||||
return "505"
|
||||
|
||||
case 428:
|
||||
return "428"
|
||||
case 429:
|
||||
return "429"
|
||||
case 431:
|
||||
return "431"
|
||||
case 511:
|
||||
return "511"
|
||||
|
||||
default:
|
||||
return strconv.Itoa(s)
|
||||
}
|
||||
}
|
||||
937
watchdog/vendor/github.com/prometheus/client_golang/prometheus/registry.go
generated
vendored
937
watchdog/vendor/github.com/prometheus/client_golang/prometheus/registry.go
generated
vendored
@ -1,937 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"fmt"
|
||||
"io/ioutil"
|
||||
"os"
|
||||
"path/filepath"
|
||||
"runtime"
|
||||
"sort"
|
||||
"strings"
|
||||
"sync"
|
||||
"unicode/utf8"
|
||||
|
||||
"github.com/golang/protobuf/proto"
|
||||
"github.com/prometheus/common/expfmt"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
|
||||
"github.com/prometheus/client_golang/prometheus/internal"
|
||||
)
|
||||
|
||||
const (
|
||||
// Capacity for the channel to collect metrics and descriptors.
|
||||
capMetricChan = 1000
|
||||
capDescChan = 10
|
||||
)
|
||||
|
||||
// DefaultRegisterer and DefaultGatherer are the implementations of the
|
||||
// Registerer and Gatherer interface a number of convenience functions in this
|
||||
// package act on. Initially, both variables point to the same Registry, which
|
||||
// has a process collector (currently on Linux only, see NewProcessCollector)
|
||||
// and a Go collector (see NewGoCollector, in particular the note about
|
||||
// stop-the-world implication with Go versions older than 1.9) already
|
||||
// registered. This approach to keep default instances as global state mirrors
|
||||
// the approach of other packages in the Go standard library. Note that there
|
||||
// are caveats. Change the variables with caution and only if you understand the
|
||||
// consequences. Users who want to avoid global state altogether should not use
|
||||
// the convenience functions and act on custom instances instead.
|
||||
var (
|
||||
defaultRegistry = NewRegistry()
|
||||
DefaultRegisterer Registerer = defaultRegistry
|
||||
DefaultGatherer Gatherer = defaultRegistry
|
||||
)
|
||||
|
||||
func init() {
|
||||
MustRegister(NewProcessCollector(ProcessCollectorOpts{}))
|
||||
MustRegister(NewGoCollector())
|
||||
}
|
||||
|
||||
// NewRegistry creates a new vanilla Registry without any Collectors
|
||||
// pre-registered.
|
||||
func NewRegistry() *Registry {
|
||||
return &Registry{
|
||||
collectorsByID: map[uint64]Collector{},
|
||||
descIDs: map[uint64]struct{}{},
|
||||
dimHashesByName: map[string]uint64{},
|
||||
}
|
||||
}
|
||||
|
||||
// NewPedanticRegistry returns a registry that checks during collection if each
|
||||
// collected Metric is consistent with its reported Desc, and if the Desc has
|
||||
// actually been registered with the registry. Unchecked Collectors (those whose
|
||||
// Describe methed does not yield any descriptors) are excluded from the check.
|
||||
//
|
||||
// Usually, a Registry will be happy as long as the union of all collected
|
||||
// Metrics is consistent and valid even if some metrics are not consistent with
|
||||
// their own Desc or a Desc provided by their registered Collector. Well-behaved
|
||||
// Collectors and Metrics will only provide consistent Descs. This Registry is
|
||||
// useful to test the implementation of Collectors and Metrics.
|
||||
func NewPedanticRegistry() *Registry {
|
||||
r := NewRegistry()
|
||||
r.pedanticChecksEnabled = true
|
||||
return r
|
||||
}
|
||||
|
||||
// Registerer is the interface for the part of a registry in charge of
|
||||
// registering and unregistering. Users of custom registries should use
|
||||
// Registerer as type for registration purposes (rather than the Registry type
|
||||
// directly). In that way, they are free to use custom Registerer implementation
|
||||
// (e.g. for testing purposes).
|
||||
type Registerer interface {
|
||||
// Register registers a new Collector to be included in metrics
|
||||
// collection. It returns an error if the descriptors provided by the
|
||||
// Collector are invalid or if they — in combination with descriptors of
|
||||
// already registered Collectors — do not fulfill the consistency and
|
||||
// uniqueness criteria described in the documentation of metric.Desc.
|
||||
//
|
||||
// If the provided Collector is equal to a Collector already registered
|
||||
// (which includes the case of re-registering the same Collector), the
|
||||
// returned error is an instance of AlreadyRegisteredError, which
|
||||
// contains the previously registered Collector.
|
||||
//
|
||||
// A Collector whose Describe method does not yield any Desc is treated
|
||||
// as unchecked. Registration will always succeed. No check for
|
||||
// re-registering (see previous paragraph) is performed. Thus, the
|
||||
// caller is responsible for not double-registering the same unchecked
|
||||
// Collector, and for providing a Collector that will not cause
|
||||
// inconsistent metrics on collection. (This would lead to scrape
|
||||
// errors.)
|
||||
Register(Collector) error
|
||||
// MustRegister works like Register but registers any number of
|
||||
// Collectors and panics upon the first registration that causes an
|
||||
// error.
|
||||
MustRegister(...Collector)
|
||||
// Unregister unregisters the Collector that equals the Collector passed
|
||||
// in as an argument. (Two Collectors are considered equal if their
|
||||
// Describe method yields the same set of descriptors.) The function
|
||||
// returns whether a Collector was unregistered. Note that an unchecked
|
||||
// Collector cannot be unregistered (as its Describe method does not
|
||||
// yield any descriptor).
|
||||
//
|
||||
// Note that even after unregistering, it will not be possible to
|
||||
// register a new Collector that is inconsistent with the unregistered
|
||||
// Collector, e.g. a Collector collecting metrics with the same name but
|
||||
// a different help string. The rationale here is that the same registry
|
||||
// instance must only collect consistent metrics throughout its
|
||||
// lifetime.
|
||||
Unregister(Collector) bool
|
||||
}
|
||||
|
||||
// Gatherer is the interface for the part of a registry in charge of gathering
|
||||
// the collected metrics into a number of MetricFamilies. The Gatherer interface
|
||||
// comes with the same general implication as described for the Registerer
|
||||
// interface.
|
||||
type Gatherer interface {
|
||||
// Gather calls the Collect method of the registered Collectors and then
|
||||
// gathers the collected metrics into a lexicographically sorted slice
|
||||
// of uniquely named MetricFamily protobufs. Gather ensures that the
|
||||
// returned slice is valid and self-consistent so that it can be used
|
||||
// for valid exposition. As an exception to the strict consistency
|
||||
// requirements described for metric.Desc, Gather will tolerate
|
||||
// different sets of label names for metrics of the same metric family.
|
||||
//
|
||||
// Even if an error occurs, Gather attempts to gather as many metrics as
|
||||
// possible. Hence, if a non-nil error is returned, the returned
|
||||
// MetricFamily slice could be nil (in case of a fatal error that
|
||||
// prevented any meaningful metric collection) or contain a number of
|
||||
// MetricFamily protobufs, some of which might be incomplete, and some
|
||||
// might be missing altogether. The returned error (which might be a
|
||||
// MultiError) explains the details. Note that this is mostly useful for
|
||||
// debugging purposes. If the gathered protobufs are to be used for
|
||||
// exposition in actual monitoring, it is almost always better to not
|
||||
// expose an incomplete result and instead disregard the returned
|
||||
// MetricFamily protobufs in case the returned error is non-nil.
|
||||
Gather() ([]*dto.MetricFamily, error)
|
||||
}
|
||||
|
||||
// Register registers the provided Collector with the DefaultRegisterer.
|
||||
//
|
||||
// Register is a shortcut for DefaultRegisterer.Register(c). See there for more
|
||||
// details.
|
||||
func Register(c Collector) error {
|
||||
return DefaultRegisterer.Register(c)
|
||||
}
|
||||
|
||||
// MustRegister registers the provided Collectors with the DefaultRegisterer and
|
||||
// panics if any error occurs.
|
||||
//
|
||||
// MustRegister is a shortcut for DefaultRegisterer.MustRegister(cs...). See
|
||||
// there for more details.
|
||||
func MustRegister(cs ...Collector) {
|
||||
DefaultRegisterer.MustRegister(cs...)
|
||||
}
|
||||
|
||||
// Unregister removes the registration of the provided Collector from the
|
||||
// DefaultRegisterer.
|
||||
//
|
||||
// Unregister is a shortcut for DefaultRegisterer.Unregister(c). See there for
|
||||
// more details.
|
||||
func Unregister(c Collector) bool {
|
||||
return DefaultRegisterer.Unregister(c)
|
||||
}
|
||||
|
||||
// GathererFunc turns a function into a Gatherer.
|
||||
type GathererFunc func() ([]*dto.MetricFamily, error)
|
||||
|
||||
// Gather implements Gatherer.
|
||||
func (gf GathererFunc) Gather() ([]*dto.MetricFamily, error) {
|
||||
return gf()
|
||||
}
|
||||
|
||||
// AlreadyRegisteredError is returned by the Register method if the Collector to
|
||||
// be registered has already been registered before, or a different Collector
|
||||
// that collects the same metrics has been registered before. Registration fails
|
||||
// in that case, but you can detect from the kind of error what has
|
||||
// happened. The error contains fields for the existing Collector and the
|
||||
// (rejected) new Collector that equals the existing one. This can be used to
|
||||
// find out if an equal Collector has been registered before and switch over to
|
||||
// using the old one, as demonstrated in the example.
|
||||
type AlreadyRegisteredError struct {
|
||||
ExistingCollector, NewCollector Collector
|
||||
}
|
||||
|
||||
func (err AlreadyRegisteredError) Error() string {
|
||||
return "duplicate metrics collector registration attempted"
|
||||
}
|
||||
|
||||
// MultiError is a slice of errors implementing the error interface. It is used
|
||||
// by a Gatherer to report multiple errors during MetricFamily gathering.
|
||||
type MultiError []error
|
||||
|
||||
func (errs MultiError) Error() string {
|
||||
if len(errs) == 0 {
|
||||
return ""
|
||||
}
|
||||
buf := &bytes.Buffer{}
|
||||
fmt.Fprintf(buf, "%d error(s) occurred:", len(errs))
|
||||
for _, err := range errs {
|
||||
fmt.Fprintf(buf, "\n* %s", err)
|
||||
}
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
// Append appends the provided error if it is not nil.
|
||||
func (errs *MultiError) Append(err error) {
|
||||
if err != nil {
|
||||
*errs = append(*errs, err)
|
||||
}
|
||||
}
|
||||
|
||||
// MaybeUnwrap returns nil if len(errs) is 0. It returns the first and only
|
||||
// contained error as error if len(errs is 1). In all other cases, it returns
|
||||
// the MultiError directly. This is helpful for returning a MultiError in a way
|
||||
// that only uses the MultiError if needed.
|
||||
func (errs MultiError) MaybeUnwrap() error {
|
||||
switch len(errs) {
|
||||
case 0:
|
||||
return nil
|
||||
case 1:
|
||||
return errs[0]
|
||||
default:
|
||||
return errs
|
||||
}
|
||||
}
|
||||
|
||||
// Registry registers Prometheus collectors, collects their metrics, and gathers
|
||||
// them into MetricFamilies for exposition. It implements both Registerer and
|
||||
// Gatherer. The zero value is not usable. Create instances with NewRegistry or
|
||||
// NewPedanticRegistry.
|
||||
type Registry struct {
|
||||
mtx sync.RWMutex
|
||||
collectorsByID map[uint64]Collector // ID is a hash of the descIDs.
|
||||
descIDs map[uint64]struct{}
|
||||
dimHashesByName map[string]uint64
|
||||
uncheckedCollectors []Collector
|
||||
pedanticChecksEnabled bool
|
||||
}
|
||||
|
||||
// Register implements Registerer.
|
||||
func (r *Registry) Register(c Collector) error {
|
||||
var (
|
||||
descChan = make(chan *Desc, capDescChan)
|
||||
newDescIDs = map[uint64]struct{}{}
|
||||
newDimHashesByName = map[string]uint64{}
|
||||
collectorID uint64 // Just a sum of all desc IDs.
|
||||
duplicateDescErr error
|
||||
)
|
||||
go func() {
|
||||
c.Describe(descChan)
|
||||
close(descChan)
|
||||
}()
|
||||
r.mtx.Lock()
|
||||
defer func() {
|
||||
// Drain channel in case of premature return to not leak a goroutine.
|
||||
for range descChan {
|
||||
}
|
||||
r.mtx.Unlock()
|
||||
}()
|
||||
// Conduct various tests...
|
||||
for desc := range descChan {
|
||||
|
||||
// Is the descriptor valid at all?
|
||||
if desc.err != nil {
|
||||
return fmt.Errorf("descriptor %s is invalid: %s", desc, desc.err)
|
||||
}
|
||||
|
||||
// Is the descID unique?
|
||||
// (In other words: Is the fqName + constLabel combination unique?)
|
||||
if _, exists := r.descIDs[desc.id]; exists {
|
||||
duplicateDescErr = fmt.Errorf("descriptor %s already exists with the same fully-qualified name and const label values", desc)
|
||||
}
|
||||
// If it is not a duplicate desc in this collector, add it to
|
||||
// the collectorID. (We allow duplicate descs within the same
|
||||
// collector, but their existence must be a no-op.)
|
||||
if _, exists := newDescIDs[desc.id]; !exists {
|
||||
newDescIDs[desc.id] = struct{}{}
|
||||
collectorID += desc.id
|
||||
}
|
||||
|
||||
// Are all the label names and the help string consistent with
|
||||
// previous descriptors of the same name?
|
||||
// First check existing descriptors...
|
||||
if dimHash, exists := r.dimHashesByName[desc.fqName]; exists {
|
||||
if dimHash != desc.dimHash {
|
||||
return fmt.Errorf("a previously registered descriptor with the same fully-qualified name as %s has different label names or a different help string", desc)
|
||||
}
|
||||
} else {
|
||||
// ...then check the new descriptors already seen.
|
||||
if dimHash, exists := newDimHashesByName[desc.fqName]; exists {
|
||||
if dimHash != desc.dimHash {
|
||||
return fmt.Errorf("descriptors reported by collector have inconsistent label names or help strings for the same fully-qualified name, offender is %s", desc)
|
||||
}
|
||||
} else {
|
||||
newDimHashesByName[desc.fqName] = desc.dimHash
|
||||
}
|
||||
}
|
||||
}
|
||||
// A Collector yielding no Desc at all is considered unchecked.
|
||||
if len(newDescIDs) == 0 {
|
||||
r.uncheckedCollectors = append(r.uncheckedCollectors, c)
|
||||
return nil
|
||||
}
|
||||
if existing, exists := r.collectorsByID[collectorID]; exists {
|
||||
return AlreadyRegisteredError{
|
||||
ExistingCollector: existing,
|
||||
NewCollector: c,
|
||||
}
|
||||
}
|
||||
// If the collectorID is new, but at least one of the descs existed
|
||||
// before, we are in trouble.
|
||||
if duplicateDescErr != nil {
|
||||
return duplicateDescErr
|
||||
}
|
||||
|
||||
// Only after all tests have passed, actually register.
|
||||
r.collectorsByID[collectorID] = c
|
||||
for hash := range newDescIDs {
|
||||
r.descIDs[hash] = struct{}{}
|
||||
}
|
||||
for name, dimHash := range newDimHashesByName {
|
||||
r.dimHashesByName[name] = dimHash
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// Unregister implements Registerer.
|
||||
func (r *Registry) Unregister(c Collector) bool {
|
||||
var (
|
||||
descChan = make(chan *Desc, capDescChan)
|
||||
descIDs = map[uint64]struct{}{}
|
||||
collectorID uint64 // Just a sum of the desc IDs.
|
||||
)
|
||||
go func() {
|
||||
c.Describe(descChan)
|
||||
close(descChan)
|
||||
}()
|
||||
for desc := range descChan {
|
||||
if _, exists := descIDs[desc.id]; !exists {
|
||||
collectorID += desc.id
|
||||
descIDs[desc.id] = struct{}{}
|
||||
}
|
||||
}
|
||||
|
||||
r.mtx.RLock()
|
||||
if _, exists := r.collectorsByID[collectorID]; !exists {
|
||||
r.mtx.RUnlock()
|
||||
return false
|
||||
}
|
||||
r.mtx.RUnlock()
|
||||
|
||||
r.mtx.Lock()
|
||||
defer r.mtx.Unlock()
|
||||
|
||||
delete(r.collectorsByID, collectorID)
|
||||
for id := range descIDs {
|
||||
delete(r.descIDs, id)
|
||||
}
|
||||
// dimHashesByName is left untouched as those must be consistent
|
||||
// throughout the lifetime of a program.
|
||||
return true
|
||||
}
|
||||
|
||||
// MustRegister implements Registerer.
|
||||
func (r *Registry) MustRegister(cs ...Collector) {
|
||||
for _, c := range cs {
|
||||
if err := r.Register(c); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Gather implements Gatherer.
|
||||
func (r *Registry) Gather() ([]*dto.MetricFamily, error) {
|
||||
var (
|
||||
checkedMetricChan = make(chan Metric, capMetricChan)
|
||||
uncheckedMetricChan = make(chan Metric, capMetricChan)
|
||||
metricHashes = map[uint64]struct{}{}
|
||||
wg sync.WaitGroup
|
||||
errs MultiError // The collected errors to return in the end.
|
||||
registeredDescIDs map[uint64]struct{} // Only used for pedantic checks
|
||||
)
|
||||
|
||||
r.mtx.RLock()
|
||||
goroutineBudget := len(r.collectorsByID) + len(r.uncheckedCollectors)
|
||||
metricFamiliesByName := make(map[string]*dto.MetricFamily, len(r.dimHashesByName))
|
||||
checkedCollectors := make(chan Collector, len(r.collectorsByID))
|
||||
uncheckedCollectors := make(chan Collector, len(r.uncheckedCollectors))
|
||||
for _, collector := range r.collectorsByID {
|
||||
checkedCollectors <- collector
|
||||
}
|
||||
for _, collector := range r.uncheckedCollectors {
|
||||
uncheckedCollectors <- collector
|
||||
}
|
||||
// In case pedantic checks are enabled, we have to copy the map before
|
||||
// giving up the RLock.
|
||||
if r.pedanticChecksEnabled {
|
||||
registeredDescIDs = make(map[uint64]struct{}, len(r.descIDs))
|
||||
for id := range r.descIDs {
|
||||
registeredDescIDs[id] = struct{}{}
|
||||
}
|
||||
}
|
||||
r.mtx.RUnlock()
|
||||
|
||||
wg.Add(goroutineBudget)
|
||||
|
||||
collectWorker := func() {
|
||||
for {
|
||||
select {
|
||||
case collector := <-checkedCollectors:
|
||||
collector.Collect(checkedMetricChan)
|
||||
case collector := <-uncheckedCollectors:
|
||||
collector.Collect(uncheckedMetricChan)
|
||||
default:
|
||||
return
|
||||
}
|
||||
wg.Done()
|
||||
}
|
||||
}
|
||||
|
||||
// Start the first worker now to make sure at least one is running.
|
||||
go collectWorker()
|
||||
goroutineBudget--
|
||||
|
||||
// Close checkedMetricChan and uncheckedMetricChan once all collectors
|
||||
// are collected.
|
||||
go func() {
|
||||
wg.Wait()
|
||||
close(checkedMetricChan)
|
||||
close(uncheckedMetricChan)
|
||||
}()
|
||||
|
||||
// Drain checkedMetricChan and uncheckedMetricChan in case of premature return.
|
||||
defer func() {
|
||||
if checkedMetricChan != nil {
|
||||
for range checkedMetricChan {
|
||||
}
|
||||
}
|
||||
if uncheckedMetricChan != nil {
|
||||
for range uncheckedMetricChan {
|
||||
}
|
||||
}
|
||||
}()
|
||||
|
||||
// Copy the channel references so we can nil them out later to remove
|
||||
// them from the select statements below.
|
||||
cmc := checkedMetricChan
|
||||
umc := uncheckedMetricChan
|
||||
|
||||
for {
|
||||
select {
|
||||
case metric, ok := <-cmc:
|
||||
if !ok {
|
||||
cmc = nil
|
||||
break
|
||||
}
|
||||
errs.Append(processMetric(
|
||||
metric, metricFamiliesByName,
|
||||
metricHashes,
|
||||
registeredDescIDs,
|
||||
))
|
||||
case metric, ok := <-umc:
|
||||
if !ok {
|
||||
umc = nil
|
||||
break
|
||||
}
|
||||
errs.Append(processMetric(
|
||||
metric, metricFamiliesByName,
|
||||
metricHashes,
|
||||
nil,
|
||||
))
|
||||
default:
|
||||
if goroutineBudget <= 0 || len(checkedCollectors)+len(uncheckedCollectors) == 0 {
|
||||
// All collectors are already being worked on or
|
||||
// we have already as many goroutines started as
|
||||
// there are collectors. Do the same as above,
|
||||
// just without the default.
|
||||
select {
|
||||
case metric, ok := <-cmc:
|
||||
if !ok {
|
||||
cmc = nil
|
||||
break
|
||||
}
|
||||
errs.Append(processMetric(
|
||||
metric, metricFamiliesByName,
|
||||
metricHashes,
|
||||
registeredDescIDs,
|
||||
))
|
||||
case metric, ok := <-umc:
|
||||
if !ok {
|
||||
umc = nil
|
||||
break
|
||||
}
|
||||
errs.Append(processMetric(
|
||||
metric, metricFamiliesByName,
|
||||
metricHashes,
|
||||
nil,
|
||||
))
|
||||
}
|
||||
break
|
||||
}
|
||||
// Start more workers.
|
||||
go collectWorker()
|
||||
goroutineBudget--
|
||||
runtime.Gosched()
|
||||
}
|
||||
// Once both checkedMetricChan and uncheckdMetricChan are closed
|
||||
// and drained, the contraption above will nil out cmc and umc,
|
||||
// and then we can leave the collect loop here.
|
||||
if cmc == nil && umc == nil {
|
||||
break
|
||||
}
|
||||
}
|
||||
return internal.NormalizeMetricFamilies(metricFamiliesByName), errs.MaybeUnwrap()
|
||||
}
|
||||
|
||||
// WriteToTextfile calls Gather on the provided Gatherer, encodes the result in the
|
||||
// Prometheus text format, and writes it to a temporary file. Upon success, the
|
||||
// temporary file is renamed to the provided filename.
|
||||
//
|
||||
// This is intended for use with the textfile collector of the node exporter.
|
||||
// Note that the node exporter expects the filename to be suffixed with ".prom".
|
||||
func WriteToTextfile(filename string, g Gatherer) error {
|
||||
tmp, err := ioutil.TempFile(filepath.Dir(filename), filepath.Base(filename))
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer os.Remove(tmp.Name())
|
||||
|
||||
mfs, err := g.Gather()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
for _, mf := range mfs {
|
||||
if _, err := expfmt.MetricFamilyToText(tmp, mf); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
if err := tmp.Close(); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
if err := os.Chmod(tmp.Name(), 0644); err != nil {
|
||||
return err
|
||||
}
|
||||
return os.Rename(tmp.Name(), filename)
|
||||
}
|
||||
|
||||
// processMetric is an internal helper method only used by the Gather method.
|
||||
func processMetric(
|
||||
metric Metric,
|
||||
metricFamiliesByName map[string]*dto.MetricFamily,
|
||||
metricHashes map[uint64]struct{},
|
||||
registeredDescIDs map[uint64]struct{},
|
||||
) error {
|
||||
desc := metric.Desc()
|
||||
// Wrapped metrics collected by an unchecked Collector can have an
|
||||
// invalid Desc.
|
||||
if desc.err != nil {
|
||||
return desc.err
|
||||
}
|
||||
dtoMetric := &dto.Metric{}
|
||||
if err := metric.Write(dtoMetric); err != nil {
|
||||
return fmt.Errorf("error collecting metric %v: %s", desc, err)
|
||||
}
|
||||
metricFamily, ok := metricFamiliesByName[desc.fqName]
|
||||
if ok { // Existing name.
|
||||
if metricFamily.GetHelp() != desc.help {
|
||||
return fmt.Errorf(
|
||||
"collected metric %s %s has help %q but should have %q",
|
||||
desc.fqName, dtoMetric, desc.help, metricFamily.GetHelp(),
|
||||
)
|
||||
}
|
||||
// TODO(beorn7): Simplify switch once Desc has type.
|
||||
switch metricFamily.GetType() {
|
||||
case dto.MetricType_COUNTER:
|
||||
if dtoMetric.Counter == nil {
|
||||
return fmt.Errorf(
|
||||
"collected metric %s %s should be a Counter",
|
||||
desc.fqName, dtoMetric,
|
||||
)
|
||||
}
|
||||
case dto.MetricType_GAUGE:
|
||||
if dtoMetric.Gauge == nil {
|
||||
return fmt.Errorf(
|
||||
"collected metric %s %s should be a Gauge",
|
||||
desc.fqName, dtoMetric,
|
||||
)
|
||||
}
|
||||
case dto.MetricType_SUMMARY:
|
||||
if dtoMetric.Summary == nil {
|
||||
return fmt.Errorf(
|
||||
"collected metric %s %s should be a Summary",
|
||||
desc.fqName, dtoMetric,
|
||||
)
|
||||
}
|
||||
case dto.MetricType_UNTYPED:
|
||||
if dtoMetric.Untyped == nil {
|
||||
return fmt.Errorf(
|
||||
"collected metric %s %s should be Untyped",
|
||||
desc.fqName, dtoMetric,
|
||||
)
|
||||
}
|
||||
case dto.MetricType_HISTOGRAM:
|
||||
if dtoMetric.Histogram == nil {
|
||||
return fmt.Errorf(
|
||||
"collected metric %s %s should be a Histogram",
|
||||
desc.fqName, dtoMetric,
|
||||
)
|
||||
}
|
||||
default:
|
||||
panic("encountered MetricFamily with invalid type")
|
||||
}
|
||||
} else { // New name.
|
||||
metricFamily = &dto.MetricFamily{}
|
||||
metricFamily.Name = proto.String(desc.fqName)
|
||||
metricFamily.Help = proto.String(desc.help)
|
||||
// TODO(beorn7): Simplify switch once Desc has type.
|
||||
switch {
|
||||
case dtoMetric.Gauge != nil:
|
||||
metricFamily.Type = dto.MetricType_GAUGE.Enum()
|
||||
case dtoMetric.Counter != nil:
|
||||
metricFamily.Type = dto.MetricType_COUNTER.Enum()
|
||||
case dtoMetric.Summary != nil:
|
||||
metricFamily.Type = dto.MetricType_SUMMARY.Enum()
|
||||
case dtoMetric.Untyped != nil:
|
||||
metricFamily.Type = dto.MetricType_UNTYPED.Enum()
|
||||
case dtoMetric.Histogram != nil:
|
||||
metricFamily.Type = dto.MetricType_HISTOGRAM.Enum()
|
||||
default:
|
||||
return fmt.Errorf("empty metric collected: %s", dtoMetric)
|
||||
}
|
||||
if err := checkSuffixCollisions(metricFamily, metricFamiliesByName); err != nil {
|
||||
return err
|
||||
}
|
||||
metricFamiliesByName[desc.fqName] = metricFamily
|
||||
}
|
||||
if err := checkMetricConsistency(metricFamily, dtoMetric, metricHashes); err != nil {
|
||||
return err
|
||||
}
|
||||
if registeredDescIDs != nil {
|
||||
// Is the desc registered at all?
|
||||
if _, exist := registeredDescIDs[desc.id]; !exist {
|
||||
return fmt.Errorf(
|
||||
"collected metric %s %s with unregistered descriptor %s",
|
||||
metricFamily.GetName(), dtoMetric, desc,
|
||||
)
|
||||
}
|
||||
if err := checkDescConsistency(metricFamily, dtoMetric, desc); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
metricFamily.Metric = append(metricFamily.Metric, dtoMetric)
|
||||
return nil
|
||||
}
|
||||
|
||||
// Gatherers is a slice of Gatherer instances that implements the Gatherer
|
||||
// interface itself. Its Gather method calls Gather on all Gatherers in the
|
||||
// slice in order and returns the merged results. Errors returned from the
|
||||
// Gather calles are all returned in a flattened MultiError. Duplicate and
|
||||
// inconsistent Metrics are skipped (first occurrence in slice order wins) and
|
||||
// reported in the returned error.
|
||||
//
|
||||
// Gatherers can be used to merge the Gather results from multiple
|
||||
// Registries. It also provides a way to directly inject existing MetricFamily
|
||||
// protobufs into the gathering by creating a custom Gatherer with a Gather
|
||||
// method that simply returns the existing MetricFamily protobufs. Note that no
|
||||
// registration is involved (in contrast to Collector registration), so
|
||||
// obviously registration-time checks cannot happen. Any inconsistencies between
|
||||
// the gathered MetricFamilies are reported as errors by the Gather method, and
|
||||
// inconsistent Metrics are dropped. Invalid parts of the MetricFamilies
|
||||
// (e.g. syntactically invalid metric or label names) will go undetected.
|
||||
type Gatherers []Gatherer
|
||||
|
||||
// Gather implements Gatherer.
|
||||
func (gs Gatherers) Gather() ([]*dto.MetricFamily, error) {
|
||||
var (
|
||||
metricFamiliesByName = map[string]*dto.MetricFamily{}
|
||||
metricHashes = map[uint64]struct{}{}
|
||||
errs MultiError // The collected errors to return in the end.
|
||||
)
|
||||
|
||||
for i, g := range gs {
|
||||
mfs, err := g.Gather()
|
||||
if err != nil {
|
||||
if multiErr, ok := err.(MultiError); ok {
|
||||
for _, err := range multiErr {
|
||||
errs = append(errs, fmt.Errorf("[from Gatherer #%d] %s", i+1, err))
|
||||
}
|
||||
} else {
|
||||
errs = append(errs, fmt.Errorf("[from Gatherer #%d] %s", i+1, err))
|
||||
}
|
||||
}
|
||||
for _, mf := range mfs {
|
||||
existingMF, exists := metricFamiliesByName[mf.GetName()]
|
||||
if exists {
|
||||
if existingMF.GetHelp() != mf.GetHelp() {
|
||||
errs = append(errs, fmt.Errorf(
|
||||
"gathered metric family %s has help %q but should have %q",
|
||||
mf.GetName(), mf.GetHelp(), existingMF.GetHelp(),
|
||||
))
|
||||
continue
|
||||
}
|
||||
if existingMF.GetType() != mf.GetType() {
|
||||
errs = append(errs, fmt.Errorf(
|
||||
"gathered metric family %s has type %s but should have %s",
|
||||
mf.GetName(), mf.GetType(), existingMF.GetType(),
|
||||
))
|
||||
continue
|
||||
}
|
||||
} else {
|
||||
existingMF = &dto.MetricFamily{}
|
||||
existingMF.Name = mf.Name
|
||||
existingMF.Help = mf.Help
|
||||
existingMF.Type = mf.Type
|
||||
if err := checkSuffixCollisions(existingMF, metricFamiliesByName); err != nil {
|
||||
errs = append(errs, err)
|
||||
continue
|
||||
}
|
||||
metricFamiliesByName[mf.GetName()] = existingMF
|
||||
}
|
||||
for _, m := range mf.Metric {
|
||||
if err := checkMetricConsistency(existingMF, m, metricHashes); err != nil {
|
||||
errs = append(errs, err)
|
||||
continue
|
||||
}
|
||||
existingMF.Metric = append(existingMF.Metric, m)
|
||||
}
|
||||
}
|
||||
}
|
||||
return internal.NormalizeMetricFamilies(metricFamiliesByName), errs.MaybeUnwrap()
|
||||
}
|
||||
|
||||
// checkSuffixCollisions checks for collisions with the “magic” suffixes the
|
||||
// Prometheus text format and the internal metric representation of the
|
||||
// Prometheus server add while flattening Summaries and Histograms.
|
||||
func checkSuffixCollisions(mf *dto.MetricFamily, mfs map[string]*dto.MetricFamily) error {
|
||||
var (
|
||||
newName = mf.GetName()
|
||||
newType = mf.GetType()
|
||||
newNameWithoutSuffix = ""
|
||||
)
|
||||
switch {
|
||||
case strings.HasSuffix(newName, "_count"):
|
||||
newNameWithoutSuffix = newName[:len(newName)-6]
|
||||
case strings.HasSuffix(newName, "_sum"):
|
||||
newNameWithoutSuffix = newName[:len(newName)-4]
|
||||
case strings.HasSuffix(newName, "_bucket"):
|
||||
newNameWithoutSuffix = newName[:len(newName)-7]
|
||||
}
|
||||
if newNameWithoutSuffix != "" {
|
||||
if existingMF, ok := mfs[newNameWithoutSuffix]; ok {
|
||||
switch existingMF.GetType() {
|
||||
case dto.MetricType_SUMMARY:
|
||||
if !strings.HasSuffix(newName, "_bucket") {
|
||||
return fmt.Errorf(
|
||||
"collected metric named %q collides with previously collected summary named %q",
|
||||
newName, newNameWithoutSuffix,
|
||||
)
|
||||
}
|
||||
case dto.MetricType_HISTOGRAM:
|
||||
return fmt.Errorf(
|
||||
"collected metric named %q collides with previously collected histogram named %q",
|
||||
newName, newNameWithoutSuffix,
|
||||
)
|
||||
}
|
||||
}
|
||||
}
|
||||
if newType == dto.MetricType_SUMMARY || newType == dto.MetricType_HISTOGRAM {
|
||||
if _, ok := mfs[newName+"_count"]; ok {
|
||||
return fmt.Errorf(
|
||||
"collected histogram or summary named %q collides with previously collected metric named %q",
|
||||
newName, newName+"_count",
|
||||
)
|
||||
}
|
||||
if _, ok := mfs[newName+"_sum"]; ok {
|
||||
return fmt.Errorf(
|
||||
"collected histogram or summary named %q collides with previously collected metric named %q",
|
||||
newName, newName+"_sum",
|
||||
)
|
||||
}
|
||||
}
|
||||
if newType == dto.MetricType_HISTOGRAM {
|
||||
if _, ok := mfs[newName+"_bucket"]; ok {
|
||||
return fmt.Errorf(
|
||||
"collected histogram named %q collides with previously collected metric named %q",
|
||||
newName, newName+"_bucket",
|
||||
)
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// checkMetricConsistency checks if the provided Metric is consistent with the
|
||||
// provided MetricFamily. It also hashes the Metric labels and the MetricFamily
|
||||
// name. If the resulting hash is already in the provided metricHashes, an error
|
||||
// is returned. If not, it is added to metricHashes.
|
||||
func checkMetricConsistency(
|
||||
metricFamily *dto.MetricFamily,
|
||||
dtoMetric *dto.Metric,
|
||||
metricHashes map[uint64]struct{},
|
||||
) error {
|
||||
name := metricFamily.GetName()
|
||||
|
||||
// Type consistency with metric family.
|
||||
if metricFamily.GetType() == dto.MetricType_GAUGE && dtoMetric.Gauge == nil ||
|
||||
metricFamily.GetType() == dto.MetricType_COUNTER && dtoMetric.Counter == nil ||
|
||||
metricFamily.GetType() == dto.MetricType_SUMMARY && dtoMetric.Summary == nil ||
|
||||
metricFamily.GetType() == dto.MetricType_HISTOGRAM && dtoMetric.Histogram == nil ||
|
||||
metricFamily.GetType() == dto.MetricType_UNTYPED && dtoMetric.Untyped == nil {
|
||||
return fmt.Errorf(
|
||||
"collected metric %q { %s} is not a %s",
|
||||
name, dtoMetric, metricFamily.GetType(),
|
||||
)
|
||||
}
|
||||
|
||||
previousLabelName := ""
|
||||
for _, labelPair := range dtoMetric.GetLabel() {
|
||||
labelName := labelPair.GetName()
|
||||
if labelName == previousLabelName {
|
||||
return fmt.Errorf(
|
||||
"collected metric %q { %s} has two or more labels with the same name: %s",
|
||||
name, dtoMetric, labelName,
|
||||
)
|
||||
}
|
||||
if !checkLabelName(labelName) {
|
||||
return fmt.Errorf(
|
||||
"collected metric %q { %s} has a label with an invalid name: %s",
|
||||
name, dtoMetric, labelName,
|
||||
)
|
||||
}
|
||||
if dtoMetric.Summary != nil && labelName == quantileLabel {
|
||||
return fmt.Errorf(
|
||||
"collected metric %q { %s} must not have an explicit %q label",
|
||||
name, dtoMetric, quantileLabel,
|
||||
)
|
||||
}
|
||||
if !utf8.ValidString(labelPair.GetValue()) {
|
||||
return fmt.Errorf(
|
||||
"collected metric %q { %s} has a label named %q whose value is not utf8: %#v",
|
||||
name, dtoMetric, labelName, labelPair.GetValue())
|
||||
}
|
||||
previousLabelName = labelName
|
||||
}
|
||||
|
||||
// Is the metric unique (i.e. no other metric with the same name and the same labels)?
|
||||
h := hashNew()
|
||||
h = hashAdd(h, name)
|
||||
h = hashAddByte(h, separatorByte)
|
||||
// Make sure label pairs are sorted. We depend on it for the consistency
|
||||
// check.
|
||||
if !sort.IsSorted(labelPairSorter(dtoMetric.Label)) {
|
||||
// We cannot sort dtoMetric.Label in place as it is immutable by contract.
|
||||
copiedLabels := make([]*dto.LabelPair, len(dtoMetric.Label))
|
||||
copy(copiedLabels, dtoMetric.Label)
|
||||
sort.Sort(labelPairSorter(copiedLabels))
|
||||
dtoMetric.Label = copiedLabels
|
||||
}
|
||||
for _, lp := range dtoMetric.Label {
|
||||
h = hashAdd(h, lp.GetName())
|
||||
h = hashAddByte(h, separatorByte)
|
||||
h = hashAdd(h, lp.GetValue())
|
||||
h = hashAddByte(h, separatorByte)
|
||||
}
|
||||
if _, exists := metricHashes[h]; exists {
|
||||
return fmt.Errorf(
|
||||
"collected metric %q { %s} was collected before with the same name and label values",
|
||||
name, dtoMetric,
|
||||
)
|
||||
}
|
||||
metricHashes[h] = struct{}{}
|
||||
return nil
|
||||
}
|
||||
|
||||
func checkDescConsistency(
|
||||
metricFamily *dto.MetricFamily,
|
||||
dtoMetric *dto.Metric,
|
||||
desc *Desc,
|
||||
) error {
|
||||
// Desc help consistency with metric family help.
|
||||
if metricFamily.GetHelp() != desc.help {
|
||||
return fmt.Errorf(
|
||||
"collected metric %s %s has help %q but should have %q",
|
||||
metricFamily.GetName(), dtoMetric, metricFamily.GetHelp(), desc.help,
|
||||
)
|
||||
}
|
||||
|
||||
// Is the desc consistent with the content of the metric?
|
||||
lpsFromDesc := make([]*dto.LabelPair, len(desc.constLabelPairs), len(dtoMetric.Label))
|
||||
copy(lpsFromDesc, desc.constLabelPairs)
|
||||
for _, l := range desc.variableLabels {
|
||||
lpsFromDesc = append(lpsFromDesc, &dto.LabelPair{
|
||||
Name: proto.String(l),
|
||||
})
|
||||
}
|
||||
if len(lpsFromDesc) != len(dtoMetric.Label) {
|
||||
return fmt.Errorf(
|
||||
"labels in collected metric %s %s are inconsistent with descriptor %s",
|
||||
metricFamily.GetName(), dtoMetric, desc,
|
||||
)
|
||||
}
|
||||
sort.Sort(labelPairSorter(lpsFromDesc))
|
||||
for i, lpFromDesc := range lpsFromDesc {
|
||||
lpFromMetric := dtoMetric.Label[i]
|
||||
if lpFromDesc.GetName() != lpFromMetric.GetName() ||
|
||||
lpFromDesc.Value != nil && lpFromDesc.GetValue() != lpFromMetric.GetValue() {
|
||||
return fmt.Errorf(
|
||||
"labels in collected metric %s %s are inconsistent with descriptor %s",
|
||||
metricFamily.GetName(), dtoMetric, desc,
|
||||
)
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
626
watchdog/vendor/github.com/prometheus/client_golang/prometheus/summary.go
generated
vendored
626
watchdog/vendor/github.com/prometheus/client_golang/prometheus/summary.go
generated
vendored
@ -1,626 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"math"
|
||||
"sort"
|
||||
"sync"
|
||||
"time"
|
||||
|
||||
"github.com/beorn7/perks/quantile"
|
||||
"github.com/golang/protobuf/proto"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
)
|
||||
|
||||
// quantileLabel is used for the label that defines the quantile in a
|
||||
// summary.
|
||||
const quantileLabel = "quantile"
|
||||
|
||||
// A Summary captures individual observations from an event or sample stream and
|
||||
// summarizes them in a manner similar to traditional summary statistics: 1. sum
|
||||
// of observations, 2. observation count, 3. rank estimations.
|
||||
//
|
||||
// A typical use-case is the observation of request latencies. By default, a
|
||||
// Summary provides the median, the 90th and the 99th percentile of the latency
|
||||
// as rank estimations. However, the default behavior will change in the
|
||||
// upcoming v0.10 of the library. There will be no rank estimations at all by
|
||||
// default. For a sane transition, it is recommended to set the desired rank
|
||||
// estimations explicitly.
|
||||
//
|
||||
// Note that the rank estimations cannot be aggregated in a meaningful way with
|
||||
// the Prometheus query language (i.e. you cannot average or add them). If you
|
||||
// need aggregatable quantiles (e.g. you want the 99th percentile latency of all
|
||||
// queries served across all instances of a service), consider the Histogram
|
||||
// metric type. See the Prometheus documentation for more details.
|
||||
//
|
||||
// To create Summary instances, use NewSummary.
|
||||
type Summary interface {
|
||||
Metric
|
||||
Collector
|
||||
|
||||
// Observe adds a single observation to the summary.
|
||||
Observe(float64)
|
||||
}
|
||||
|
||||
// DefObjectives are the default Summary quantile values.
|
||||
//
|
||||
// Deprecated: DefObjectives will not be used as the default objectives in
|
||||
// v0.10 of the library. The default Summary will have no quantiles then.
|
||||
var (
|
||||
DefObjectives = map[float64]float64{0.5: 0.05, 0.9: 0.01, 0.99: 0.001}
|
||||
|
||||
errQuantileLabelNotAllowed = fmt.Errorf(
|
||||
"%q is not allowed as label name in summaries", quantileLabel,
|
||||
)
|
||||
)
|
||||
|
||||
// Default values for SummaryOpts.
|
||||
const (
|
||||
// DefMaxAge is the default duration for which observations stay
|
||||
// relevant.
|
||||
DefMaxAge time.Duration = 10 * time.Minute
|
||||
// DefAgeBuckets is the default number of buckets used to calculate the
|
||||
// age of observations.
|
||||
DefAgeBuckets = 5
|
||||
// DefBufCap is the standard buffer size for collecting Summary observations.
|
||||
DefBufCap = 500
|
||||
)
|
||||
|
||||
// SummaryOpts bundles the options for creating a Summary metric. It is
|
||||
// mandatory to set Name to a non-empty string. While all other fields are
|
||||
// optional and can safely be left at their zero value, it is recommended to set
|
||||
// a help string and to explicitly set the Objectives field to the desired value
|
||||
// as the default value will change in the upcoming v0.10 of the library.
|
||||
type SummaryOpts struct {
|
||||
// Namespace, Subsystem, and Name are components of the fully-qualified
|
||||
// name of the Summary (created by joining these components with
|
||||
// "_"). Only Name is mandatory, the others merely help structuring the
|
||||
// name. Note that the fully-qualified name of the Summary must be a
|
||||
// valid Prometheus metric name.
|
||||
Namespace string
|
||||
Subsystem string
|
||||
Name string
|
||||
|
||||
// Help provides information about this Summary.
|
||||
//
|
||||
// Metrics with the same fully-qualified name must have the same Help
|
||||
// string.
|
||||
Help string
|
||||
|
||||
// ConstLabels are used to attach fixed labels to this metric. Metrics
|
||||
// with the same fully-qualified name must have the same label names in
|
||||
// their ConstLabels.
|
||||
//
|
||||
// Due to the way a Summary is represented in the Prometheus text format
|
||||
// and how it is handled by the Prometheus server internally, “quantile”
|
||||
// is an illegal label name. Construction of a Summary or SummaryVec
|
||||
// will panic if this label name is used in ConstLabels.
|
||||
//
|
||||
// ConstLabels are only used rarely. In particular, do not use them to
|
||||
// attach the same labels to all your metrics. Those use cases are
|
||||
// better covered by target labels set by the scraping Prometheus
|
||||
// server, or by one specific metric (e.g. a build_info or a
|
||||
// machine_role metric). See also
|
||||
// https://prometheus.io/docs/instrumenting/writing_exporters/#target-labels,-not-static-scraped-labels
|
||||
ConstLabels Labels
|
||||
|
||||
// Objectives defines the quantile rank estimates with their respective
|
||||
// absolute error. If Objectives[q] = e, then the value reported for q
|
||||
// will be the φ-quantile value for some φ between q-e and q+e. The
|
||||
// default value is DefObjectives. It is used if Objectives is left at
|
||||
// its zero value (i.e. nil). To create a Summary without Objectives,
|
||||
// set it to an empty map (i.e. map[float64]float64{}).
|
||||
//
|
||||
// Deprecated: Note that the current value of DefObjectives is
|
||||
// deprecated. It will be replaced by an empty map in v0.10 of the
|
||||
// library. Please explicitly set Objectives to the desired value.
|
||||
Objectives map[float64]float64
|
||||
|
||||
// MaxAge defines the duration for which an observation stays relevant
|
||||
// for the summary. Must be positive. The default value is DefMaxAge.
|
||||
MaxAge time.Duration
|
||||
|
||||
// AgeBuckets is the number of buckets used to exclude observations that
|
||||
// are older than MaxAge from the summary. A higher number has a
|
||||
// resource penalty, so only increase it if the higher resolution is
|
||||
// really required. For very high observation rates, you might want to
|
||||
// reduce the number of age buckets. With only one age bucket, you will
|
||||
// effectively see a complete reset of the summary each time MaxAge has
|
||||
// passed. The default value is DefAgeBuckets.
|
||||
AgeBuckets uint32
|
||||
|
||||
// BufCap defines the default sample stream buffer size. The default
|
||||
// value of DefBufCap should suffice for most uses. If there is a need
|
||||
// to increase the value, a multiple of 500 is recommended (because that
|
||||
// is the internal buffer size of the underlying package
|
||||
// "github.com/bmizerany/perks/quantile").
|
||||
BufCap uint32
|
||||
}
|
||||
|
||||
// Great fuck-up with the sliding-window decay algorithm... The Merge method of
|
||||
// perk/quantile is actually not working as advertised - and it might be
|
||||
// unfixable, as the underlying algorithm is apparently not capable of merging
|
||||
// summaries in the first place. To avoid using Merge, we are currently adding
|
||||
// observations to _each_ age bucket, i.e. the effort to add a sample is
|
||||
// essentially multiplied by the number of age buckets. When rotating age
|
||||
// buckets, we empty the previous head stream. On scrape time, we simply take
|
||||
// the quantiles from the head stream (no merging required). Result: More effort
|
||||
// on observation time, less effort on scrape time, which is exactly the
|
||||
// opposite of what we try to accomplish, but at least the results are correct.
|
||||
//
|
||||
// The quite elegant previous contraption to merge the age buckets efficiently
|
||||
// on scrape time (see code up commit 6b9530d72ea715f0ba612c0120e6e09fbf1d49d0)
|
||||
// can't be used anymore.
|
||||
|
||||
// NewSummary creates a new Summary based on the provided SummaryOpts.
|
||||
func NewSummary(opts SummaryOpts) Summary {
|
||||
return newSummary(
|
||||
NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
nil,
|
||||
opts.ConstLabels,
|
||||
),
|
||||
opts,
|
||||
)
|
||||
}
|
||||
|
||||
func newSummary(desc *Desc, opts SummaryOpts, labelValues ...string) Summary {
|
||||
if len(desc.variableLabels) != len(labelValues) {
|
||||
panic(makeInconsistentCardinalityError(desc.fqName, desc.variableLabels, labelValues))
|
||||
}
|
||||
|
||||
for _, n := range desc.variableLabels {
|
||||
if n == quantileLabel {
|
||||
panic(errQuantileLabelNotAllowed)
|
||||
}
|
||||
}
|
||||
for _, lp := range desc.constLabelPairs {
|
||||
if lp.GetName() == quantileLabel {
|
||||
panic(errQuantileLabelNotAllowed)
|
||||
}
|
||||
}
|
||||
|
||||
if opts.Objectives == nil {
|
||||
opts.Objectives = DefObjectives
|
||||
}
|
||||
|
||||
if opts.MaxAge < 0 {
|
||||
panic(fmt.Errorf("illegal max age MaxAge=%v", opts.MaxAge))
|
||||
}
|
||||
if opts.MaxAge == 0 {
|
||||
opts.MaxAge = DefMaxAge
|
||||
}
|
||||
|
||||
if opts.AgeBuckets == 0 {
|
||||
opts.AgeBuckets = DefAgeBuckets
|
||||
}
|
||||
|
||||
if opts.BufCap == 0 {
|
||||
opts.BufCap = DefBufCap
|
||||
}
|
||||
|
||||
s := &summary{
|
||||
desc: desc,
|
||||
|
||||
objectives: opts.Objectives,
|
||||
sortedObjectives: make([]float64, 0, len(opts.Objectives)),
|
||||
|
||||
labelPairs: makeLabelPairs(desc, labelValues),
|
||||
|
||||
hotBuf: make([]float64, 0, opts.BufCap),
|
||||
coldBuf: make([]float64, 0, opts.BufCap),
|
||||
streamDuration: opts.MaxAge / time.Duration(opts.AgeBuckets),
|
||||
}
|
||||
s.headStreamExpTime = time.Now().Add(s.streamDuration)
|
||||
s.hotBufExpTime = s.headStreamExpTime
|
||||
|
||||
for i := uint32(0); i < opts.AgeBuckets; i++ {
|
||||
s.streams = append(s.streams, s.newStream())
|
||||
}
|
||||
s.headStream = s.streams[0]
|
||||
|
||||
for qu := range s.objectives {
|
||||
s.sortedObjectives = append(s.sortedObjectives, qu)
|
||||
}
|
||||
sort.Float64s(s.sortedObjectives)
|
||||
|
||||
s.init(s) // Init self-collection.
|
||||
return s
|
||||
}
|
||||
|
||||
type summary struct {
|
||||
selfCollector
|
||||
|
||||
bufMtx sync.Mutex // Protects hotBuf and hotBufExpTime.
|
||||
mtx sync.Mutex // Protects every other moving part.
|
||||
// Lock bufMtx before mtx if both are needed.
|
||||
|
||||
desc *Desc
|
||||
|
||||
objectives map[float64]float64
|
||||
sortedObjectives []float64
|
||||
|
||||
labelPairs []*dto.LabelPair
|
||||
|
||||
sum float64
|
||||
cnt uint64
|
||||
|
||||
hotBuf, coldBuf []float64
|
||||
|
||||
streams []*quantile.Stream
|
||||
streamDuration time.Duration
|
||||
headStream *quantile.Stream
|
||||
headStreamIdx int
|
||||
headStreamExpTime, hotBufExpTime time.Time
|
||||
}
|
||||
|
||||
func (s *summary) Desc() *Desc {
|
||||
return s.desc
|
||||
}
|
||||
|
||||
func (s *summary) Observe(v float64) {
|
||||
s.bufMtx.Lock()
|
||||
defer s.bufMtx.Unlock()
|
||||
|
||||
now := time.Now()
|
||||
if now.After(s.hotBufExpTime) {
|
||||
s.asyncFlush(now)
|
||||
}
|
||||
s.hotBuf = append(s.hotBuf, v)
|
||||
if len(s.hotBuf) == cap(s.hotBuf) {
|
||||
s.asyncFlush(now)
|
||||
}
|
||||
}
|
||||
|
||||
func (s *summary) Write(out *dto.Metric) error {
|
||||
sum := &dto.Summary{}
|
||||
qs := make([]*dto.Quantile, 0, len(s.objectives))
|
||||
|
||||
s.bufMtx.Lock()
|
||||
s.mtx.Lock()
|
||||
// Swap bufs even if hotBuf is empty to set new hotBufExpTime.
|
||||
s.swapBufs(time.Now())
|
||||
s.bufMtx.Unlock()
|
||||
|
||||
s.flushColdBuf()
|
||||
sum.SampleCount = proto.Uint64(s.cnt)
|
||||
sum.SampleSum = proto.Float64(s.sum)
|
||||
|
||||
for _, rank := range s.sortedObjectives {
|
||||
var q float64
|
||||
if s.headStream.Count() == 0 {
|
||||
q = math.NaN()
|
||||
} else {
|
||||
q = s.headStream.Query(rank)
|
||||
}
|
||||
qs = append(qs, &dto.Quantile{
|
||||
Quantile: proto.Float64(rank),
|
||||
Value: proto.Float64(q),
|
||||
})
|
||||
}
|
||||
|
||||
s.mtx.Unlock()
|
||||
|
||||
if len(qs) > 0 {
|
||||
sort.Sort(quantSort(qs))
|
||||
}
|
||||
sum.Quantile = qs
|
||||
|
||||
out.Summary = sum
|
||||
out.Label = s.labelPairs
|
||||
return nil
|
||||
}
|
||||
|
||||
func (s *summary) newStream() *quantile.Stream {
|
||||
return quantile.NewTargeted(s.objectives)
|
||||
}
|
||||
|
||||
// asyncFlush needs bufMtx locked.
|
||||
func (s *summary) asyncFlush(now time.Time) {
|
||||
s.mtx.Lock()
|
||||
s.swapBufs(now)
|
||||
|
||||
// Unblock the original goroutine that was responsible for the mutation
|
||||
// that triggered the compaction. But hold onto the global non-buffer
|
||||
// state mutex until the operation finishes.
|
||||
go func() {
|
||||
s.flushColdBuf()
|
||||
s.mtx.Unlock()
|
||||
}()
|
||||
}
|
||||
|
||||
// rotateStreams needs mtx AND bufMtx locked.
|
||||
func (s *summary) maybeRotateStreams() {
|
||||
for !s.hotBufExpTime.Equal(s.headStreamExpTime) {
|
||||
s.headStream.Reset()
|
||||
s.headStreamIdx++
|
||||
if s.headStreamIdx >= len(s.streams) {
|
||||
s.headStreamIdx = 0
|
||||
}
|
||||
s.headStream = s.streams[s.headStreamIdx]
|
||||
s.headStreamExpTime = s.headStreamExpTime.Add(s.streamDuration)
|
||||
}
|
||||
}
|
||||
|
||||
// flushColdBuf needs mtx locked.
|
||||
func (s *summary) flushColdBuf() {
|
||||
for _, v := range s.coldBuf {
|
||||
for _, stream := range s.streams {
|
||||
stream.Insert(v)
|
||||
}
|
||||
s.cnt++
|
||||
s.sum += v
|
||||
}
|
||||
s.coldBuf = s.coldBuf[0:0]
|
||||
s.maybeRotateStreams()
|
||||
}
|
||||
|
||||
// swapBufs needs mtx AND bufMtx locked, coldBuf must be empty.
|
||||
func (s *summary) swapBufs(now time.Time) {
|
||||
if len(s.coldBuf) != 0 {
|
||||
panic("coldBuf is not empty")
|
||||
}
|
||||
s.hotBuf, s.coldBuf = s.coldBuf, s.hotBuf
|
||||
// hotBuf is now empty and gets new expiration set.
|
||||
for now.After(s.hotBufExpTime) {
|
||||
s.hotBufExpTime = s.hotBufExpTime.Add(s.streamDuration)
|
||||
}
|
||||
}
|
||||
|
||||
type quantSort []*dto.Quantile
|
||||
|
||||
func (s quantSort) Len() int {
|
||||
return len(s)
|
||||
}
|
||||
|
||||
func (s quantSort) Swap(i, j int) {
|
||||
s[i], s[j] = s[j], s[i]
|
||||
}
|
||||
|
||||
func (s quantSort) Less(i, j int) bool {
|
||||
return s[i].GetQuantile() < s[j].GetQuantile()
|
||||
}
|
||||
|
||||
// SummaryVec is a Collector that bundles a set of Summaries that all share the
|
||||
// same Desc, but have different values for their variable labels. This is used
|
||||
// if you want to count the same thing partitioned by various dimensions
|
||||
// (e.g. HTTP request latencies, partitioned by status code and method). Create
|
||||
// instances with NewSummaryVec.
|
||||
type SummaryVec struct {
|
||||
*metricVec
|
||||
}
|
||||
|
||||
// NewSummaryVec creates a new SummaryVec based on the provided SummaryOpts and
|
||||
// partitioned by the given label names.
|
||||
//
|
||||
// Due to the way a Summary is represented in the Prometheus text format and how
|
||||
// it is handled by the Prometheus server internally, “quantile” is an illegal
|
||||
// label name. NewSummaryVec will panic if this label name is used.
|
||||
func NewSummaryVec(opts SummaryOpts, labelNames []string) *SummaryVec {
|
||||
for _, ln := range labelNames {
|
||||
if ln == quantileLabel {
|
||||
panic(errQuantileLabelNotAllowed)
|
||||
}
|
||||
}
|
||||
desc := NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
labelNames,
|
||||
opts.ConstLabels,
|
||||
)
|
||||
return &SummaryVec{
|
||||
metricVec: newMetricVec(desc, func(lvs ...string) Metric {
|
||||
return newSummary(desc, opts, lvs...)
|
||||
}),
|
||||
}
|
||||
}
|
||||
|
||||
// GetMetricWithLabelValues returns the Summary for the given slice of label
|
||||
// values (same order as the VariableLabels in Desc). If that combination of
|
||||
// label values is accessed for the first time, a new Summary is created.
|
||||
//
|
||||
// It is possible to call this method without using the returned Summary to only
|
||||
// create the new Summary but leave it at its starting value, a Summary without
|
||||
// any observations.
|
||||
//
|
||||
// Keeping the Summary for later use is possible (and should be considered if
|
||||
// performance is critical), but keep in mind that Reset, DeleteLabelValues and
|
||||
// Delete can be used to delete the Summary from the SummaryVec. In that case,
|
||||
// the Summary will still exist, but it will not be exported anymore, even if a
|
||||
// Summary with the same label values is created later. See also the CounterVec
|
||||
// example.
|
||||
//
|
||||
// An error is returned if the number of label values is not the same as the
|
||||
// number of VariableLabels in Desc (minus any curried labels).
|
||||
//
|
||||
// Note that for more than one label value, this method is prone to mistakes
|
||||
// caused by an incorrect order of arguments. Consider GetMetricWith(Labels) as
|
||||
// an alternative to avoid that type of mistake. For higher label numbers, the
|
||||
// latter has a much more readable (albeit more verbose) syntax, but it comes
|
||||
// with a performance overhead (for creating and processing the Labels map).
|
||||
// See also the GaugeVec example.
|
||||
func (v *SummaryVec) GetMetricWithLabelValues(lvs ...string) (Observer, error) {
|
||||
metric, err := v.metricVec.getMetricWithLabelValues(lvs...)
|
||||
if metric != nil {
|
||||
return metric.(Observer), err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// GetMetricWith returns the Summary for the given Labels map (the label names
|
||||
// must match those of the VariableLabels in Desc). If that label map is
|
||||
// accessed for the first time, a new Summary is created. Implications of
|
||||
// creating a Summary without using it and keeping the Summary for later use are
|
||||
// the same as for GetMetricWithLabelValues.
|
||||
//
|
||||
// An error is returned if the number and names of the Labels are inconsistent
|
||||
// with those of the VariableLabels in Desc (minus any curried labels).
|
||||
//
|
||||
// This method is used for the same purpose as
|
||||
// GetMetricWithLabelValues(...string). See there for pros and cons of the two
|
||||
// methods.
|
||||
func (v *SummaryVec) GetMetricWith(labels Labels) (Observer, error) {
|
||||
metric, err := v.metricVec.getMetricWith(labels)
|
||||
if metric != nil {
|
||||
return metric.(Observer), err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// WithLabelValues works as GetMetricWithLabelValues, but panics where
|
||||
// GetMetricWithLabelValues would have returned an error. Not returning an
|
||||
// error allows shortcuts like
|
||||
// myVec.WithLabelValues("404", "GET").Observe(42.21)
|
||||
func (v *SummaryVec) WithLabelValues(lvs ...string) Observer {
|
||||
s, err := v.GetMetricWithLabelValues(lvs...)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return s
|
||||
}
|
||||
|
||||
// With works as GetMetricWith, but panics where GetMetricWithLabels would have
|
||||
// returned an error. Not returning an error allows shortcuts like
|
||||
// myVec.With(prometheus.Labels{"code": "404", "method": "GET"}).Observe(42.21)
|
||||
func (v *SummaryVec) With(labels Labels) Observer {
|
||||
s, err := v.GetMetricWith(labels)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return s
|
||||
}
|
||||
|
||||
// CurryWith returns a vector curried with the provided labels, i.e. the
|
||||
// returned vector has those labels pre-set for all labeled operations performed
|
||||
// on it. The cardinality of the curried vector is reduced accordingly. The
|
||||
// order of the remaining labels stays the same (just with the curried labels
|
||||
// taken out of the sequence – which is relevant for the
|
||||
// (GetMetric)WithLabelValues methods). It is possible to curry a curried
|
||||
// vector, but only with labels not yet used for currying before.
|
||||
//
|
||||
// The metrics contained in the SummaryVec are shared between the curried and
|
||||
// uncurried vectors. They are just accessed differently. Curried and uncurried
|
||||
// vectors behave identically in terms of collection. Only one must be
|
||||
// registered with a given registry (usually the uncurried version). The Reset
|
||||
// method deletes all metrics, even if called on a curried vector.
|
||||
func (v *SummaryVec) CurryWith(labels Labels) (ObserverVec, error) {
|
||||
vec, err := v.curryWith(labels)
|
||||
if vec != nil {
|
||||
return &SummaryVec{vec}, err
|
||||
}
|
||||
return nil, err
|
||||
}
|
||||
|
||||
// MustCurryWith works as CurryWith but panics where CurryWith would have
|
||||
// returned an error.
|
||||
func (v *SummaryVec) MustCurryWith(labels Labels) ObserverVec {
|
||||
vec, err := v.CurryWith(labels)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return vec
|
||||
}
|
||||
|
||||
type constSummary struct {
|
||||
desc *Desc
|
||||
count uint64
|
||||
sum float64
|
||||
quantiles map[float64]float64
|
||||
labelPairs []*dto.LabelPair
|
||||
}
|
||||
|
||||
func (s *constSummary) Desc() *Desc {
|
||||
return s.desc
|
||||
}
|
||||
|
||||
func (s *constSummary) Write(out *dto.Metric) error {
|
||||
sum := &dto.Summary{}
|
||||
qs := make([]*dto.Quantile, 0, len(s.quantiles))
|
||||
|
||||
sum.SampleCount = proto.Uint64(s.count)
|
||||
sum.SampleSum = proto.Float64(s.sum)
|
||||
|
||||
for rank, q := range s.quantiles {
|
||||
qs = append(qs, &dto.Quantile{
|
||||
Quantile: proto.Float64(rank),
|
||||
Value: proto.Float64(q),
|
||||
})
|
||||
}
|
||||
|
||||
if len(qs) > 0 {
|
||||
sort.Sort(quantSort(qs))
|
||||
}
|
||||
sum.Quantile = qs
|
||||
|
||||
out.Summary = sum
|
||||
out.Label = s.labelPairs
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
// NewConstSummary returns a metric representing a Prometheus summary with fixed
|
||||
// values for the count, sum, and quantiles. As those parameters cannot be
|
||||
// changed, the returned value does not implement the Summary interface (but
|
||||
// only the Metric interface). Users of this package will not have much use for
|
||||
// it in regular operations. However, when implementing custom Collectors, it is
|
||||
// useful as a throw-away metric that is generated on the fly to send it to
|
||||
// Prometheus in the Collect method.
|
||||
//
|
||||
// quantiles maps ranks to quantile values. For example, a median latency of
|
||||
// 0.23s and a 99th percentile latency of 0.56s would be expressed as:
|
||||
// map[float64]float64{0.5: 0.23, 0.99: 0.56}
|
||||
//
|
||||
// NewConstSummary returns an error if the length of labelValues is not
|
||||
// consistent with the variable labels in Desc or if Desc is invalid.
|
||||
func NewConstSummary(
|
||||
desc *Desc,
|
||||
count uint64,
|
||||
sum float64,
|
||||
quantiles map[float64]float64,
|
||||
labelValues ...string,
|
||||
) (Metric, error) {
|
||||
if desc.err != nil {
|
||||
return nil, desc.err
|
||||
}
|
||||
if err := validateLabelValues(labelValues, len(desc.variableLabels)); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return &constSummary{
|
||||
desc: desc,
|
||||
count: count,
|
||||
sum: sum,
|
||||
quantiles: quantiles,
|
||||
labelPairs: makeLabelPairs(desc, labelValues),
|
||||
}, nil
|
||||
}
|
||||
|
||||
// MustNewConstSummary is a version of NewConstSummary that panics where
|
||||
// NewConstMetric would have returned an error.
|
||||
func MustNewConstSummary(
|
||||
desc *Desc,
|
||||
count uint64,
|
||||
sum float64,
|
||||
quantiles map[float64]float64,
|
||||
labelValues ...string,
|
||||
) Metric {
|
||||
m, err := NewConstSummary(desc, count, sum, quantiles, labelValues...)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return m
|
||||
}
|
||||
54
watchdog/vendor/github.com/prometheus/client_golang/prometheus/timer.go
generated
vendored
54
watchdog/vendor/github.com/prometheus/client_golang/prometheus/timer.go
generated
vendored
@ -1,54 +0,0 @@
|
||||
// Copyright 2016 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import "time"
|
||||
|
||||
// Timer is a helper type to time functions. Use NewTimer to create new
|
||||
// instances.
|
||||
type Timer struct {
|
||||
begin time.Time
|
||||
observer Observer
|
||||
}
|
||||
|
||||
// NewTimer creates a new Timer. The provided Observer is used to observe a
|
||||
// duration in seconds. Timer is usually used to time a function call in the
|
||||
// following way:
|
||||
// func TimeMe() {
|
||||
// timer := NewTimer(myHistogram)
|
||||
// defer timer.ObserveDuration()
|
||||
// // Do actual work.
|
||||
// }
|
||||
func NewTimer(o Observer) *Timer {
|
||||
return &Timer{
|
||||
begin: time.Now(),
|
||||
observer: o,
|
||||
}
|
||||
}
|
||||
|
||||
// ObserveDuration records the duration passed since the Timer was created with
|
||||
// NewTimer. It calls the Observe method of the Observer provided during
|
||||
// construction with the duration in seconds as an argument. The observed
|
||||
// duration is also returned. ObserveDuration is usually called with a defer
|
||||
// statement.
|
||||
//
|
||||
// Note that this method is only guaranteed to never observe negative durations
|
||||
// if used with Go1.9+.
|
||||
func (t *Timer) ObserveDuration() time.Duration {
|
||||
d := time.Since(t.begin)
|
||||
if t.observer != nil {
|
||||
t.observer.Observe(d.Seconds())
|
||||
}
|
||||
return d
|
||||
}
|
||||
42
watchdog/vendor/github.com/prometheus/client_golang/prometheus/untyped.go
generated
vendored
42
watchdog/vendor/github.com/prometheus/client_golang/prometheus/untyped.go
generated
vendored
@ -1,42 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
// UntypedOpts is an alias for Opts. See there for doc comments.
|
||||
type UntypedOpts Opts
|
||||
|
||||
// UntypedFunc works like GaugeFunc but the collected metric is of type
|
||||
// "Untyped". UntypedFunc is useful to mirror an external metric of unknown
|
||||
// type.
|
||||
//
|
||||
// To create UntypedFunc instances, use NewUntypedFunc.
|
||||
type UntypedFunc interface {
|
||||
Metric
|
||||
Collector
|
||||
}
|
||||
|
||||
// NewUntypedFunc creates a new UntypedFunc based on the provided
|
||||
// UntypedOpts. The value reported is determined by calling the given function
|
||||
// from within the Write method. Take into account that metric collection may
|
||||
// happen concurrently. If that results in concurrent calls to Write, like in
|
||||
// the case where an UntypedFunc is directly registered with Prometheus, the
|
||||
// provided function must be concurrency-safe.
|
||||
func NewUntypedFunc(opts UntypedOpts, function func() float64) UntypedFunc {
|
||||
return newValueFunc(NewDesc(
|
||||
BuildFQName(opts.Namespace, opts.Subsystem, opts.Name),
|
||||
opts.Help,
|
||||
nil,
|
||||
opts.ConstLabels,
|
||||
), UntypedValue, function)
|
||||
}
|
||||
162
watchdog/vendor/github.com/prometheus/client_golang/prometheus/value.go
generated
vendored
162
watchdog/vendor/github.com/prometheus/client_golang/prometheus/value.go
generated
vendored
@ -1,162 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"sort"
|
||||
|
||||
"github.com/golang/protobuf/proto"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
)
|
||||
|
||||
// ValueType is an enumeration of metric types that represent a simple value.
|
||||
type ValueType int
|
||||
|
||||
// Possible values for the ValueType enum.
|
||||
const (
|
||||
_ ValueType = iota
|
||||
CounterValue
|
||||
GaugeValue
|
||||
UntypedValue
|
||||
)
|
||||
|
||||
// valueFunc is a generic metric for simple values retrieved on collect time
|
||||
// from a function. It implements Metric and Collector. Its effective type is
|
||||
// determined by ValueType. This is a low-level building block used by the
|
||||
// library to back the implementations of CounterFunc, GaugeFunc, and
|
||||
// UntypedFunc.
|
||||
type valueFunc struct {
|
||||
selfCollector
|
||||
|
||||
desc *Desc
|
||||
valType ValueType
|
||||
function func() float64
|
||||
labelPairs []*dto.LabelPair
|
||||
}
|
||||
|
||||
// newValueFunc returns a newly allocated valueFunc with the given Desc and
|
||||
// ValueType. The value reported is determined by calling the given function
|
||||
// from within the Write method. Take into account that metric collection may
|
||||
// happen concurrently. If that results in concurrent calls to Write, like in
|
||||
// the case where a valueFunc is directly registered with Prometheus, the
|
||||
// provided function must be concurrency-safe.
|
||||
func newValueFunc(desc *Desc, valueType ValueType, function func() float64) *valueFunc {
|
||||
result := &valueFunc{
|
||||
desc: desc,
|
||||
valType: valueType,
|
||||
function: function,
|
||||
labelPairs: makeLabelPairs(desc, nil),
|
||||
}
|
||||
result.init(result)
|
||||
return result
|
||||
}
|
||||
|
||||
func (v *valueFunc) Desc() *Desc {
|
||||
return v.desc
|
||||
}
|
||||
|
||||
func (v *valueFunc) Write(out *dto.Metric) error {
|
||||
return populateMetric(v.valType, v.function(), v.labelPairs, out)
|
||||
}
|
||||
|
||||
// NewConstMetric returns a metric with one fixed value that cannot be
|
||||
// changed. Users of this package will not have much use for it in regular
|
||||
// operations. However, when implementing custom Collectors, it is useful as a
|
||||
// throw-away metric that is generated on the fly to send it to Prometheus in
|
||||
// the Collect method. NewConstMetric returns an error if the length of
|
||||
// labelValues is not consistent with the variable labels in Desc or if Desc is
|
||||
// invalid.
|
||||
func NewConstMetric(desc *Desc, valueType ValueType, value float64, labelValues ...string) (Metric, error) {
|
||||
if desc.err != nil {
|
||||
return nil, desc.err
|
||||
}
|
||||
if err := validateLabelValues(labelValues, len(desc.variableLabels)); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return &constMetric{
|
||||
desc: desc,
|
||||
valType: valueType,
|
||||
val: value,
|
||||
labelPairs: makeLabelPairs(desc, labelValues),
|
||||
}, nil
|
||||
}
|
||||
|
||||
// MustNewConstMetric is a version of NewConstMetric that panics where
|
||||
// NewConstMetric would have returned an error.
|
||||
func MustNewConstMetric(desc *Desc, valueType ValueType, value float64, labelValues ...string) Metric {
|
||||
m, err := NewConstMetric(desc, valueType, value, labelValues...)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return m
|
||||
}
|
||||
|
||||
type constMetric struct {
|
||||
desc *Desc
|
||||
valType ValueType
|
||||
val float64
|
||||
labelPairs []*dto.LabelPair
|
||||
}
|
||||
|
||||
func (m *constMetric) Desc() *Desc {
|
||||
return m.desc
|
||||
}
|
||||
|
||||
func (m *constMetric) Write(out *dto.Metric) error {
|
||||
return populateMetric(m.valType, m.val, m.labelPairs, out)
|
||||
}
|
||||
|
||||
func populateMetric(
|
||||
t ValueType,
|
||||
v float64,
|
||||
labelPairs []*dto.LabelPair,
|
||||
m *dto.Metric,
|
||||
) error {
|
||||
m.Label = labelPairs
|
||||
switch t {
|
||||
case CounterValue:
|
||||
m.Counter = &dto.Counter{Value: proto.Float64(v)}
|
||||
case GaugeValue:
|
||||
m.Gauge = &dto.Gauge{Value: proto.Float64(v)}
|
||||
case UntypedValue:
|
||||
m.Untyped = &dto.Untyped{Value: proto.Float64(v)}
|
||||
default:
|
||||
return fmt.Errorf("encountered unknown type %v", t)
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func makeLabelPairs(desc *Desc, labelValues []string) []*dto.LabelPair {
|
||||
totalLen := len(desc.variableLabels) + len(desc.constLabelPairs)
|
||||
if totalLen == 0 {
|
||||
// Super fast path.
|
||||
return nil
|
||||
}
|
||||
if len(desc.variableLabels) == 0 {
|
||||
// Moderately fast path.
|
||||
return desc.constLabelPairs
|
||||
}
|
||||
labelPairs := make([]*dto.LabelPair, 0, totalLen)
|
||||
for i, n := range desc.variableLabels {
|
||||
labelPairs = append(labelPairs, &dto.LabelPair{
|
||||
Name: proto.String(n),
|
||||
Value: proto.String(labelValues[i]),
|
||||
})
|
||||
}
|
||||
labelPairs = append(labelPairs, desc.constLabelPairs...)
|
||||
sort.Sort(labelPairSorter(labelPairs))
|
||||
return labelPairs
|
||||
}
|
||||
472
watchdog/vendor/github.com/prometheus/client_golang/prometheus/vec.go
generated
vendored
472
watchdog/vendor/github.com/prometheus/client_golang/prometheus/vec.go
generated
vendored
@ -1,472 +0,0 @@
|
||||
// Copyright 2014 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"sync"
|
||||
|
||||
"github.com/prometheus/common/model"
|
||||
)
|
||||
|
||||
// metricVec is a Collector to bundle metrics of the same name that differ in
|
||||
// their label values. metricVec is not used directly (and therefore
|
||||
// unexported). It is used as a building block for implementations of vectors of
|
||||
// a given metric type, like GaugeVec, CounterVec, SummaryVec, and HistogramVec.
|
||||
// It also handles label currying. It uses basicMetricVec internally.
|
||||
type metricVec struct {
|
||||
*metricMap
|
||||
|
||||
curry []curriedLabelValue
|
||||
|
||||
// hashAdd and hashAddByte can be replaced for testing collision handling.
|
||||
hashAdd func(h uint64, s string) uint64
|
||||
hashAddByte func(h uint64, b byte) uint64
|
||||
}
|
||||
|
||||
// newMetricVec returns an initialized metricVec.
|
||||
func newMetricVec(desc *Desc, newMetric func(lvs ...string) Metric) *metricVec {
|
||||
return &metricVec{
|
||||
metricMap: &metricMap{
|
||||
metrics: map[uint64][]metricWithLabelValues{},
|
||||
desc: desc,
|
||||
newMetric: newMetric,
|
||||
},
|
||||
hashAdd: hashAdd,
|
||||
hashAddByte: hashAddByte,
|
||||
}
|
||||
}
|
||||
|
||||
// DeleteLabelValues removes the metric where the variable labels are the same
|
||||
// as those passed in as labels (same order as the VariableLabels in Desc). It
|
||||
// returns true if a metric was deleted.
|
||||
//
|
||||
// It is not an error if the number of label values is not the same as the
|
||||
// number of VariableLabels in Desc. However, such inconsistent label count can
|
||||
// never match an actual metric, so the method will always return false in that
|
||||
// case.
|
||||
//
|
||||
// Note that for more than one label value, this method is prone to mistakes
|
||||
// caused by an incorrect order of arguments. Consider Delete(Labels) as an
|
||||
// alternative to avoid that type of mistake. For higher label numbers, the
|
||||
// latter has a much more readable (albeit more verbose) syntax, but it comes
|
||||
// with a performance overhead (for creating and processing the Labels map).
|
||||
// See also the CounterVec example.
|
||||
func (m *metricVec) DeleteLabelValues(lvs ...string) bool {
|
||||
h, err := m.hashLabelValues(lvs)
|
||||
if err != nil {
|
||||
return false
|
||||
}
|
||||
|
||||
return m.metricMap.deleteByHashWithLabelValues(h, lvs, m.curry)
|
||||
}
|
||||
|
||||
// Delete deletes the metric where the variable labels are the same as those
|
||||
// passed in as labels. It returns true if a metric was deleted.
|
||||
//
|
||||
// It is not an error if the number and names of the Labels are inconsistent
|
||||
// with those of the VariableLabels in Desc. However, such inconsistent Labels
|
||||
// can never match an actual metric, so the method will always return false in
|
||||
// that case.
|
||||
//
|
||||
// This method is used for the same purpose as DeleteLabelValues(...string). See
|
||||
// there for pros and cons of the two methods.
|
||||
func (m *metricVec) Delete(labels Labels) bool {
|
||||
h, err := m.hashLabels(labels)
|
||||
if err != nil {
|
||||
return false
|
||||
}
|
||||
|
||||
return m.metricMap.deleteByHashWithLabels(h, labels, m.curry)
|
||||
}
|
||||
|
||||
func (m *metricVec) curryWith(labels Labels) (*metricVec, error) {
|
||||
var (
|
||||
newCurry []curriedLabelValue
|
||||
oldCurry = m.curry
|
||||
iCurry int
|
||||
)
|
||||
for i, label := range m.desc.variableLabels {
|
||||
val, ok := labels[label]
|
||||
if iCurry < len(oldCurry) && oldCurry[iCurry].index == i {
|
||||
if ok {
|
||||
return nil, fmt.Errorf("label name %q is already curried", label)
|
||||
}
|
||||
newCurry = append(newCurry, oldCurry[iCurry])
|
||||
iCurry++
|
||||
} else {
|
||||
if !ok {
|
||||
continue // Label stays uncurried.
|
||||
}
|
||||
newCurry = append(newCurry, curriedLabelValue{i, val})
|
||||
}
|
||||
}
|
||||
if l := len(oldCurry) + len(labels) - len(newCurry); l > 0 {
|
||||
return nil, fmt.Errorf("%d unknown label(s) found during currying", l)
|
||||
}
|
||||
|
||||
return &metricVec{
|
||||
metricMap: m.metricMap,
|
||||
curry: newCurry,
|
||||
hashAdd: m.hashAdd,
|
||||
hashAddByte: m.hashAddByte,
|
||||
}, nil
|
||||
}
|
||||
|
||||
func (m *metricVec) getMetricWithLabelValues(lvs ...string) (Metric, error) {
|
||||
h, err := m.hashLabelValues(lvs)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
return m.metricMap.getOrCreateMetricWithLabelValues(h, lvs, m.curry), nil
|
||||
}
|
||||
|
||||
func (m *metricVec) getMetricWith(labels Labels) (Metric, error) {
|
||||
h, err := m.hashLabels(labels)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
return m.metricMap.getOrCreateMetricWithLabels(h, labels, m.curry), nil
|
||||
}
|
||||
|
||||
func (m *metricVec) hashLabelValues(vals []string) (uint64, error) {
|
||||
if err := validateLabelValues(vals, len(m.desc.variableLabels)-len(m.curry)); err != nil {
|
||||
return 0, err
|
||||
}
|
||||
|
||||
var (
|
||||
h = hashNew()
|
||||
curry = m.curry
|
||||
iVals, iCurry int
|
||||
)
|
||||
for i := 0; i < len(m.desc.variableLabels); i++ {
|
||||
if iCurry < len(curry) && curry[iCurry].index == i {
|
||||
h = m.hashAdd(h, curry[iCurry].value)
|
||||
iCurry++
|
||||
} else {
|
||||
h = m.hashAdd(h, vals[iVals])
|
||||
iVals++
|
||||
}
|
||||
h = m.hashAddByte(h, model.SeparatorByte)
|
||||
}
|
||||
return h, nil
|
||||
}
|
||||
|
||||
func (m *metricVec) hashLabels(labels Labels) (uint64, error) {
|
||||
if err := validateValuesInLabels(labels, len(m.desc.variableLabels)-len(m.curry)); err != nil {
|
||||
return 0, err
|
||||
}
|
||||
|
||||
var (
|
||||
h = hashNew()
|
||||
curry = m.curry
|
||||
iCurry int
|
||||
)
|
||||
for i, label := range m.desc.variableLabels {
|
||||
val, ok := labels[label]
|
||||
if iCurry < len(curry) && curry[iCurry].index == i {
|
||||
if ok {
|
||||
return 0, fmt.Errorf("label name %q is already curried", label)
|
||||
}
|
||||
h = m.hashAdd(h, curry[iCurry].value)
|
||||
iCurry++
|
||||
} else {
|
||||
if !ok {
|
||||
return 0, fmt.Errorf("label name %q missing in label map", label)
|
||||
}
|
||||
h = m.hashAdd(h, val)
|
||||
}
|
||||
h = m.hashAddByte(h, model.SeparatorByte)
|
||||
}
|
||||
return h, nil
|
||||
}
|
||||
|
||||
// metricWithLabelValues provides the metric and its label values for
|
||||
// disambiguation on hash collision.
|
||||
type metricWithLabelValues struct {
|
||||
values []string
|
||||
metric Metric
|
||||
}
|
||||
|
||||
// curriedLabelValue sets the curried value for a label at the given index.
|
||||
type curriedLabelValue struct {
|
||||
index int
|
||||
value string
|
||||
}
|
||||
|
||||
// metricMap is a helper for metricVec and shared between differently curried
|
||||
// metricVecs.
|
||||
type metricMap struct {
|
||||
mtx sync.RWMutex // Protects metrics.
|
||||
metrics map[uint64][]metricWithLabelValues
|
||||
desc *Desc
|
||||
newMetric func(labelValues ...string) Metric
|
||||
}
|
||||
|
||||
// Describe implements Collector. It will send exactly one Desc to the provided
|
||||
// channel.
|
||||
func (m *metricMap) Describe(ch chan<- *Desc) {
|
||||
ch <- m.desc
|
||||
}
|
||||
|
||||
// Collect implements Collector.
|
||||
func (m *metricMap) Collect(ch chan<- Metric) {
|
||||
m.mtx.RLock()
|
||||
defer m.mtx.RUnlock()
|
||||
|
||||
for _, metrics := range m.metrics {
|
||||
for _, metric := range metrics {
|
||||
ch <- metric.metric
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Reset deletes all metrics in this vector.
|
||||
func (m *metricMap) Reset() {
|
||||
m.mtx.Lock()
|
||||
defer m.mtx.Unlock()
|
||||
|
||||
for h := range m.metrics {
|
||||
delete(m.metrics, h)
|
||||
}
|
||||
}
|
||||
|
||||
// deleteByHashWithLabelValues removes the metric from the hash bucket h. If
|
||||
// there are multiple matches in the bucket, use lvs to select a metric and
|
||||
// remove only that metric.
|
||||
func (m *metricMap) deleteByHashWithLabelValues(
|
||||
h uint64, lvs []string, curry []curriedLabelValue,
|
||||
) bool {
|
||||
m.mtx.Lock()
|
||||
defer m.mtx.Unlock()
|
||||
|
||||
metrics, ok := m.metrics[h]
|
||||
if !ok {
|
||||
return false
|
||||
}
|
||||
|
||||
i := findMetricWithLabelValues(metrics, lvs, curry)
|
||||
if i >= len(metrics) {
|
||||
return false
|
||||
}
|
||||
|
||||
if len(metrics) > 1 {
|
||||
m.metrics[h] = append(metrics[:i], metrics[i+1:]...)
|
||||
} else {
|
||||
delete(m.metrics, h)
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
// deleteByHashWithLabels removes the metric from the hash bucket h. If there
|
||||
// are multiple matches in the bucket, use lvs to select a metric and remove
|
||||
// only that metric.
|
||||
func (m *metricMap) deleteByHashWithLabels(
|
||||
h uint64, labels Labels, curry []curriedLabelValue,
|
||||
) bool {
|
||||
m.mtx.Lock()
|
||||
defer m.mtx.Unlock()
|
||||
|
||||
metrics, ok := m.metrics[h]
|
||||
if !ok {
|
||||
return false
|
||||
}
|
||||
i := findMetricWithLabels(m.desc, metrics, labels, curry)
|
||||
if i >= len(metrics) {
|
||||
return false
|
||||
}
|
||||
|
||||
if len(metrics) > 1 {
|
||||
m.metrics[h] = append(metrics[:i], metrics[i+1:]...)
|
||||
} else {
|
||||
delete(m.metrics, h)
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
// getOrCreateMetricWithLabelValues retrieves the metric by hash and label value
|
||||
// or creates it and returns the new one.
|
||||
//
|
||||
// This function holds the mutex.
|
||||
func (m *metricMap) getOrCreateMetricWithLabelValues(
|
||||
hash uint64, lvs []string, curry []curriedLabelValue,
|
||||
) Metric {
|
||||
m.mtx.RLock()
|
||||
metric, ok := m.getMetricWithHashAndLabelValues(hash, lvs, curry)
|
||||
m.mtx.RUnlock()
|
||||
if ok {
|
||||
return metric
|
||||
}
|
||||
|
||||
m.mtx.Lock()
|
||||
defer m.mtx.Unlock()
|
||||
metric, ok = m.getMetricWithHashAndLabelValues(hash, lvs, curry)
|
||||
if !ok {
|
||||
inlinedLVs := inlineLabelValues(lvs, curry)
|
||||
metric = m.newMetric(inlinedLVs...)
|
||||
m.metrics[hash] = append(m.metrics[hash], metricWithLabelValues{values: inlinedLVs, metric: metric})
|
||||
}
|
||||
return metric
|
||||
}
|
||||
|
||||
// getOrCreateMetricWithLabelValues retrieves the metric by hash and label value
|
||||
// or creates it and returns the new one.
|
||||
//
|
||||
// This function holds the mutex.
|
||||
func (m *metricMap) getOrCreateMetricWithLabels(
|
||||
hash uint64, labels Labels, curry []curriedLabelValue,
|
||||
) Metric {
|
||||
m.mtx.RLock()
|
||||
metric, ok := m.getMetricWithHashAndLabels(hash, labels, curry)
|
||||
m.mtx.RUnlock()
|
||||
if ok {
|
||||
return metric
|
||||
}
|
||||
|
||||
m.mtx.Lock()
|
||||
defer m.mtx.Unlock()
|
||||
metric, ok = m.getMetricWithHashAndLabels(hash, labels, curry)
|
||||
if !ok {
|
||||
lvs := extractLabelValues(m.desc, labels, curry)
|
||||
metric = m.newMetric(lvs...)
|
||||
m.metrics[hash] = append(m.metrics[hash], metricWithLabelValues{values: lvs, metric: metric})
|
||||
}
|
||||
return metric
|
||||
}
|
||||
|
||||
// getMetricWithHashAndLabelValues gets a metric while handling possible
|
||||
// collisions in the hash space. Must be called while holding the read mutex.
|
||||
func (m *metricMap) getMetricWithHashAndLabelValues(
|
||||
h uint64, lvs []string, curry []curriedLabelValue,
|
||||
) (Metric, bool) {
|
||||
metrics, ok := m.metrics[h]
|
||||
if ok {
|
||||
if i := findMetricWithLabelValues(metrics, lvs, curry); i < len(metrics) {
|
||||
return metrics[i].metric, true
|
||||
}
|
||||
}
|
||||
return nil, false
|
||||
}
|
||||
|
||||
// getMetricWithHashAndLabels gets a metric while handling possible collisions in
|
||||
// the hash space. Must be called while holding read mutex.
|
||||
func (m *metricMap) getMetricWithHashAndLabels(
|
||||
h uint64, labels Labels, curry []curriedLabelValue,
|
||||
) (Metric, bool) {
|
||||
metrics, ok := m.metrics[h]
|
||||
if ok {
|
||||
if i := findMetricWithLabels(m.desc, metrics, labels, curry); i < len(metrics) {
|
||||
return metrics[i].metric, true
|
||||
}
|
||||
}
|
||||
return nil, false
|
||||
}
|
||||
|
||||
// findMetricWithLabelValues returns the index of the matching metric or
|
||||
// len(metrics) if not found.
|
||||
func findMetricWithLabelValues(
|
||||
metrics []metricWithLabelValues, lvs []string, curry []curriedLabelValue,
|
||||
) int {
|
||||
for i, metric := range metrics {
|
||||
if matchLabelValues(metric.values, lvs, curry) {
|
||||
return i
|
||||
}
|
||||
}
|
||||
return len(metrics)
|
||||
}
|
||||
|
||||
// findMetricWithLabels returns the index of the matching metric or len(metrics)
|
||||
// if not found.
|
||||
func findMetricWithLabels(
|
||||
desc *Desc, metrics []metricWithLabelValues, labels Labels, curry []curriedLabelValue,
|
||||
) int {
|
||||
for i, metric := range metrics {
|
||||
if matchLabels(desc, metric.values, labels, curry) {
|
||||
return i
|
||||
}
|
||||
}
|
||||
return len(metrics)
|
||||
}
|
||||
|
||||
func matchLabelValues(values []string, lvs []string, curry []curriedLabelValue) bool {
|
||||
if len(values) != len(lvs)+len(curry) {
|
||||
return false
|
||||
}
|
||||
var iLVs, iCurry int
|
||||
for i, v := range values {
|
||||
if iCurry < len(curry) && curry[iCurry].index == i {
|
||||
if v != curry[iCurry].value {
|
||||
return false
|
||||
}
|
||||
iCurry++
|
||||
continue
|
||||
}
|
||||
if v != lvs[iLVs] {
|
||||
return false
|
||||
}
|
||||
iLVs++
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
func matchLabels(desc *Desc, values []string, labels Labels, curry []curriedLabelValue) bool {
|
||||
if len(values) != len(labels)+len(curry) {
|
||||
return false
|
||||
}
|
||||
iCurry := 0
|
||||
for i, k := range desc.variableLabels {
|
||||
if iCurry < len(curry) && curry[iCurry].index == i {
|
||||
if values[i] != curry[iCurry].value {
|
||||
return false
|
||||
}
|
||||
iCurry++
|
||||
continue
|
||||
}
|
||||
if values[i] != labels[k] {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
func extractLabelValues(desc *Desc, labels Labels, curry []curriedLabelValue) []string {
|
||||
labelValues := make([]string, len(labels)+len(curry))
|
||||
iCurry := 0
|
||||
for i, k := range desc.variableLabels {
|
||||
if iCurry < len(curry) && curry[iCurry].index == i {
|
||||
labelValues[i] = curry[iCurry].value
|
||||
iCurry++
|
||||
continue
|
||||
}
|
||||
labelValues[i] = labels[k]
|
||||
}
|
||||
return labelValues
|
||||
}
|
||||
|
||||
func inlineLabelValues(lvs []string, curry []curriedLabelValue) []string {
|
||||
labelValues := make([]string, len(lvs)+len(curry))
|
||||
var iCurry, iLVs int
|
||||
for i := range labelValues {
|
||||
if iCurry < len(curry) && curry[iCurry].index == i {
|
||||
labelValues[i] = curry[iCurry].value
|
||||
iCurry++
|
||||
continue
|
||||
}
|
||||
labelValues[i] = lvs[iLVs]
|
||||
iLVs++
|
||||
}
|
||||
return labelValues
|
||||
}
|
||||
179
watchdog/vendor/github.com/prometheus/client_golang/prometheus/wrap.go
generated
vendored
179
watchdog/vendor/github.com/prometheus/client_golang/prometheus/wrap.go
generated
vendored
@ -1,179 +0,0 @@
|
||||
// Copyright 2018 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package prometheus
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"sort"
|
||||
|
||||
"github.com/golang/protobuf/proto"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
)
|
||||
|
||||
// WrapRegistererWith returns a Registerer wrapping the provided
|
||||
// Registerer. Collectors registered with the returned Registerer will be
|
||||
// registered with the wrapped Registerer in a modified way. The modified
|
||||
// Collector adds the provided Labels to all Metrics it collects (as
|
||||
// ConstLabels). The Metrics collected by the unmodified Collector must not
|
||||
// duplicate any of those labels.
|
||||
//
|
||||
// WrapRegistererWith provides a way to add fixed labels to a subset of
|
||||
// Collectors. It should not be used to add fixed labels to all metrics exposed.
|
||||
//
|
||||
// The Collector example demonstrates a use of WrapRegistererWith.
|
||||
func WrapRegistererWith(labels Labels, reg Registerer) Registerer {
|
||||
return &wrappingRegisterer{
|
||||
wrappedRegisterer: reg,
|
||||
labels: labels,
|
||||
}
|
||||
}
|
||||
|
||||
// WrapRegistererWithPrefix returns a Registerer wrapping the provided
|
||||
// Registerer. Collectors registered with the returned Registerer will be
|
||||
// registered with the wrapped Registerer in a modified way. The modified
|
||||
// Collector adds the provided prefix to the name of all Metrics it collects.
|
||||
//
|
||||
// WrapRegistererWithPrefix is useful to have one place to prefix all metrics of
|
||||
// a sub-system. To make this work, register metrics of the sub-system with the
|
||||
// wrapping Registerer returned by WrapRegistererWithPrefix. It is rarely useful
|
||||
// to use the same prefix for all metrics exposed. In particular, do not prefix
|
||||
// metric names that are standardized across applications, as that would break
|
||||
// horizontal monitoring, for example the metrics provided by the Go collector
|
||||
// (see NewGoCollector) and the process collector (see NewProcessCollector). (In
|
||||
// fact, those metrics are already prefixed with “go_” or “process_”,
|
||||
// respectively.)
|
||||
func WrapRegistererWithPrefix(prefix string, reg Registerer) Registerer {
|
||||
return &wrappingRegisterer{
|
||||
wrappedRegisterer: reg,
|
||||
prefix: prefix,
|
||||
}
|
||||
}
|
||||
|
||||
type wrappingRegisterer struct {
|
||||
wrappedRegisterer Registerer
|
||||
prefix string
|
||||
labels Labels
|
||||
}
|
||||
|
||||
func (r *wrappingRegisterer) Register(c Collector) error {
|
||||
return r.wrappedRegisterer.Register(&wrappingCollector{
|
||||
wrappedCollector: c,
|
||||
prefix: r.prefix,
|
||||
labels: r.labels,
|
||||
})
|
||||
}
|
||||
|
||||
func (r *wrappingRegisterer) MustRegister(cs ...Collector) {
|
||||
for _, c := range cs {
|
||||
if err := r.Register(c); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (r *wrappingRegisterer) Unregister(c Collector) bool {
|
||||
return r.wrappedRegisterer.Unregister(&wrappingCollector{
|
||||
wrappedCollector: c,
|
||||
prefix: r.prefix,
|
||||
labels: r.labels,
|
||||
})
|
||||
}
|
||||
|
||||
type wrappingCollector struct {
|
||||
wrappedCollector Collector
|
||||
prefix string
|
||||
labels Labels
|
||||
}
|
||||
|
||||
func (c *wrappingCollector) Collect(ch chan<- Metric) {
|
||||
wrappedCh := make(chan Metric)
|
||||
go func() {
|
||||
c.wrappedCollector.Collect(wrappedCh)
|
||||
close(wrappedCh)
|
||||
}()
|
||||
for m := range wrappedCh {
|
||||
ch <- &wrappingMetric{
|
||||
wrappedMetric: m,
|
||||
prefix: c.prefix,
|
||||
labels: c.labels,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (c *wrappingCollector) Describe(ch chan<- *Desc) {
|
||||
wrappedCh := make(chan *Desc)
|
||||
go func() {
|
||||
c.wrappedCollector.Describe(wrappedCh)
|
||||
close(wrappedCh)
|
||||
}()
|
||||
for desc := range wrappedCh {
|
||||
ch <- wrapDesc(desc, c.prefix, c.labels)
|
||||
}
|
||||
}
|
||||
|
||||
type wrappingMetric struct {
|
||||
wrappedMetric Metric
|
||||
prefix string
|
||||
labels Labels
|
||||
}
|
||||
|
||||
func (m *wrappingMetric) Desc() *Desc {
|
||||
return wrapDesc(m.wrappedMetric.Desc(), m.prefix, m.labels)
|
||||
}
|
||||
|
||||
func (m *wrappingMetric) Write(out *dto.Metric) error {
|
||||
if err := m.wrappedMetric.Write(out); err != nil {
|
||||
return err
|
||||
}
|
||||
if len(m.labels) == 0 {
|
||||
// No wrapping labels.
|
||||
return nil
|
||||
}
|
||||
for ln, lv := range m.labels {
|
||||
out.Label = append(out.Label, &dto.LabelPair{
|
||||
Name: proto.String(ln),
|
||||
Value: proto.String(lv),
|
||||
})
|
||||
}
|
||||
sort.Sort(labelPairSorter(out.Label))
|
||||
return nil
|
||||
}
|
||||
|
||||
func wrapDesc(desc *Desc, prefix string, labels Labels) *Desc {
|
||||
constLabels := Labels{}
|
||||
for _, lp := range desc.constLabelPairs {
|
||||
constLabels[*lp.Name] = *lp.Value
|
||||
}
|
||||
for ln, lv := range labels {
|
||||
if _, alreadyUsed := constLabels[ln]; alreadyUsed {
|
||||
return &Desc{
|
||||
fqName: desc.fqName,
|
||||
help: desc.help,
|
||||
variableLabels: desc.variableLabels,
|
||||
constLabelPairs: desc.constLabelPairs,
|
||||
err: fmt.Errorf("attempted wrapping with already existing label name %q", ln),
|
||||
}
|
||||
}
|
||||
constLabels[ln] = lv
|
||||
}
|
||||
// NewDesc will do remaining validations.
|
||||
newDesc := NewDesc(prefix+desc.fqName, desc.help, desc.variableLabels, constLabels)
|
||||
// Propagate errors if there was any. This will override any errer
|
||||
// created by NewDesc above, i.e. earlier errors get precedence.
|
||||
if desc.err != nil {
|
||||
newDesc.err = desc.err
|
||||
}
|
||||
return newDesc
|
||||
}
|
||||
201
watchdog/vendor/github.com/prometheus/client_model/LICENSE
generated
vendored
201
watchdog/vendor/github.com/prometheus/client_model/LICENSE
generated
vendored
@ -1,201 +0,0 @@
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright [yyyy] [name of copyright owner]
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
5
watchdog/vendor/github.com/prometheus/client_model/NOTICE
generated
vendored
5
watchdog/vendor/github.com/prometheus/client_model/NOTICE
generated
vendored
@ -1,5 +0,0 @@
|
||||
Data model artifacts for Prometheus.
|
||||
Copyright 2012-2015 The Prometheus Authors
|
||||
|
||||
This product includes software developed at
|
||||
SoundCloud Ltd. (http://soundcloud.com/).
|
||||
629
watchdog/vendor/github.com/prometheus/client_model/go/metrics.pb.go
generated
vendored
629
watchdog/vendor/github.com/prometheus/client_model/go/metrics.pb.go
generated
vendored
@ -1,629 +0,0 @@
|
||||
// Code generated by protoc-gen-go. DO NOT EDIT.
|
||||
// source: metrics.proto
|
||||
|
||||
package io_prometheus_client // import "github.com/prometheus/client_model/go"
|
||||
|
||||
import proto "github.com/golang/protobuf/proto"
|
||||
import fmt "fmt"
|
||||
import math "math"
|
||||
|
||||
// Reference imports to suppress errors if they are not otherwise used.
|
||||
var _ = proto.Marshal
|
||||
var _ = fmt.Errorf
|
||||
var _ = math.Inf
|
||||
|
||||
// This is a compile-time assertion to ensure that this generated file
|
||||
// is compatible with the proto package it is being compiled against.
|
||||
// A compilation error at this line likely means your copy of the
|
||||
// proto package needs to be updated.
|
||||
const _ = proto.ProtoPackageIsVersion2 // please upgrade the proto package
|
||||
|
||||
type MetricType int32
|
||||
|
||||
const (
|
||||
MetricType_COUNTER MetricType = 0
|
||||
MetricType_GAUGE MetricType = 1
|
||||
MetricType_SUMMARY MetricType = 2
|
||||
MetricType_UNTYPED MetricType = 3
|
||||
MetricType_HISTOGRAM MetricType = 4
|
||||
)
|
||||
|
||||
var MetricType_name = map[int32]string{
|
||||
0: "COUNTER",
|
||||
1: "GAUGE",
|
||||
2: "SUMMARY",
|
||||
3: "UNTYPED",
|
||||
4: "HISTOGRAM",
|
||||
}
|
||||
var MetricType_value = map[string]int32{
|
||||
"COUNTER": 0,
|
||||
"GAUGE": 1,
|
||||
"SUMMARY": 2,
|
||||
"UNTYPED": 3,
|
||||
"HISTOGRAM": 4,
|
||||
}
|
||||
|
||||
func (x MetricType) Enum() *MetricType {
|
||||
p := new(MetricType)
|
||||
*p = x
|
||||
return p
|
||||
}
|
||||
func (x MetricType) String() string {
|
||||
return proto.EnumName(MetricType_name, int32(x))
|
||||
}
|
||||
func (x *MetricType) UnmarshalJSON(data []byte) error {
|
||||
value, err := proto.UnmarshalJSONEnum(MetricType_value, data, "MetricType")
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
*x = MetricType(value)
|
||||
return nil
|
||||
}
|
||||
func (MetricType) EnumDescriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{0}
|
||||
}
|
||||
|
||||
type LabelPair struct {
|
||||
Name *string `protobuf:"bytes,1,opt,name=name" json:"name,omitempty"`
|
||||
Value *string `protobuf:"bytes,2,opt,name=value" json:"value,omitempty"`
|
||||
XXX_NoUnkeyedLiteral struct{} `json:"-"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
XXX_sizecache int32 `json:"-"`
|
||||
}
|
||||
|
||||
func (m *LabelPair) Reset() { *m = LabelPair{} }
|
||||
func (m *LabelPair) String() string { return proto.CompactTextString(m) }
|
||||
func (*LabelPair) ProtoMessage() {}
|
||||
func (*LabelPair) Descriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{0}
|
||||
}
|
||||
func (m *LabelPair) XXX_Unmarshal(b []byte) error {
|
||||
return xxx_messageInfo_LabelPair.Unmarshal(m, b)
|
||||
}
|
||||
func (m *LabelPair) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
|
||||
return xxx_messageInfo_LabelPair.Marshal(b, m, deterministic)
|
||||
}
|
||||
func (dst *LabelPair) XXX_Merge(src proto.Message) {
|
||||
xxx_messageInfo_LabelPair.Merge(dst, src)
|
||||
}
|
||||
func (m *LabelPair) XXX_Size() int {
|
||||
return xxx_messageInfo_LabelPair.Size(m)
|
||||
}
|
||||
func (m *LabelPair) XXX_DiscardUnknown() {
|
||||
xxx_messageInfo_LabelPair.DiscardUnknown(m)
|
||||
}
|
||||
|
||||
var xxx_messageInfo_LabelPair proto.InternalMessageInfo
|
||||
|
||||
func (m *LabelPair) GetName() string {
|
||||
if m != nil && m.Name != nil {
|
||||
return *m.Name
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
func (m *LabelPair) GetValue() string {
|
||||
if m != nil && m.Value != nil {
|
||||
return *m.Value
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
type Gauge struct {
|
||||
Value *float64 `protobuf:"fixed64,1,opt,name=value" json:"value,omitempty"`
|
||||
XXX_NoUnkeyedLiteral struct{} `json:"-"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
XXX_sizecache int32 `json:"-"`
|
||||
}
|
||||
|
||||
func (m *Gauge) Reset() { *m = Gauge{} }
|
||||
func (m *Gauge) String() string { return proto.CompactTextString(m) }
|
||||
func (*Gauge) ProtoMessage() {}
|
||||
func (*Gauge) Descriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{1}
|
||||
}
|
||||
func (m *Gauge) XXX_Unmarshal(b []byte) error {
|
||||
return xxx_messageInfo_Gauge.Unmarshal(m, b)
|
||||
}
|
||||
func (m *Gauge) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
|
||||
return xxx_messageInfo_Gauge.Marshal(b, m, deterministic)
|
||||
}
|
||||
func (dst *Gauge) XXX_Merge(src proto.Message) {
|
||||
xxx_messageInfo_Gauge.Merge(dst, src)
|
||||
}
|
||||
func (m *Gauge) XXX_Size() int {
|
||||
return xxx_messageInfo_Gauge.Size(m)
|
||||
}
|
||||
func (m *Gauge) XXX_DiscardUnknown() {
|
||||
xxx_messageInfo_Gauge.DiscardUnknown(m)
|
||||
}
|
||||
|
||||
var xxx_messageInfo_Gauge proto.InternalMessageInfo
|
||||
|
||||
func (m *Gauge) GetValue() float64 {
|
||||
if m != nil && m.Value != nil {
|
||||
return *m.Value
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
type Counter struct {
|
||||
Value *float64 `protobuf:"fixed64,1,opt,name=value" json:"value,omitempty"`
|
||||
XXX_NoUnkeyedLiteral struct{} `json:"-"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
XXX_sizecache int32 `json:"-"`
|
||||
}
|
||||
|
||||
func (m *Counter) Reset() { *m = Counter{} }
|
||||
func (m *Counter) String() string { return proto.CompactTextString(m) }
|
||||
func (*Counter) ProtoMessage() {}
|
||||
func (*Counter) Descriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{2}
|
||||
}
|
||||
func (m *Counter) XXX_Unmarshal(b []byte) error {
|
||||
return xxx_messageInfo_Counter.Unmarshal(m, b)
|
||||
}
|
||||
func (m *Counter) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
|
||||
return xxx_messageInfo_Counter.Marshal(b, m, deterministic)
|
||||
}
|
||||
func (dst *Counter) XXX_Merge(src proto.Message) {
|
||||
xxx_messageInfo_Counter.Merge(dst, src)
|
||||
}
|
||||
func (m *Counter) XXX_Size() int {
|
||||
return xxx_messageInfo_Counter.Size(m)
|
||||
}
|
||||
func (m *Counter) XXX_DiscardUnknown() {
|
||||
xxx_messageInfo_Counter.DiscardUnknown(m)
|
||||
}
|
||||
|
||||
var xxx_messageInfo_Counter proto.InternalMessageInfo
|
||||
|
||||
func (m *Counter) GetValue() float64 {
|
||||
if m != nil && m.Value != nil {
|
||||
return *m.Value
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
type Quantile struct {
|
||||
Quantile *float64 `protobuf:"fixed64,1,opt,name=quantile" json:"quantile,omitempty"`
|
||||
Value *float64 `protobuf:"fixed64,2,opt,name=value" json:"value,omitempty"`
|
||||
XXX_NoUnkeyedLiteral struct{} `json:"-"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
XXX_sizecache int32 `json:"-"`
|
||||
}
|
||||
|
||||
func (m *Quantile) Reset() { *m = Quantile{} }
|
||||
func (m *Quantile) String() string { return proto.CompactTextString(m) }
|
||||
func (*Quantile) ProtoMessage() {}
|
||||
func (*Quantile) Descriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{3}
|
||||
}
|
||||
func (m *Quantile) XXX_Unmarshal(b []byte) error {
|
||||
return xxx_messageInfo_Quantile.Unmarshal(m, b)
|
||||
}
|
||||
func (m *Quantile) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
|
||||
return xxx_messageInfo_Quantile.Marshal(b, m, deterministic)
|
||||
}
|
||||
func (dst *Quantile) XXX_Merge(src proto.Message) {
|
||||
xxx_messageInfo_Quantile.Merge(dst, src)
|
||||
}
|
||||
func (m *Quantile) XXX_Size() int {
|
||||
return xxx_messageInfo_Quantile.Size(m)
|
||||
}
|
||||
func (m *Quantile) XXX_DiscardUnknown() {
|
||||
xxx_messageInfo_Quantile.DiscardUnknown(m)
|
||||
}
|
||||
|
||||
var xxx_messageInfo_Quantile proto.InternalMessageInfo
|
||||
|
||||
func (m *Quantile) GetQuantile() float64 {
|
||||
if m != nil && m.Quantile != nil {
|
||||
return *m.Quantile
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
func (m *Quantile) GetValue() float64 {
|
||||
if m != nil && m.Value != nil {
|
||||
return *m.Value
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
type Summary struct {
|
||||
SampleCount *uint64 `protobuf:"varint,1,opt,name=sample_count,json=sampleCount" json:"sample_count,omitempty"`
|
||||
SampleSum *float64 `protobuf:"fixed64,2,opt,name=sample_sum,json=sampleSum" json:"sample_sum,omitempty"`
|
||||
Quantile []*Quantile `protobuf:"bytes,3,rep,name=quantile" json:"quantile,omitempty"`
|
||||
XXX_NoUnkeyedLiteral struct{} `json:"-"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
XXX_sizecache int32 `json:"-"`
|
||||
}
|
||||
|
||||
func (m *Summary) Reset() { *m = Summary{} }
|
||||
func (m *Summary) String() string { return proto.CompactTextString(m) }
|
||||
func (*Summary) ProtoMessage() {}
|
||||
func (*Summary) Descriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{4}
|
||||
}
|
||||
func (m *Summary) XXX_Unmarshal(b []byte) error {
|
||||
return xxx_messageInfo_Summary.Unmarshal(m, b)
|
||||
}
|
||||
func (m *Summary) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
|
||||
return xxx_messageInfo_Summary.Marshal(b, m, deterministic)
|
||||
}
|
||||
func (dst *Summary) XXX_Merge(src proto.Message) {
|
||||
xxx_messageInfo_Summary.Merge(dst, src)
|
||||
}
|
||||
func (m *Summary) XXX_Size() int {
|
||||
return xxx_messageInfo_Summary.Size(m)
|
||||
}
|
||||
func (m *Summary) XXX_DiscardUnknown() {
|
||||
xxx_messageInfo_Summary.DiscardUnknown(m)
|
||||
}
|
||||
|
||||
var xxx_messageInfo_Summary proto.InternalMessageInfo
|
||||
|
||||
func (m *Summary) GetSampleCount() uint64 {
|
||||
if m != nil && m.SampleCount != nil {
|
||||
return *m.SampleCount
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
func (m *Summary) GetSampleSum() float64 {
|
||||
if m != nil && m.SampleSum != nil {
|
||||
return *m.SampleSum
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
func (m *Summary) GetQuantile() []*Quantile {
|
||||
if m != nil {
|
||||
return m.Quantile
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
type Untyped struct {
|
||||
Value *float64 `protobuf:"fixed64,1,opt,name=value" json:"value,omitempty"`
|
||||
XXX_NoUnkeyedLiteral struct{} `json:"-"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
XXX_sizecache int32 `json:"-"`
|
||||
}
|
||||
|
||||
func (m *Untyped) Reset() { *m = Untyped{} }
|
||||
func (m *Untyped) String() string { return proto.CompactTextString(m) }
|
||||
func (*Untyped) ProtoMessage() {}
|
||||
func (*Untyped) Descriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{5}
|
||||
}
|
||||
func (m *Untyped) XXX_Unmarshal(b []byte) error {
|
||||
return xxx_messageInfo_Untyped.Unmarshal(m, b)
|
||||
}
|
||||
func (m *Untyped) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
|
||||
return xxx_messageInfo_Untyped.Marshal(b, m, deterministic)
|
||||
}
|
||||
func (dst *Untyped) XXX_Merge(src proto.Message) {
|
||||
xxx_messageInfo_Untyped.Merge(dst, src)
|
||||
}
|
||||
func (m *Untyped) XXX_Size() int {
|
||||
return xxx_messageInfo_Untyped.Size(m)
|
||||
}
|
||||
func (m *Untyped) XXX_DiscardUnknown() {
|
||||
xxx_messageInfo_Untyped.DiscardUnknown(m)
|
||||
}
|
||||
|
||||
var xxx_messageInfo_Untyped proto.InternalMessageInfo
|
||||
|
||||
func (m *Untyped) GetValue() float64 {
|
||||
if m != nil && m.Value != nil {
|
||||
return *m.Value
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
type Histogram struct {
|
||||
SampleCount *uint64 `protobuf:"varint,1,opt,name=sample_count,json=sampleCount" json:"sample_count,omitempty"`
|
||||
SampleSum *float64 `protobuf:"fixed64,2,opt,name=sample_sum,json=sampleSum" json:"sample_sum,omitempty"`
|
||||
Bucket []*Bucket `protobuf:"bytes,3,rep,name=bucket" json:"bucket,omitempty"`
|
||||
XXX_NoUnkeyedLiteral struct{} `json:"-"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
XXX_sizecache int32 `json:"-"`
|
||||
}
|
||||
|
||||
func (m *Histogram) Reset() { *m = Histogram{} }
|
||||
func (m *Histogram) String() string { return proto.CompactTextString(m) }
|
||||
func (*Histogram) ProtoMessage() {}
|
||||
func (*Histogram) Descriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{6}
|
||||
}
|
||||
func (m *Histogram) XXX_Unmarshal(b []byte) error {
|
||||
return xxx_messageInfo_Histogram.Unmarshal(m, b)
|
||||
}
|
||||
func (m *Histogram) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
|
||||
return xxx_messageInfo_Histogram.Marshal(b, m, deterministic)
|
||||
}
|
||||
func (dst *Histogram) XXX_Merge(src proto.Message) {
|
||||
xxx_messageInfo_Histogram.Merge(dst, src)
|
||||
}
|
||||
func (m *Histogram) XXX_Size() int {
|
||||
return xxx_messageInfo_Histogram.Size(m)
|
||||
}
|
||||
func (m *Histogram) XXX_DiscardUnknown() {
|
||||
xxx_messageInfo_Histogram.DiscardUnknown(m)
|
||||
}
|
||||
|
||||
var xxx_messageInfo_Histogram proto.InternalMessageInfo
|
||||
|
||||
func (m *Histogram) GetSampleCount() uint64 {
|
||||
if m != nil && m.SampleCount != nil {
|
||||
return *m.SampleCount
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
func (m *Histogram) GetSampleSum() float64 {
|
||||
if m != nil && m.SampleSum != nil {
|
||||
return *m.SampleSum
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
func (m *Histogram) GetBucket() []*Bucket {
|
||||
if m != nil {
|
||||
return m.Bucket
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
type Bucket struct {
|
||||
CumulativeCount *uint64 `protobuf:"varint,1,opt,name=cumulative_count,json=cumulativeCount" json:"cumulative_count,omitempty"`
|
||||
UpperBound *float64 `protobuf:"fixed64,2,opt,name=upper_bound,json=upperBound" json:"upper_bound,omitempty"`
|
||||
XXX_NoUnkeyedLiteral struct{} `json:"-"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
XXX_sizecache int32 `json:"-"`
|
||||
}
|
||||
|
||||
func (m *Bucket) Reset() { *m = Bucket{} }
|
||||
func (m *Bucket) String() string { return proto.CompactTextString(m) }
|
||||
func (*Bucket) ProtoMessage() {}
|
||||
func (*Bucket) Descriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{7}
|
||||
}
|
||||
func (m *Bucket) XXX_Unmarshal(b []byte) error {
|
||||
return xxx_messageInfo_Bucket.Unmarshal(m, b)
|
||||
}
|
||||
func (m *Bucket) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
|
||||
return xxx_messageInfo_Bucket.Marshal(b, m, deterministic)
|
||||
}
|
||||
func (dst *Bucket) XXX_Merge(src proto.Message) {
|
||||
xxx_messageInfo_Bucket.Merge(dst, src)
|
||||
}
|
||||
func (m *Bucket) XXX_Size() int {
|
||||
return xxx_messageInfo_Bucket.Size(m)
|
||||
}
|
||||
func (m *Bucket) XXX_DiscardUnknown() {
|
||||
xxx_messageInfo_Bucket.DiscardUnknown(m)
|
||||
}
|
||||
|
||||
var xxx_messageInfo_Bucket proto.InternalMessageInfo
|
||||
|
||||
func (m *Bucket) GetCumulativeCount() uint64 {
|
||||
if m != nil && m.CumulativeCount != nil {
|
||||
return *m.CumulativeCount
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
func (m *Bucket) GetUpperBound() float64 {
|
||||
if m != nil && m.UpperBound != nil {
|
||||
return *m.UpperBound
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
type Metric struct {
|
||||
Label []*LabelPair `protobuf:"bytes,1,rep,name=label" json:"label,omitempty"`
|
||||
Gauge *Gauge `protobuf:"bytes,2,opt,name=gauge" json:"gauge,omitempty"`
|
||||
Counter *Counter `protobuf:"bytes,3,opt,name=counter" json:"counter,omitempty"`
|
||||
Summary *Summary `protobuf:"bytes,4,opt,name=summary" json:"summary,omitempty"`
|
||||
Untyped *Untyped `protobuf:"bytes,5,opt,name=untyped" json:"untyped,omitempty"`
|
||||
Histogram *Histogram `protobuf:"bytes,7,opt,name=histogram" json:"histogram,omitempty"`
|
||||
TimestampMs *int64 `protobuf:"varint,6,opt,name=timestamp_ms,json=timestampMs" json:"timestamp_ms,omitempty"`
|
||||
XXX_NoUnkeyedLiteral struct{} `json:"-"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
XXX_sizecache int32 `json:"-"`
|
||||
}
|
||||
|
||||
func (m *Metric) Reset() { *m = Metric{} }
|
||||
func (m *Metric) String() string { return proto.CompactTextString(m) }
|
||||
func (*Metric) ProtoMessage() {}
|
||||
func (*Metric) Descriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{8}
|
||||
}
|
||||
func (m *Metric) XXX_Unmarshal(b []byte) error {
|
||||
return xxx_messageInfo_Metric.Unmarshal(m, b)
|
||||
}
|
||||
func (m *Metric) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
|
||||
return xxx_messageInfo_Metric.Marshal(b, m, deterministic)
|
||||
}
|
||||
func (dst *Metric) XXX_Merge(src proto.Message) {
|
||||
xxx_messageInfo_Metric.Merge(dst, src)
|
||||
}
|
||||
func (m *Metric) XXX_Size() int {
|
||||
return xxx_messageInfo_Metric.Size(m)
|
||||
}
|
||||
func (m *Metric) XXX_DiscardUnknown() {
|
||||
xxx_messageInfo_Metric.DiscardUnknown(m)
|
||||
}
|
||||
|
||||
var xxx_messageInfo_Metric proto.InternalMessageInfo
|
||||
|
||||
func (m *Metric) GetLabel() []*LabelPair {
|
||||
if m != nil {
|
||||
return m.Label
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (m *Metric) GetGauge() *Gauge {
|
||||
if m != nil {
|
||||
return m.Gauge
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (m *Metric) GetCounter() *Counter {
|
||||
if m != nil {
|
||||
return m.Counter
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (m *Metric) GetSummary() *Summary {
|
||||
if m != nil {
|
||||
return m.Summary
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (m *Metric) GetUntyped() *Untyped {
|
||||
if m != nil {
|
||||
return m.Untyped
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (m *Metric) GetHistogram() *Histogram {
|
||||
if m != nil {
|
||||
return m.Histogram
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (m *Metric) GetTimestampMs() int64 {
|
||||
if m != nil && m.TimestampMs != nil {
|
||||
return *m.TimestampMs
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
type MetricFamily struct {
|
||||
Name *string `protobuf:"bytes,1,opt,name=name" json:"name,omitempty"`
|
||||
Help *string `protobuf:"bytes,2,opt,name=help" json:"help,omitempty"`
|
||||
Type *MetricType `protobuf:"varint,3,opt,name=type,enum=io.prometheus.client.MetricType" json:"type,omitempty"`
|
||||
Metric []*Metric `protobuf:"bytes,4,rep,name=metric" json:"metric,omitempty"`
|
||||
XXX_NoUnkeyedLiteral struct{} `json:"-"`
|
||||
XXX_unrecognized []byte `json:"-"`
|
||||
XXX_sizecache int32 `json:"-"`
|
||||
}
|
||||
|
||||
func (m *MetricFamily) Reset() { *m = MetricFamily{} }
|
||||
func (m *MetricFamily) String() string { return proto.CompactTextString(m) }
|
||||
func (*MetricFamily) ProtoMessage() {}
|
||||
func (*MetricFamily) Descriptor() ([]byte, []int) {
|
||||
return fileDescriptor_metrics_c97c9a2b9560cb8f, []int{9}
|
||||
}
|
||||
func (m *MetricFamily) XXX_Unmarshal(b []byte) error {
|
||||
return xxx_messageInfo_MetricFamily.Unmarshal(m, b)
|
||||
}
|
||||
func (m *MetricFamily) XXX_Marshal(b []byte, deterministic bool) ([]byte, error) {
|
||||
return xxx_messageInfo_MetricFamily.Marshal(b, m, deterministic)
|
||||
}
|
||||
func (dst *MetricFamily) XXX_Merge(src proto.Message) {
|
||||
xxx_messageInfo_MetricFamily.Merge(dst, src)
|
||||
}
|
||||
func (m *MetricFamily) XXX_Size() int {
|
||||
return xxx_messageInfo_MetricFamily.Size(m)
|
||||
}
|
||||
func (m *MetricFamily) XXX_DiscardUnknown() {
|
||||
xxx_messageInfo_MetricFamily.DiscardUnknown(m)
|
||||
}
|
||||
|
||||
var xxx_messageInfo_MetricFamily proto.InternalMessageInfo
|
||||
|
||||
func (m *MetricFamily) GetName() string {
|
||||
if m != nil && m.Name != nil {
|
||||
return *m.Name
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
func (m *MetricFamily) GetHelp() string {
|
||||
if m != nil && m.Help != nil {
|
||||
return *m.Help
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
func (m *MetricFamily) GetType() MetricType {
|
||||
if m != nil && m.Type != nil {
|
||||
return *m.Type
|
||||
}
|
||||
return MetricType_COUNTER
|
||||
}
|
||||
|
||||
func (m *MetricFamily) GetMetric() []*Metric {
|
||||
if m != nil {
|
||||
return m.Metric
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func init() {
|
||||
proto.RegisterType((*LabelPair)(nil), "io.prometheus.client.LabelPair")
|
||||
proto.RegisterType((*Gauge)(nil), "io.prometheus.client.Gauge")
|
||||
proto.RegisterType((*Counter)(nil), "io.prometheus.client.Counter")
|
||||
proto.RegisterType((*Quantile)(nil), "io.prometheus.client.Quantile")
|
||||
proto.RegisterType((*Summary)(nil), "io.prometheus.client.Summary")
|
||||
proto.RegisterType((*Untyped)(nil), "io.prometheus.client.Untyped")
|
||||
proto.RegisterType((*Histogram)(nil), "io.prometheus.client.Histogram")
|
||||
proto.RegisterType((*Bucket)(nil), "io.prometheus.client.Bucket")
|
||||
proto.RegisterType((*Metric)(nil), "io.prometheus.client.Metric")
|
||||
proto.RegisterType((*MetricFamily)(nil), "io.prometheus.client.MetricFamily")
|
||||
proto.RegisterEnum("io.prometheus.client.MetricType", MetricType_name, MetricType_value)
|
||||
}
|
||||
|
||||
func init() { proto.RegisterFile("metrics.proto", fileDescriptor_metrics_c97c9a2b9560cb8f) }
|
||||
|
||||
var fileDescriptor_metrics_c97c9a2b9560cb8f = []byte{
|
||||
// 591 bytes of a gzipped FileDescriptorProto
|
||||
0x1f, 0x8b, 0x08, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0xff, 0xac, 0x54, 0x4f, 0x4f, 0xdb, 0x4e,
|
||||
0x14, 0xfc, 0x99, 0xd8, 0x09, 0x7e, 0x86, 0x5f, 0xad, 0x15, 0x07, 0xab, 0x2d, 0x25, 0xcd, 0x89,
|
||||
0xf6, 0x10, 0x54, 0x04, 0xaa, 0x44, 0xdb, 0x03, 0x50, 0x1a, 0x2a, 0xd5, 0x40, 0x37, 0xc9, 0x81,
|
||||
0x5e, 0xac, 0x8d, 0x59, 0x25, 0x56, 0xbd, 0xb6, 0x6b, 0xef, 0x22, 0xe5, 0xdc, 0x43, 0xbf, 0x47,
|
||||
0xbf, 0x68, 0xab, 0xfd, 0xe3, 0x18, 0x24, 0xc3, 0xa9, 0xb7, 0xb7, 0xf3, 0x66, 0xde, 0x8e, 0x77,
|
||||
0xc7, 0x0b, 0x9b, 0x8c, 0xf2, 0x32, 0x89, 0xab, 0x61, 0x51, 0xe6, 0x3c, 0x47, 0x5b, 0x49, 0x2e,
|
||||
0x2b, 0x46, 0xf9, 0x82, 0x8a, 0x6a, 0x18, 0xa7, 0x09, 0xcd, 0xf8, 0xe0, 0x10, 0xdc, 0x2f, 0x64,
|
||||
0x46, 0xd3, 0x2b, 0x92, 0x94, 0x08, 0x81, 0x9d, 0x11, 0x46, 0x03, 0xab, 0x6f, 0xed, 0xba, 0x58,
|
||||
0xd5, 0x68, 0x0b, 0x9c, 0x5b, 0x92, 0x0a, 0x1a, 0xac, 0x29, 0x50, 0x2f, 0x06, 0xdb, 0xe0, 0x8c,
|
||||
0x88, 0x98, 0xdf, 0x69, 0x4b, 0x8d, 0x55, 0xb7, 0x77, 0xa0, 0x77, 0x9a, 0x8b, 0x8c, 0xd3, 0xf2,
|
||||
0x01, 0xc2, 0x7b, 0x58, 0xff, 0x2a, 0x48, 0xc6, 0x93, 0x94, 0xa2, 0xa7, 0xb0, 0xfe, 0xc3, 0xd4,
|
||||
0x86, 0xb4, 0x5a, 0xdf, 0xdf, 0x7d, 0xa5, 0xfe, 0x65, 0x41, 0x6f, 0x2c, 0x18, 0x23, 0xe5, 0x12,
|
||||
0xbd, 0x84, 0x8d, 0x8a, 0xb0, 0x22, 0xa5, 0x51, 0x2c, 0x77, 0x54, 0x13, 0x6c, 0xec, 0x69, 0x4c,
|
||||
0x99, 0x40, 0xdb, 0x00, 0x86, 0x52, 0x09, 0x66, 0x26, 0xb9, 0x1a, 0x19, 0x0b, 0x86, 0x8e, 0xee,
|
||||
0xec, 0xdf, 0xe9, 0x77, 0x76, 0xbd, 0xfd, 0x17, 0xc3, 0xb6, 0xb3, 0x1a, 0xd6, 0x8e, 0x1b, 0x7f,
|
||||
0xf2, 0x43, 0xa7, 0x19, 0x5f, 0x16, 0xf4, 0xe6, 0x81, 0x0f, 0xfd, 0x69, 0x81, 0x7b, 0x9e, 0x54,
|
||||
0x3c, 0x9f, 0x97, 0x84, 0xfd, 0x03, 0xb3, 0x07, 0xd0, 0x9d, 0x89, 0xf8, 0x3b, 0xe5, 0xc6, 0xea,
|
||||
0xf3, 0x76, 0xab, 0x27, 0x8a, 0x83, 0x0d, 0x77, 0x30, 0x81, 0xae, 0x46, 0xd0, 0x2b, 0xf0, 0x63,
|
||||
0xc1, 0x44, 0x4a, 0x78, 0x72, 0x7b, 0xdf, 0xc5, 0x93, 0x06, 0xd7, 0x4e, 0x76, 0xc0, 0x13, 0x45,
|
||||
0x41, 0xcb, 0x68, 0x96, 0x8b, 0xec, 0xc6, 0x58, 0x01, 0x05, 0x9d, 0x48, 0x64, 0xf0, 0x67, 0x0d,
|
||||
0xba, 0xa1, 0xca, 0x18, 0x3a, 0x04, 0x27, 0x95, 0x31, 0x0a, 0x2c, 0xe5, 0x6a, 0xa7, 0xdd, 0xd5,
|
||||
0x2a, 0x69, 0x58, 0xb3, 0xd1, 0x1b, 0x70, 0xe6, 0x32, 0x46, 0x6a, 0xb8, 0xb7, 0xff, 0xac, 0x5d,
|
||||
0xa6, 0x92, 0x86, 0x35, 0x13, 0xbd, 0x85, 0x5e, 0xac, 0xa3, 0x15, 0x74, 0x94, 0x68, 0xbb, 0x5d,
|
||||
0x64, 0xf2, 0x87, 0x6b, 0xb6, 0x14, 0x56, 0x3a, 0x33, 0x81, 0xfd, 0x98, 0xd0, 0x04, 0x0b, 0xd7,
|
||||
0x6c, 0x29, 0x14, 0xfa, 0x8e, 0x03, 0xe7, 0x31, 0xa1, 0x09, 0x02, 0xae, 0xd9, 0xe8, 0x03, 0xb8,
|
||||
0x8b, 0xfa, 0xea, 0x83, 0x9e, 0x92, 0x3e, 0x70, 0x30, 0xab, 0x84, 0xe0, 0x46, 0x21, 0xc3, 0xc2,
|
||||
0x13, 0x46, 0x2b, 0x4e, 0x58, 0x11, 0xb1, 0x2a, 0xe8, 0xf6, 0xad, 0xdd, 0x0e, 0xf6, 0x56, 0x58,
|
||||
0x58, 0x0d, 0x7e, 0x5b, 0xb0, 0xa1, 0x6f, 0xe0, 0x13, 0x61, 0x49, 0xba, 0x6c, 0xfd, 0x83, 0x11,
|
||||
0xd8, 0x0b, 0x9a, 0x16, 0xe6, 0x07, 0x56, 0x35, 0x3a, 0x00, 0x5b, 0x7a, 0x54, 0x47, 0xf8, 0xff,
|
||||
0x7e, 0xbf, 0xdd, 0x95, 0x9e, 0x3c, 0x59, 0x16, 0x14, 0x2b, 0xb6, 0x0c, 0x9f, 0x7e, 0x53, 0x02,
|
||||
0xfb, 0xb1, 0xf0, 0x69, 0x1d, 0x36, 0xdc, 0xd7, 0x21, 0x40, 0x33, 0x09, 0x79, 0xd0, 0x3b, 0xbd,
|
||||
0x9c, 0x5e, 0x4c, 0xce, 0xb0, 0xff, 0x1f, 0x72, 0xc1, 0x19, 0x1d, 0x4f, 0x47, 0x67, 0xbe, 0x25,
|
||||
0xf1, 0xf1, 0x34, 0x0c, 0x8f, 0xf1, 0xb5, 0xbf, 0x26, 0x17, 0xd3, 0x8b, 0xc9, 0xf5, 0xd5, 0xd9,
|
||||
0x47, 0xbf, 0x83, 0x36, 0xc1, 0x3d, 0xff, 0x3c, 0x9e, 0x5c, 0x8e, 0xf0, 0x71, 0xe8, 0xdb, 0x27,
|
||||
0x18, 0x5a, 0x5f, 0xb2, 0x6f, 0x47, 0xf3, 0x84, 0x2f, 0xc4, 0x6c, 0x18, 0xe7, 0x6c, 0xaf, 0xe9,
|
||||
0xee, 0xe9, 0x6e, 0xc4, 0xf2, 0x1b, 0x9a, 0xee, 0xcd, 0xf3, 0x77, 0x49, 0x1e, 0x35, 0xdd, 0x48,
|
||||
0x77, 0xff, 0x06, 0x00, 0x00, 0xff, 0xff, 0x45, 0x21, 0x7f, 0x64, 0x2b, 0x05, 0x00, 0x00,
|
||||
}
|
||||
201
watchdog/vendor/github.com/prometheus/client_model/ruby/LICENSE
generated
vendored
201
watchdog/vendor/github.com/prometheus/client_model/ruby/LICENSE
generated
vendored
@ -1,201 +0,0 @@
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright [yyyy] [name of copyright owner]
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
201
watchdog/vendor/github.com/prometheus/common/LICENSE
generated
vendored
201
watchdog/vendor/github.com/prometheus/common/LICENSE
generated
vendored
@ -1,201 +0,0 @@
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright [yyyy] [name of copyright owner]
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
5
watchdog/vendor/github.com/prometheus/common/NOTICE
generated
vendored
5
watchdog/vendor/github.com/prometheus/common/NOTICE
generated
vendored
@ -1,5 +0,0 @@
|
||||
Common libraries shared by Prometheus Go components.
|
||||
Copyright 2015 The Prometheus Authors
|
||||
|
||||
This product includes software developed at
|
||||
SoundCloud Ltd. (http://soundcloud.com/).
|
||||
429
watchdog/vendor/github.com/prometheus/common/expfmt/decode.go
generated
vendored
429
watchdog/vendor/github.com/prometheus/common/expfmt/decode.go
generated
vendored
@ -1,429 +0,0 @@
|
||||
// Copyright 2015 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package expfmt
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"io"
|
||||
"math"
|
||||
"mime"
|
||||
"net/http"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
|
||||
"github.com/matttproud/golang_protobuf_extensions/pbutil"
|
||||
"github.com/prometheus/common/model"
|
||||
)
|
||||
|
||||
// Decoder types decode an input stream into metric families.
|
||||
type Decoder interface {
|
||||
Decode(*dto.MetricFamily) error
|
||||
}
|
||||
|
||||
// DecodeOptions contains options used by the Decoder and in sample extraction.
|
||||
type DecodeOptions struct {
|
||||
// Timestamp is added to each value from the stream that has no explicit timestamp set.
|
||||
Timestamp model.Time
|
||||
}
|
||||
|
||||
// ResponseFormat extracts the correct format from a HTTP response header.
|
||||
// If no matching format can be found FormatUnknown is returned.
|
||||
func ResponseFormat(h http.Header) Format {
|
||||
ct := h.Get(hdrContentType)
|
||||
|
||||
mediatype, params, err := mime.ParseMediaType(ct)
|
||||
if err != nil {
|
||||
return FmtUnknown
|
||||
}
|
||||
|
||||
const textType = "text/plain"
|
||||
|
||||
switch mediatype {
|
||||
case ProtoType:
|
||||
if p, ok := params["proto"]; ok && p != ProtoProtocol {
|
||||
return FmtUnknown
|
||||
}
|
||||
if e, ok := params["encoding"]; ok && e != "delimited" {
|
||||
return FmtUnknown
|
||||
}
|
||||
return FmtProtoDelim
|
||||
|
||||
case textType:
|
||||
if v, ok := params["version"]; ok && v != TextVersion {
|
||||
return FmtUnknown
|
||||
}
|
||||
return FmtText
|
||||
}
|
||||
|
||||
return FmtUnknown
|
||||
}
|
||||
|
||||
// NewDecoder returns a new decoder based on the given input format.
|
||||
// If the input format does not imply otherwise, a text format decoder is returned.
|
||||
func NewDecoder(r io.Reader, format Format) Decoder {
|
||||
switch format {
|
||||
case FmtProtoDelim:
|
||||
return &protoDecoder{r: r}
|
||||
}
|
||||
return &textDecoder{r: r}
|
||||
}
|
||||
|
||||
// protoDecoder implements the Decoder interface for protocol buffers.
|
||||
type protoDecoder struct {
|
||||
r io.Reader
|
||||
}
|
||||
|
||||
// Decode implements the Decoder interface.
|
||||
func (d *protoDecoder) Decode(v *dto.MetricFamily) error {
|
||||
_, err := pbutil.ReadDelimited(d.r, v)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if !model.IsValidMetricName(model.LabelValue(v.GetName())) {
|
||||
return fmt.Errorf("invalid metric name %q", v.GetName())
|
||||
}
|
||||
for _, m := range v.GetMetric() {
|
||||
if m == nil {
|
||||
continue
|
||||
}
|
||||
for _, l := range m.GetLabel() {
|
||||
if l == nil {
|
||||
continue
|
||||
}
|
||||
if !model.LabelValue(l.GetValue()).IsValid() {
|
||||
return fmt.Errorf("invalid label value %q", l.GetValue())
|
||||
}
|
||||
if !model.LabelName(l.GetName()).IsValid() {
|
||||
return fmt.Errorf("invalid label name %q", l.GetName())
|
||||
}
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// textDecoder implements the Decoder interface for the text protocol.
|
||||
type textDecoder struct {
|
||||
r io.Reader
|
||||
p TextParser
|
||||
fams []*dto.MetricFamily
|
||||
}
|
||||
|
||||
// Decode implements the Decoder interface.
|
||||
func (d *textDecoder) Decode(v *dto.MetricFamily) error {
|
||||
// TODO(fabxc): Wrap this as a line reader to make streaming safer.
|
||||
if len(d.fams) == 0 {
|
||||
// No cached metric families, read everything and parse metrics.
|
||||
fams, err := d.p.TextToMetricFamilies(d.r)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if len(fams) == 0 {
|
||||
return io.EOF
|
||||
}
|
||||
d.fams = make([]*dto.MetricFamily, 0, len(fams))
|
||||
for _, f := range fams {
|
||||
d.fams = append(d.fams, f)
|
||||
}
|
||||
}
|
||||
|
||||
*v = *d.fams[0]
|
||||
d.fams = d.fams[1:]
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
// SampleDecoder wraps a Decoder to extract samples from the metric families
|
||||
// decoded by the wrapped Decoder.
|
||||
type SampleDecoder struct {
|
||||
Dec Decoder
|
||||
Opts *DecodeOptions
|
||||
|
||||
f dto.MetricFamily
|
||||
}
|
||||
|
||||
// Decode calls the Decode method of the wrapped Decoder and then extracts the
|
||||
// samples from the decoded MetricFamily into the provided model.Vector.
|
||||
func (sd *SampleDecoder) Decode(s *model.Vector) error {
|
||||
err := sd.Dec.Decode(&sd.f)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
*s, err = extractSamples(&sd.f, sd.Opts)
|
||||
return err
|
||||
}
|
||||
|
||||
// ExtractSamples builds a slice of samples from the provided metric
|
||||
// families. If an error occurrs during sample extraction, it continues to
|
||||
// extract from the remaining metric families. The returned error is the last
|
||||
// error that has occurred.
|
||||
func ExtractSamples(o *DecodeOptions, fams ...*dto.MetricFamily) (model.Vector, error) {
|
||||
var (
|
||||
all model.Vector
|
||||
lastErr error
|
||||
)
|
||||
for _, f := range fams {
|
||||
some, err := extractSamples(f, o)
|
||||
if err != nil {
|
||||
lastErr = err
|
||||
continue
|
||||
}
|
||||
all = append(all, some...)
|
||||
}
|
||||
return all, lastErr
|
||||
}
|
||||
|
||||
func extractSamples(f *dto.MetricFamily, o *DecodeOptions) (model.Vector, error) {
|
||||
switch f.GetType() {
|
||||
case dto.MetricType_COUNTER:
|
||||
return extractCounter(o, f), nil
|
||||
case dto.MetricType_GAUGE:
|
||||
return extractGauge(o, f), nil
|
||||
case dto.MetricType_SUMMARY:
|
||||
return extractSummary(o, f), nil
|
||||
case dto.MetricType_UNTYPED:
|
||||
return extractUntyped(o, f), nil
|
||||
case dto.MetricType_HISTOGRAM:
|
||||
return extractHistogram(o, f), nil
|
||||
}
|
||||
return nil, fmt.Errorf("expfmt.extractSamples: unknown metric family type %v", f.GetType())
|
||||
}
|
||||
|
||||
func extractCounter(o *DecodeOptions, f *dto.MetricFamily) model.Vector {
|
||||
samples := make(model.Vector, 0, len(f.Metric))
|
||||
|
||||
for _, m := range f.Metric {
|
||||
if m.Counter == nil {
|
||||
continue
|
||||
}
|
||||
|
||||
lset := make(model.LabelSet, len(m.Label)+1)
|
||||
for _, p := range m.Label {
|
||||
lset[model.LabelName(p.GetName())] = model.LabelValue(p.GetValue())
|
||||
}
|
||||
lset[model.MetricNameLabel] = model.LabelValue(f.GetName())
|
||||
|
||||
smpl := &model.Sample{
|
||||
Metric: model.Metric(lset),
|
||||
Value: model.SampleValue(m.Counter.GetValue()),
|
||||
}
|
||||
|
||||
if m.TimestampMs != nil {
|
||||
smpl.Timestamp = model.TimeFromUnixNano(*m.TimestampMs * 1000000)
|
||||
} else {
|
||||
smpl.Timestamp = o.Timestamp
|
||||
}
|
||||
|
||||
samples = append(samples, smpl)
|
||||
}
|
||||
|
||||
return samples
|
||||
}
|
||||
|
||||
func extractGauge(o *DecodeOptions, f *dto.MetricFamily) model.Vector {
|
||||
samples := make(model.Vector, 0, len(f.Metric))
|
||||
|
||||
for _, m := range f.Metric {
|
||||
if m.Gauge == nil {
|
||||
continue
|
||||
}
|
||||
|
||||
lset := make(model.LabelSet, len(m.Label)+1)
|
||||
for _, p := range m.Label {
|
||||
lset[model.LabelName(p.GetName())] = model.LabelValue(p.GetValue())
|
||||
}
|
||||
lset[model.MetricNameLabel] = model.LabelValue(f.GetName())
|
||||
|
||||
smpl := &model.Sample{
|
||||
Metric: model.Metric(lset),
|
||||
Value: model.SampleValue(m.Gauge.GetValue()),
|
||||
}
|
||||
|
||||
if m.TimestampMs != nil {
|
||||
smpl.Timestamp = model.TimeFromUnixNano(*m.TimestampMs * 1000000)
|
||||
} else {
|
||||
smpl.Timestamp = o.Timestamp
|
||||
}
|
||||
|
||||
samples = append(samples, smpl)
|
||||
}
|
||||
|
||||
return samples
|
||||
}
|
||||
|
||||
func extractUntyped(o *DecodeOptions, f *dto.MetricFamily) model.Vector {
|
||||
samples := make(model.Vector, 0, len(f.Metric))
|
||||
|
||||
for _, m := range f.Metric {
|
||||
if m.Untyped == nil {
|
||||
continue
|
||||
}
|
||||
|
||||
lset := make(model.LabelSet, len(m.Label)+1)
|
||||
for _, p := range m.Label {
|
||||
lset[model.LabelName(p.GetName())] = model.LabelValue(p.GetValue())
|
||||
}
|
||||
lset[model.MetricNameLabel] = model.LabelValue(f.GetName())
|
||||
|
||||
smpl := &model.Sample{
|
||||
Metric: model.Metric(lset),
|
||||
Value: model.SampleValue(m.Untyped.GetValue()),
|
||||
}
|
||||
|
||||
if m.TimestampMs != nil {
|
||||
smpl.Timestamp = model.TimeFromUnixNano(*m.TimestampMs * 1000000)
|
||||
} else {
|
||||
smpl.Timestamp = o.Timestamp
|
||||
}
|
||||
|
||||
samples = append(samples, smpl)
|
||||
}
|
||||
|
||||
return samples
|
||||
}
|
||||
|
||||
func extractSummary(o *DecodeOptions, f *dto.MetricFamily) model.Vector {
|
||||
samples := make(model.Vector, 0, len(f.Metric))
|
||||
|
||||
for _, m := range f.Metric {
|
||||
if m.Summary == nil {
|
||||
continue
|
||||
}
|
||||
|
||||
timestamp := o.Timestamp
|
||||
if m.TimestampMs != nil {
|
||||
timestamp = model.TimeFromUnixNano(*m.TimestampMs * 1000000)
|
||||
}
|
||||
|
||||
for _, q := range m.Summary.Quantile {
|
||||
lset := make(model.LabelSet, len(m.Label)+2)
|
||||
for _, p := range m.Label {
|
||||
lset[model.LabelName(p.GetName())] = model.LabelValue(p.GetValue())
|
||||
}
|
||||
// BUG(matt): Update other names to "quantile".
|
||||
lset[model.LabelName(model.QuantileLabel)] = model.LabelValue(fmt.Sprint(q.GetQuantile()))
|
||||
lset[model.MetricNameLabel] = model.LabelValue(f.GetName())
|
||||
|
||||
samples = append(samples, &model.Sample{
|
||||
Metric: model.Metric(lset),
|
||||
Value: model.SampleValue(q.GetValue()),
|
||||
Timestamp: timestamp,
|
||||
})
|
||||
}
|
||||
|
||||
lset := make(model.LabelSet, len(m.Label)+1)
|
||||
for _, p := range m.Label {
|
||||
lset[model.LabelName(p.GetName())] = model.LabelValue(p.GetValue())
|
||||
}
|
||||
lset[model.MetricNameLabel] = model.LabelValue(f.GetName() + "_sum")
|
||||
|
||||
samples = append(samples, &model.Sample{
|
||||
Metric: model.Metric(lset),
|
||||
Value: model.SampleValue(m.Summary.GetSampleSum()),
|
||||
Timestamp: timestamp,
|
||||
})
|
||||
|
||||
lset = make(model.LabelSet, len(m.Label)+1)
|
||||
for _, p := range m.Label {
|
||||
lset[model.LabelName(p.GetName())] = model.LabelValue(p.GetValue())
|
||||
}
|
||||
lset[model.MetricNameLabel] = model.LabelValue(f.GetName() + "_count")
|
||||
|
||||
samples = append(samples, &model.Sample{
|
||||
Metric: model.Metric(lset),
|
||||
Value: model.SampleValue(m.Summary.GetSampleCount()),
|
||||
Timestamp: timestamp,
|
||||
})
|
||||
}
|
||||
|
||||
return samples
|
||||
}
|
||||
|
||||
func extractHistogram(o *DecodeOptions, f *dto.MetricFamily) model.Vector {
|
||||
samples := make(model.Vector, 0, len(f.Metric))
|
||||
|
||||
for _, m := range f.Metric {
|
||||
if m.Histogram == nil {
|
||||
continue
|
||||
}
|
||||
|
||||
timestamp := o.Timestamp
|
||||
if m.TimestampMs != nil {
|
||||
timestamp = model.TimeFromUnixNano(*m.TimestampMs * 1000000)
|
||||
}
|
||||
|
||||
infSeen := false
|
||||
|
||||
for _, q := range m.Histogram.Bucket {
|
||||
lset := make(model.LabelSet, len(m.Label)+2)
|
||||
for _, p := range m.Label {
|
||||
lset[model.LabelName(p.GetName())] = model.LabelValue(p.GetValue())
|
||||
}
|
||||
lset[model.LabelName(model.BucketLabel)] = model.LabelValue(fmt.Sprint(q.GetUpperBound()))
|
||||
lset[model.MetricNameLabel] = model.LabelValue(f.GetName() + "_bucket")
|
||||
|
||||
if math.IsInf(q.GetUpperBound(), +1) {
|
||||
infSeen = true
|
||||
}
|
||||
|
||||
samples = append(samples, &model.Sample{
|
||||
Metric: model.Metric(lset),
|
||||
Value: model.SampleValue(q.GetCumulativeCount()),
|
||||
Timestamp: timestamp,
|
||||
})
|
||||
}
|
||||
|
||||
lset := make(model.LabelSet, len(m.Label)+1)
|
||||
for _, p := range m.Label {
|
||||
lset[model.LabelName(p.GetName())] = model.LabelValue(p.GetValue())
|
||||
}
|
||||
lset[model.MetricNameLabel] = model.LabelValue(f.GetName() + "_sum")
|
||||
|
||||
samples = append(samples, &model.Sample{
|
||||
Metric: model.Metric(lset),
|
||||
Value: model.SampleValue(m.Histogram.GetSampleSum()),
|
||||
Timestamp: timestamp,
|
||||
})
|
||||
|
||||
lset = make(model.LabelSet, len(m.Label)+1)
|
||||
for _, p := range m.Label {
|
||||
lset[model.LabelName(p.GetName())] = model.LabelValue(p.GetValue())
|
||||
}
|
||||
lset[model.MetricNameLabel] = model.LabelValue(f.GetName() + "_count")
|
||||
|
||||
count := &model.Sample{
|
||||
Metric: model.Metric(lset),
|
||||
Value: model.SampleValue(m.Histogram.GetSampleCount()),
|
||||
Timestamp: timestamp,
|
||||
}
|
||||
samples = append(samples, count)
|
||||
|
||||
if !infSeen {
|
||||
// Append an infinity bucket sample.
|
||||
lset := make(model.LabelSet, len(m.Label)+2)
|
||||
for _, p := range m.Label {
|
||||
lset[model.LabelName(p.GetName())] = model.LabelValue(p.GetValue())
|
||||
}
|
||||
lset[model.LabelName(model.BucketLabel)] = model.LabelValue("+Inf")
|
||||
lset[model.MetricNameLabel] = model.LabelValue(f.GetName() + "_bucket")
|
||||
|
||||
samples = append(samples, &model.Sample{
|
||||
Metric: model.Metric(lset),
|
||||
Value: count.Value,
|
||||
Timestamp: timestamp,
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
return samples
|
||||
}
|
||||
88
watchdog/vendor/github.com/prometheus/common/expfmt/encode.go
generated
vendored
88
watchdog/vendor/github.com/prometheus/common/expfmt/encode.go
generated
vendored
@ -1,88 +0,0 @@
|
||||
// Copyright 2015 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
package expfmt
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"io"
|
||||
"net/http"
|
||||
|
||||
"github.com/golang/protobuf/proto"
|
||||
"github.com/matttproud/golang_protobuf_extensions/pbutil"
|
||||
"github.com/prometheus/common/internal/bitbucket.org/ww/goautoneg"
|
||||
|
||||
dto "github.com/prometheus/client_model/go"
|
||||
)
|
||||
|
||||
// Encoder types encode metric families into an underlying wire protocol.
|
||||
type Encoder interface {
|
||||
Encode(*dto.MetricFamily) error
|
||||
}
|
||||
|
||||
type encoder func(*dto.MetricFamily) error
|
||||
|
||||
func (e encoder) Encode(v *dto.MetricFamily) error {
|
||||
return e(v)
|
||||
}
|
||||
|
||||
// Negotiate returns the Content-Type based on the given Accept header.
|
||||
// If no appropriate accepted type is found, FmtText is returned.
|
||||
func Negotiate(h http.Header) Format {
|
||||
for _, ac := range goautoneg.ParseAccept(h.Get(hdrAccept)) {
|
||||
// Check for protocol buffer
|
||||
if ac.Type+"/"+ac.SubType == ProtoType && ac.Params["proto"] == ProtoProtocol {
|
||||
switch ac.Params["encoding"] {
|
||||
case "delimited":
|
||||
return FmtProtoDelim
|
||||
case "text":
|
||||
return FmtProtoText
|
||||
case "compact-text":
|
||||
return FmtProtoCompact
|
||||
}
|
||||
}
|
||||
// Check for text format.
|
||||
ver := ac.Params["version"]
|
||||
if ac.Type == "text" && ac.SubType == "plain" && (ver == TextVersion || ver == "") {
|
||||
return FmtText
|
||||
}
|
||||
}
|
||||
return FmtText
|
||||
}
|
||||
|
||||
// NewEncoder returns a new encoder based on content type negotiation.
|
||||
func NewEncoder(w io.Writer, format Format) Encoder {
|
||||
switch format {
|
||||
case FmtProtoDelim:
|
||||
return encoder(func(v *dto.MetricFamily) error {
|
||||
_, err := pbutil.WriteDelimited(w, v)
|
||||
return err
|
||||
})
|
||||
case FmtProtoCompact:
|
||||
return encoder(func(v *dto.MetricFamily) error {
|
||||
_, err := fmt.Fprintln(w, v.String())
|
||||
return err
|
||||
})
|
||||
case FmtProtoText:
|
||||
return encoder(func(v *dto.MetricFamily) error {
|
||||
_, err := fmt.Fprintln(w, proto.MarshalTextString(v))
|
||||
return err
|
||||
})
|
||||
case FmtText:
|
||||
return encoder(func(v *dto.MetricFamily) error {
|
||||
_, err := MetricFamilyToText(w, v)
|
||||
return err
|
||||
})
|
||||
}
|
||||
panic("expfmt.NewEncoder: unknown format")
|
||||
}
|
||||
38
watchdog/vendor/github.com/prometheus/common/expfmt/expfmt.go
generated
vendored
38
watchdog/vendor/github.com/prometheus/common/expfmt/expfmt.go
generated
vendored
@ -1,38 +0,0 @@
|
||||
// Copyright 2015 The Prometheus Authors
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
// Package expfmt contains tools for reading and writing Prometheus metrics.
|
||||
package expfmt
|
||||
|
||||
// Format specifies the HTTP content type of the different wire protocols.
|
||||
type Format string
|
||||
|
||||
// Constants to assemble the Content-Type values for the different wire protocols.
|
||||
const (
|
||||
TextVersion = "0.0.4"
|
||||
ProtoType = `application/vnd.google.protobuf`
|
||||
ProtoProtocol = `io.prometheus.client.MetricFamily`
|
||||
ProtoFmt = ProtoType + "; proto=" + ProtoProtocol + ";"
|
||||
|
||||
// The Content-Type values for the different wire protocols.
|
||||
FmtUnknown Format = `<unknown>`
|
||||
FmtText Format = `text/plain; version=` + TextVersion + `; charset=utf-8`
|
||||
FmtProtoDelim Format = ProtoFmt + ` encoding=delimited`
|
||||
FmtProtoText Format = ProtoFmt + ` encoding=text`
|
||||
FmtProtoCompact Format = ProtoFmt + ` encoding=compact-text`
|
||||
)
|
||||
|
||||
const (
|
||||
hdrContentType = "Content-Type"
|
||||
hdrAccept = "Accept"
|
||||
)
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user